







HashTale与ConcurrentHashMap
-
Hashtable与ConcurrentHashMap都是线程安全的集合
-
Hashtable并发度低,整个Hashtable对应一把锁,同一时刻,只能有一个线程操作它
-
1.8之前ConcurrentHashMap使用了Segment+数组+链表的结构,每个Segment对应一把锁,如果多个线程访问不同的Segment,则不会冲突
-
1.8之后ConcurrentHashMap将数组的每个头节点作为锁,如果多个线程访问的头节点不同,则不会冲突
一、7的ConcurrentHashMap?
capacity:容量、factor:扩容因子、clevel:并发度
1)并发度
1.8之前ConcurrentHashMap使用了Segment+数组+链表的结构,每个Segment对应一把锁,并发度clevel就是Segment数组的容量(图中蓝色数组)。
每个Segment数组中存放数据个数:capacity/clevel,如果capacity <= clevel 那么存放数据个数默认为2(图中绿色数组)。
factor扩容因子是针对绿色数组的。

2)Segment索引计算

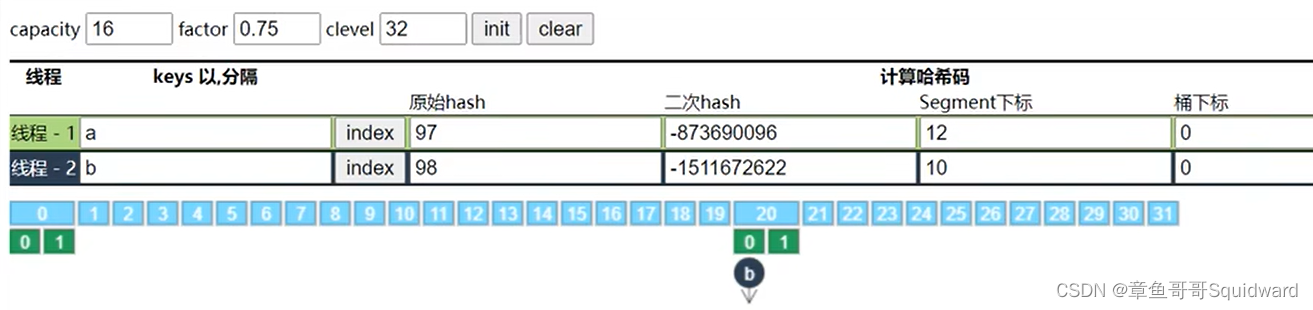
根据原始hash值,计算出二次hash值,根据Segment数组容量32->2^5,取二次hash值的高五位,来计算Segment下标
根据二次hash值的最低位来计算出桶下标
如下图:线程-1>>> 高四位(Segment下标):1100->12,最低位(桶下标):0

3)扩容
当超过( capacity/clevel )*factor时,扩容为原来的两倍,扩容操作在Segment数组中互不干扰
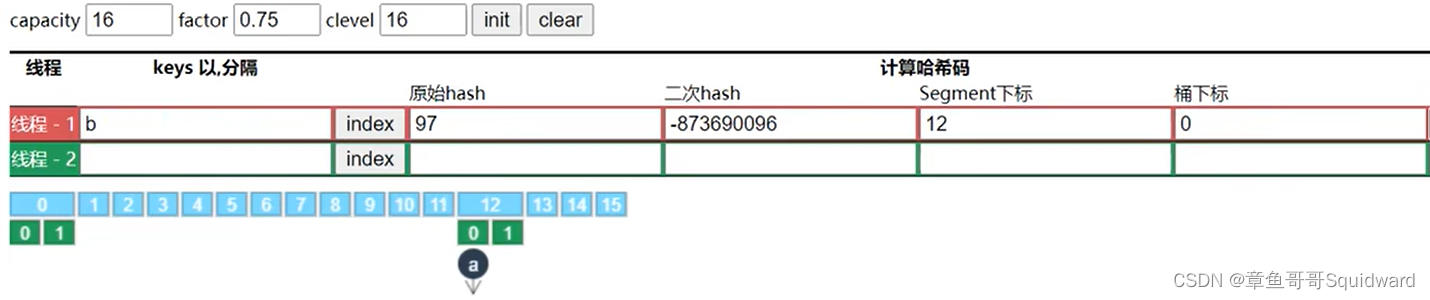
变化为
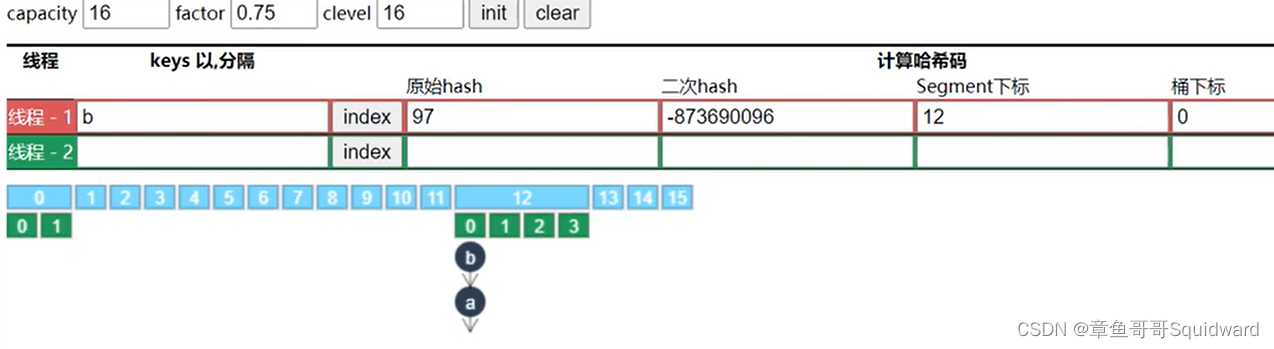
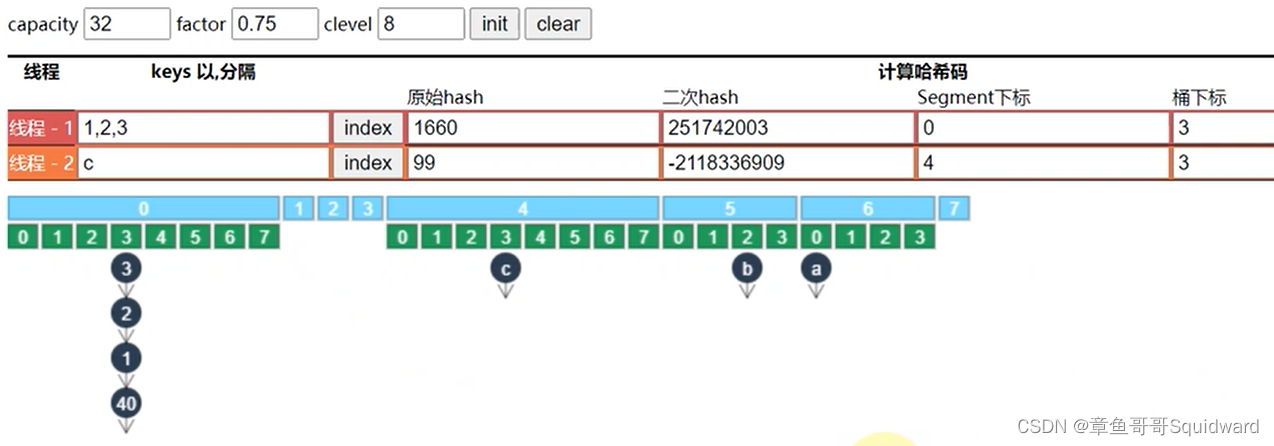
4)以Segment[0]为原型
每个Segment数组元素中的hashEntry小数组容量,以Segment[0]为原型来创建
(segment[0] 与 segment[4])
二、7与8的ConcurrentHashMap比较?
1)数据结构不同
7的ConcurrentHashMap使用的是Segment+数组+链表,而8版本使用的是数组+链表|红黑树
2)创建时间不同
7版本是饿汉式的初始化,而8版本是put数据时创建数组、是懒汉式的初始化
3)扩容时机不同
7版本是超过3/4(capacity/factor)进行扩容,而8版本是到达3/4(capacity/factor)时进行扩容
三、8的ConcurrentHashMap?
capacity:要存放数据的个数、factor:扩容因子(调用构造方法时才用到)
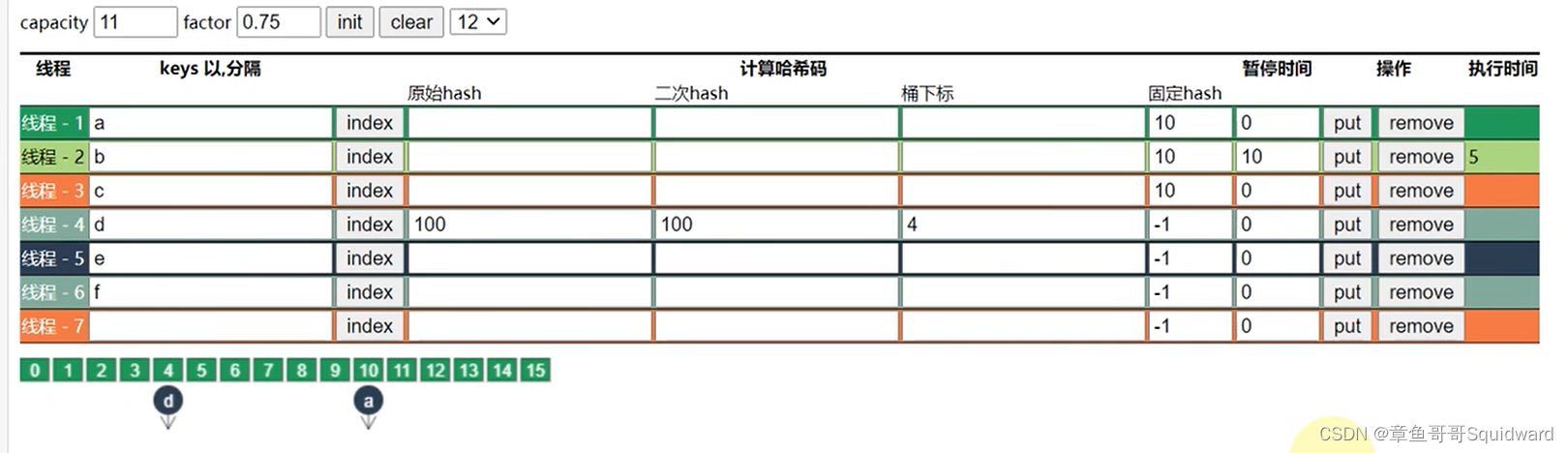
1)并发put
因为8版本的ConcurrentHashMap是在链表头上加锁,如果多个线程操作的是同一个索引,则会阻塞(线程-2 与 线程-3)。
设置线程-2暂停时间10s,线程-2与线程-3都往10索引下加入数据,因为线程-2先获得表头锁,所以当线程-2睡眠时,线程-3执行不了,会进入阻塞状态。

多个线程操作多个索引,因为锁加在每个索引的链表头部,所以操作不会阻塞,提升了并发性能(线程-2 与 线程-4)。
线程-2 虽然睡眠10s,但是线程-4操作的索引为4,两个线程之间不共用一把锁,操作不会阻塞。
2)扩容
容量到达3/4(capacity/factor)时进行扩容

细节:
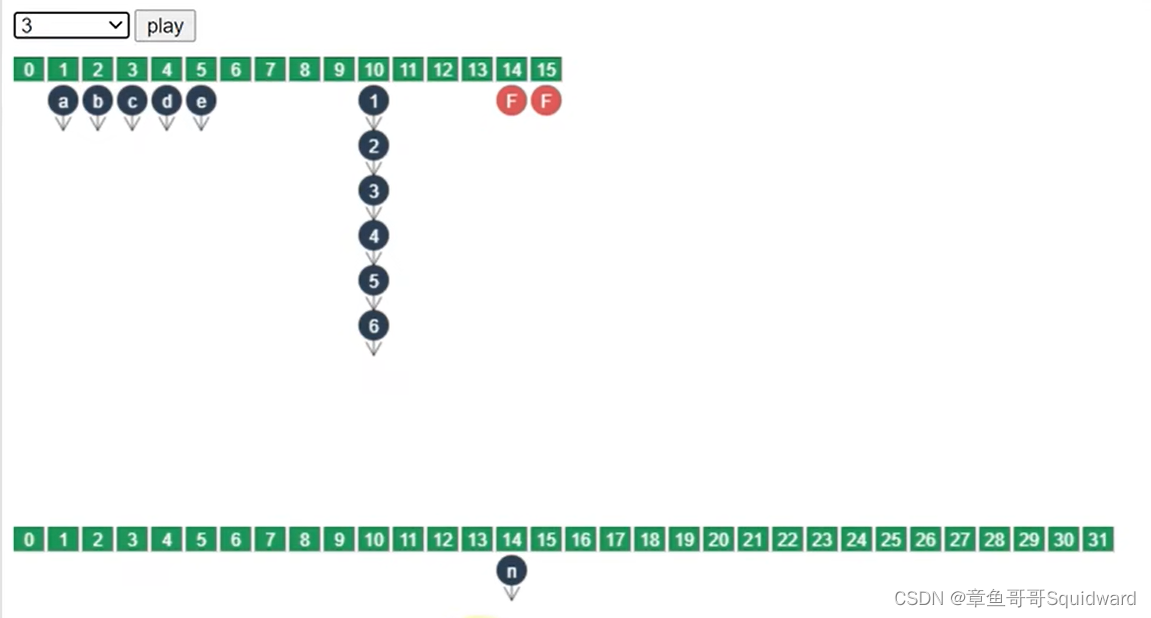
① 当扩容时其它线程进行get()操作:
当数组扩容时,会对已经扩容的索引位置标记。
1. 当其它线程进行get()操作时,首先会判断该索引位置是否已经被转移到另一个table中。如果已经被转移(链表头部被标记--图中F部分),则到新的table中查找,
2. 反之则在原来的table中进行查找。
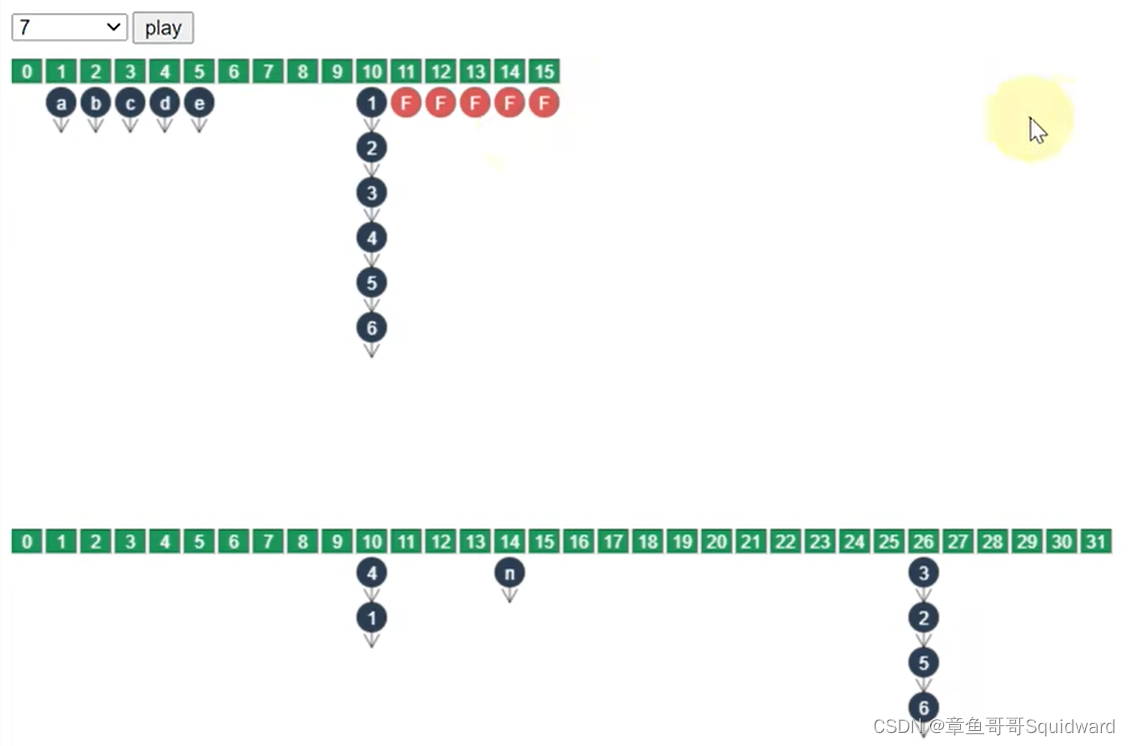
② 当扩容时其它线程进行put()操作:
当数组扩容时,会对已经扩容的索引位置标记。
当其它线程进行put()操作时,首先会判断该索引位置是否已经被转移到另一个table中。
1. 如果已经被转移,则不能进行put()操作,但是会帮忙分担前一部分的扩容工作。
例:要put的位置是11,则该put线程会帮助扩容线程执行0-5部分的扩容
2. 如果刚要被转移,由于扩容操作会在链表头部加上锁,所以put()操作阻塞。
例:要put的位置是10,由于扩容操作会在链表头部加上锁,所以put线程阻塞
3. 如果还没被转移,则可以并发执行put()操作。
例:要put的位置是5,可以执行
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









