






一 背景
本来做多目标检测MOT的流程,我自己总结一下是需要结合目标检测(一些候选框之类的)、目标跟踪(可以从时间建模去考虑跟踪的问题,还有时间关联分为外观和运动:外观方差通常通过成对Re-ID相似度测量,而运动则通过IoU或卡尔曼滤波启发式建模。这些方法需要基于相似度的匹配来进行后处理,这成为跨帧时间信息流的瓶颈)、目标关联等技术。
多对象跟踪。主流MOT方法主要遵循tracking-by-detection(TBD)范式。这些方法通常首先使用目标检测器来定位每帧中的目标,然后在相邻帧之间进行跟踪关联以生成跟踪结果。SORT结合卡尔曼滤波和匈牙利算法进行航迹关联。DeepSORT和Tracktor引入了额外的余弦距离,计算轨迹关联的外观相似度。Track-RCNN、JDE和FairMOT进一步在联合训练框架中,在目标检测器的基础上增加了一个Re-ID分支,将目标检测和Re-ID相结合。(原论文翻译出来的)
现有的多目标跟踪方法基本上都遵循tracking-by-detection(TBD)范式,它将轨迹的生成分为两个步骤:目标定位和时序关联。对目标定位而言,使用检测器逐帧检测目标即可。而对于时序关联,现有的方法要么使用空间相似性(即基于IoU关联)要么使用外观相似性(即基于ReID关联)。(该段摘抄自知乎的一篇有关MOTR的文章)
1.1 reid实现目标匹配
-
目标检测和识别:
- 首先,使用目标检测器检测图像或视频中的目标对象(如行人)并获取其边界框。
- 对每个边界框中的目标对象进行特征提取,例如,使用深度学习模型(如 CNN)从边界框中提取特征向量。
-
特征向量的表示:
- 将每个目标对象的特征向量表示为一个数学空间中的向量。这些向量捕获了目标对象的外观特征,通常是在特征空间中进行度量和比较。
-
相似性度量:
- 使用特定的相似性度量方法(如欧氏距离、余弦相似度等)来比较不同目标对象的特征向量。较为相似的特征向量将具有较小的距离或者较高的相似度分数。
-
关联和跟踪:
- 在相邻帧中,对新检测到的目标对象进行特征提取,并与先前帧中已知目标对象的特征向量进行相似性度量。
- 根据相似性度量的结果,将新检测到的目标对象关联到之前的目标中。通常选择相似性最高(距离最小、相似度最高)的目标作为关联目标。
-
更新和维护跟踪器:
- 根据关联结果,更新目标的状态信息,如位置、速度、运动模型等。
- 可以使用滤波器(如卡尔曼滤波)进行状态的预测和更新
1.2 基于IoU关联实现目标匹配
空间相似性(基于 IoU,Intersection over Union)通常用于目标跟踪中的匹配和关联。这种方法的基本思想是利用物体边界框之间的重叠程度(IoU)来衡量它们之间的相似性,然后根据相似性进行匹配。
以下是一个简单的目标跟踪流程,其中使用 IoU 进行目标匹配:
-
检测阶段:
- 对于每一帧图像,使用物体检测器(如 YOLO、SSD、Faster R-CNN 等)来检测物体,获取每个物体的边界框(Bounding Box)和对应的类别标签。
-
特征提取:
- 对于每个检测到的物体边界框,提取一些特征向量或特征描述符,可以是基于外观、运动、或者语义的特征,以便于后续的相似性比较。
-
目标关联:
- 在下一帧中,执行新一轮的检测,并获取新的边界框。
- 对于每个新的边界框,计算它与上一帧中已知目标边界框之间的 IoU 值。通常,如果 IoU 值大于设定的阈值(比如 0.5),可以将新的边界框与先前帧中的某个目标边界框进行关联。
- 可以使用多种算法进行匹配,如匈牙利算法、卡尔曼滤波、最近邻匹配等,来根据 IoU 值将边界框进行关联。
-
更新跟踪结果:
- 根据关联结果,更新跟踪器的状态信息,包括位置、速度、运动模型等。
- 可以使用相关滤波器(如卡尔曼滤波)来预测目标的位置并估计目标状态。
需要注意的是,IoU 只是目标匹配的一种方法,适用于目标边界框之间的重叠情况。在实际应用中,目标跟踪可能需要结合多种方法和技术,比如运动预测、外观特征、上下文信息等,以提高跟踪的准确性和鲁棒性。
1.3 DETR
介绍一下DETR这个框架,DETR把transformer,cnn和二部匹配结合在一起,实现端到端(GPT牛波一)的目标检测。为了实现快速收敛,然后Deformable DETR在Transformer编码器和Transformer解码器中引入了deformable attention module。(这个模块下面会解释)

这里,我们把目标跟踪等效为序列预测问题。预测每个object的轨迹。
1.3.1 object query
DETR引入了一组固定长度的object query来检测对象,object query被馈送到Transformer解码器中,并与从Transformer编码器中提取的图像特征交互,以更新它们的表示。
进一步采用二部匹配,实现更新后的对象查询与真值之间的一对一赋值。这里,我们简单地将对象查询写成“detect query”,以指定用于对象检测的查询。
DETR中的detect query(实际就是object query,这篇文章不知道为什么写到中间就把这个叫法给改了)用于检测新生对象(T2处的对象3)。检测到的对象的隐藏状态产生下一帧的轨迹查询;分配给终止对象的轨道查询从轨道查询集(T4处的对象2)中删除。
目标匹配(精确到ID级别)在DETR中,一个object query可以分配给图像中的任何object ,因为标签分配是通过在所有object query和ground truth之间执行二部匹配来确定的。(这里可以看出来不是端到端的,还得人工设计一个匹配方法,MOTR直接就是端到端的,检测查询仅用于检测新生对象,而track query预测所有跟踪对象。)
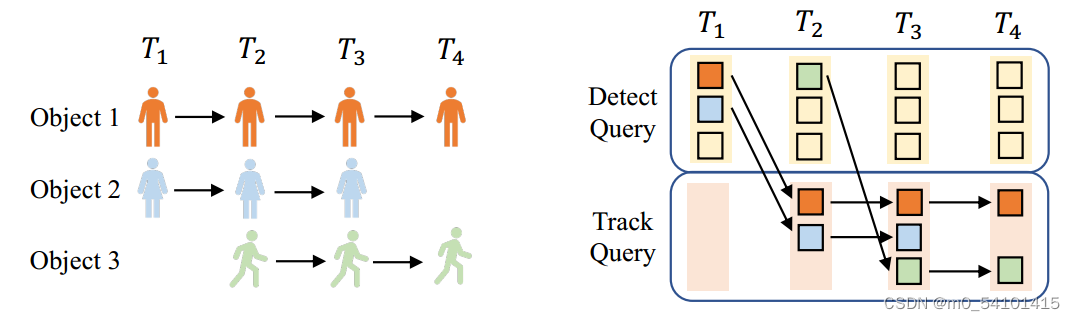
这个图很明显看得出来,obj Q(固定长度)只有当前的状态,而tra Q(初始化为空,动态长度)有时序上的信息。
1.3.2 TALA
Tracklet-Aware Label Assignment(TALA)实现两个query和object的匹配问题。也就是说这个模块实际在DETR和MOTR中都存在。
For detect queries, we modify the assignment strategy in DETR as newborn-only, where bipartite matching is conducted between the detect queries and the ground-truths of newborn objects.(目标检测出新的object,然后再做 ID 级别的匹配)
For track queries, we design an target-consistent assignment strategy. Track queries follow the same assignment of previous frames and are therefore excluded from the aforementioned bipartite matching.(跨帧实现同ID级别追踪)在实践中,由于Transformer中强大的注意机制,TALA策略简单有效。对于每一帧,object query和track query被连接并馈送到Transformer解码器以更新它们的表示。object query将只检测newborn object(since query interaction QIM by self-attention in the Transformer decoder will suppress detect queries that detect tracked objects.)。这个机制类似于DETR中的重复删除,重复的对象边界框(bounding box)在分数低的情况下被抑制。
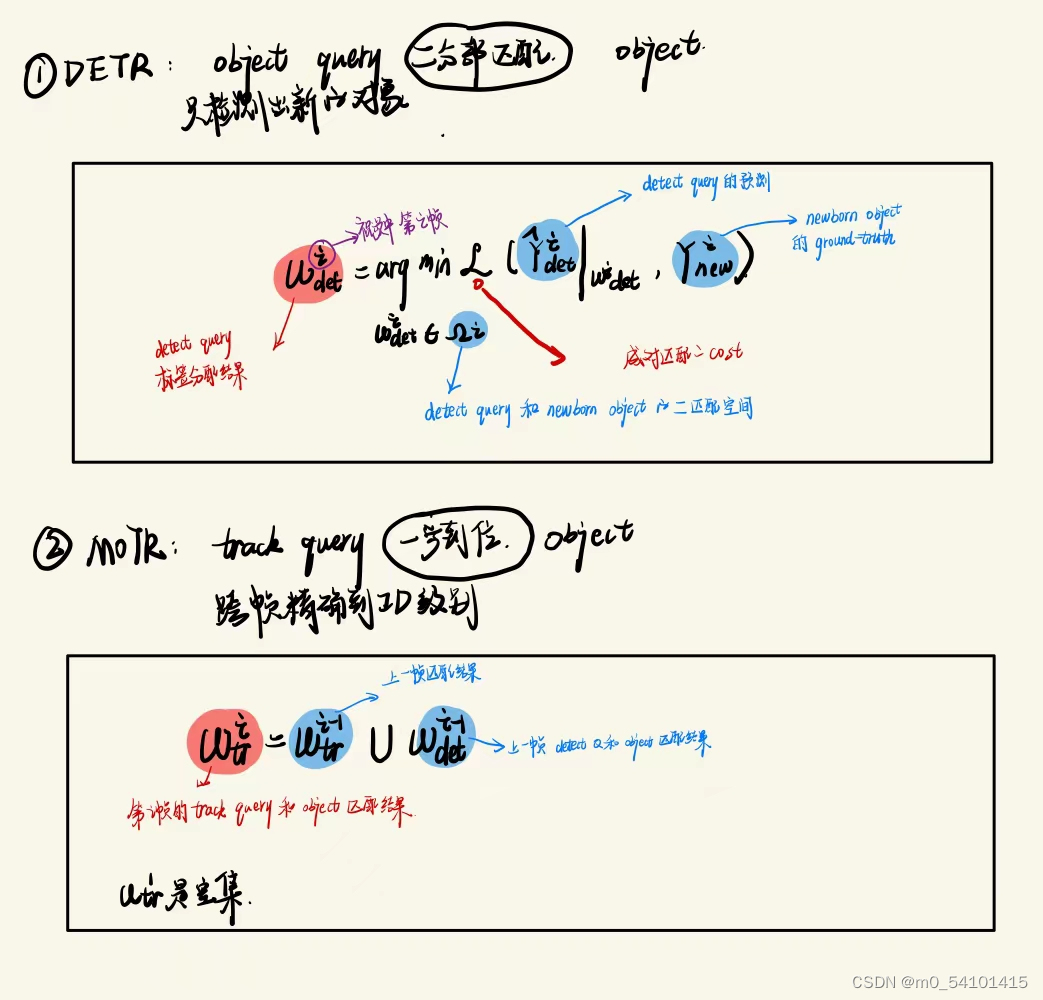
按照原文理出来的公式写了一下,MOTR的贡献在于跨帧直接实现ID级别的追踪
二 MOTR
2.1整体框架
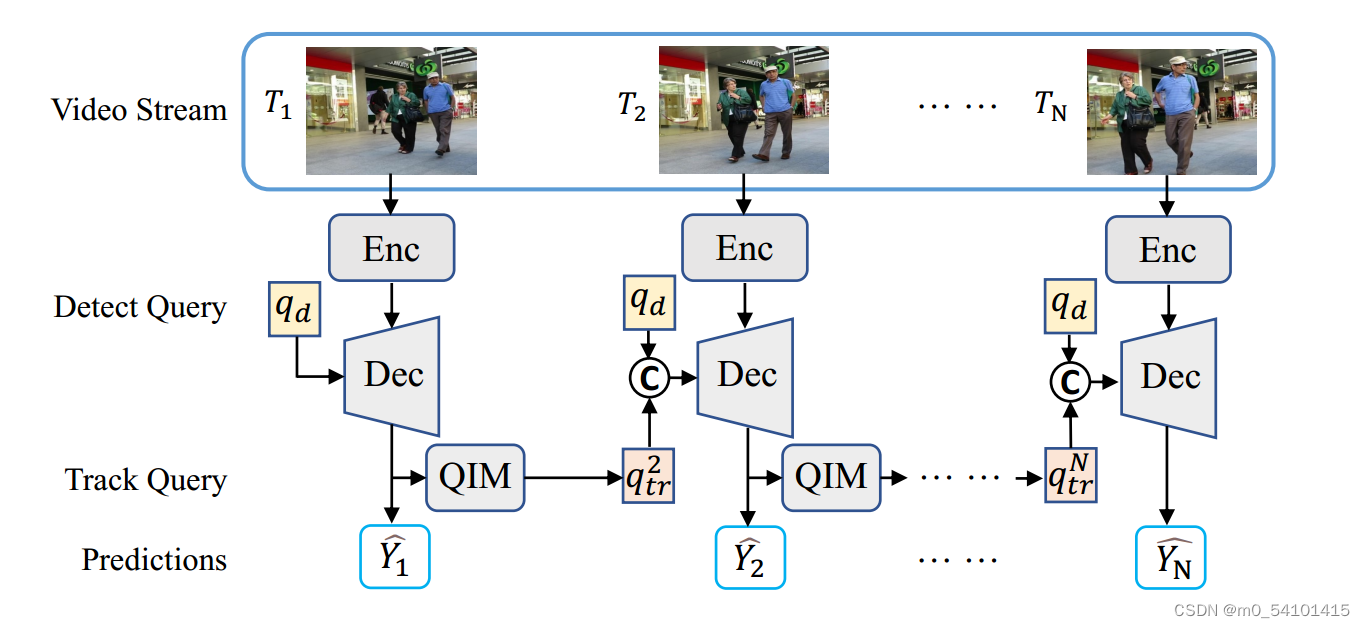
①Enc代表一个卷积神经网络骨干和Transformer编码器,它为每一帧提取图像特征。
②检测查询qd和跟踪查询qtr的连接被输入到可变形的DETR解码器(Dec)中以产生隐藏状态。隐藏状态用于生成新对象和跟踪对象的预测Y值。
③查询交互模块(QIM)将隐藏状态作为输入,并为下一帧生成轨迹查询。
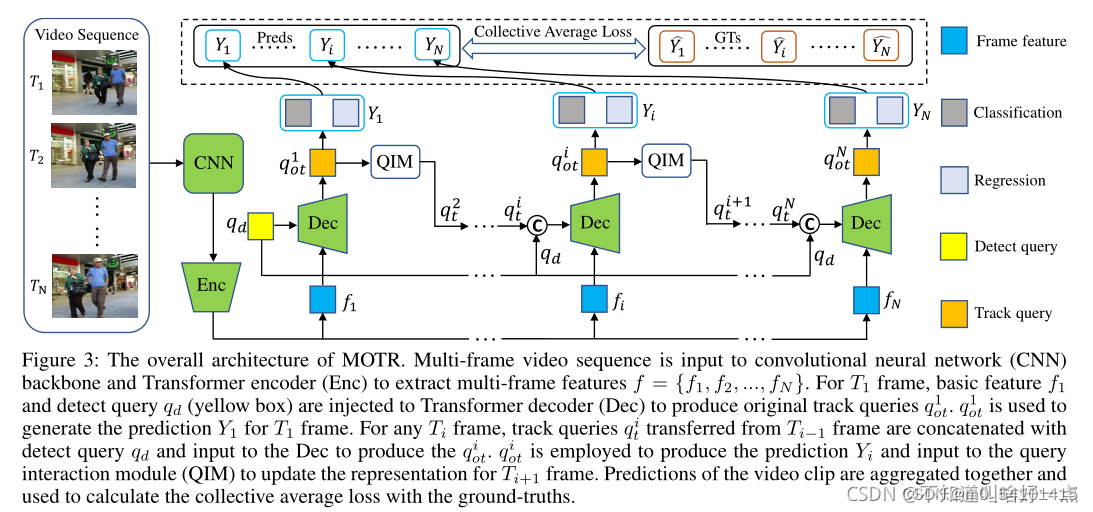
多帧串行处理。视频序列传进CNN(这里用的是resnet50),再输入encoder,得到Multi-frame feature(可能包括空间、时间上的一些特征),detect query和特征f进入decoder,生成track query,track query一边通过FFN,得到预测Y,一边经过QIM模块,生成下一帧的track query,实现迭代预测。下面是别的博主整理出来的流程。

2.2 QIM
query Interaction module(QIM) 。QIM包括对象进出机制(Object Entrance and Exit).和时间聚合网络(TAN)
2.2.1 Object Entrance and Exit.

QIM的输入是Transformer解码器产生的隐藏状态和相应的预测分数。对于任何帧,track query都与detect query 和Transformer解码器的输入相连接,从而产生隐藏状态。
在训练过程中,如果匹配对象在ground-truth中消失或预测边界框与目标之间的LOU(intersection-over-union, IoU)小于0.5阈值,则删除终止对象的隐藏状态。
这意味着如果这些对象在当前帧消失,相应的隐藏状态将被过滤,而其余的隐藏状态将被保留。对于新生物体,根据公式中定义的newborn object 的赋值,保持相应的隐藏状态。
2.2.2 TAN
TAN的输入为被跟踪对象(对象“1”)经过滤波后的隐藏状态。我们还从最后一帧收集轨道查询q i tr用于时间聚合。TAN是一个改进的Transformer解码器层。总结了最后一帧的轨道查询和过滤后的隐藏状态作为多头自注意(MHA)的关键和查询组件。
2.3 CAL
Collective Average Loss。MOTR以视频片段作为输入。这样就可以生成远距离物体运动的训练样本进行时间学习。更好进行时间建模。
多帧计算总损失。


Y^是预测,Y是ground truth。L是loss,比如Lcls是focal loss,Ll1是L1loss,Lgiou是generalized IoU loss,是各自的权系数。这应该是代码里面的混合loss吧。
V是object的个数。















 1850
1850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









