









【spark sedona】apache sedona读取shp文件中文乱码问题
引言
Apache Sedona是一个专门处理空间矢量数据的Spark扩展,它可以读取、分析大量的矢量数据,依托于Spark的分布式计算能力,它的数据处理能力尤其是数据分析能力是PostGIS的若干倍(实测)。
我在使用Sedona本地单机读取shp文件的时候,发现所有的中文都成为了乱码,不管是照着官网的配置修改,还是上网查(网上资料很少),都没有一个解决方案。
最后的解决方案放在下面,希望能帮到你
一、问题复现
在本地单机读取
shp文件中的数据的时候,我按照 官网给出的示例 写,成功读取到了数据,但是数据中有中文字段的值都变成了乱码,就像这样:

部分代码(Java):
SparkSession sedona = SedonaContext.builder()
.master("local[*]")
.appName("test")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.kryo.registrator", SedonaVizKryoRegistrator.class.getName())
.getOrCreate();
SedonaContext.create(sedona);
SpatialRDD<Geometry> geomRDD = ShapefileReader.readToGeometryRDD(
JavaSparkContext.fromSparkContext(sedona.sparkContext()),shpPath);
Dataset<Row> df = Adapter.toDf(geomRDD, sedona);
df.show(1);
我上官网上查,官网上让我加上这个:
spark.driver.extraJavaOptions -Dsedona.global.charset=utf8
spark.executor.extraJavaOptions -Dsedona.global.charset=utf8
于是我按照官网上说的加上这个配置:
SparkSession sedona = SedonaContext.builder()
.master("local[*]")
.appName("test")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.kryo.registrator", SedonaVizKryoRegistrator.class.getName())
.config("spark.driver.extraJavaOptions", "-Dsedona.global.charset=utf8")
.config("spark.executor.extraJavaOptions", "-Dsedona.global.charset=utf8")
.getOrCreate();
重新运行,发现还是不行,中文部分依旧是乱码,于是我便上
GitHub上提了一个issue,官方给了回答,彻底解决了这个问题
二、问题解决
1、解决办法
首先将我提的这个
issue的地址贴出来,点击前往
访问不到的我把官方给出的回复贴出来:
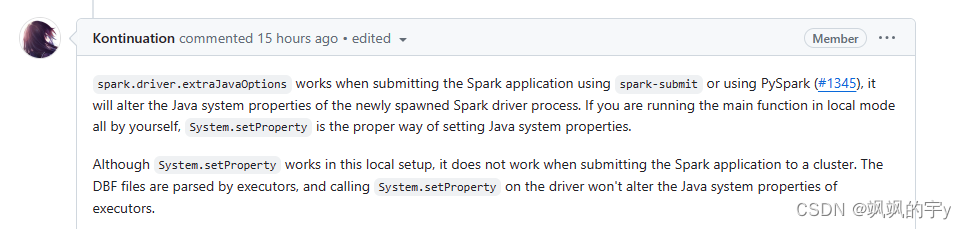
大概意思就是说:官网给的
spark.driver.extraJavaOptions -Dsedona.global.charset=utf8和spark.executor.extraJavaOptions -Dsedona.global.charset=utf8主要是用在集群中,在你spark-submit的时候加上去的参数,也就是说这两个配置是用在集群环境下的而非本地单机下的配置,如果是本地单机的字符编码,要使用System.setProperty。
于是我在代码上加入:
System.setProperty("sedona.global.charset","utf8");
乱码问题就解决了
如果是老版本,还没改名之前,也就是还叫
GeoSpark的时候,要用:
System.setProperty("geospark.global.charset","utf8");
2、注意
虽然
System.setProperty可以解决中文乱码的问题,但是仅限在本地单机的环境下使用,如果上了集群,那么它就会失效,这时还想解决中文乱码的问题,那么就得按照官网给的办法,加上这两个配置:
spark.driver.extraJavaOptions -Dsedona.global.charset=utf8
spark.executor.extraJavaOptions -Dsedona.global.charset=utf8
也就是在
spark-submit这个任务的时候,将这两个配置加上去,当然,你也可以加在代码中,在初始化SparkSession时就加上去:
SparkSession sedona = SedonaContext.builder()
.master("local[*]")
.appName("test")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.kryo.registrator", SedonaVizKryoRegistrator.class.getName())
.config("spark.driver.extraJavaOptions", "-Dsedona.global.charset=utf8")
.config("spark.executor.extraJavaOptions", "-Dsedona.global.charset=utf8")
.getOrCreate();
你也可以将这两个配置写到
Spark的配置文件中去,SPARK_HOME/conf/spark-defaults.conf这个文件中将这个配置写死也行
3、特别注意
***注意,spark.driver.extraJavaOptions -Dsedona.global.charset=utf8仅在Driver中生效,但是我们都知道,真正干活的是Executor,也就是读取数据的是Executor如果你只加了Driver的配置,那么你的中文还是会乱码。
所以
spark.driver.extraJavaOptions -Dsedona.global.charset=utf8和spark.executor.extraJavaOptions -Dsedona.global.charset=utf8都要加上,理论上只用加spark.executor.extraJavaOptions -Dsedona.global.charset=utf8就行了的,但是为了保险起见都加上吧
官网的配置并非不能正常使用,只是它没有说清楚环境。
结语
除了这个中文乱码的问题,我还有一个读取
shp文件的字段类型都是string的问题,但是与本问题无关,就写到另外一篇博客中了,感兴趣的请移步















 301
301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









