






作业一及答案
一. 单选题(共5题)
1. (单选题)【单选题】进行数据仓库构建的过程中需要使用到ETL技术,那么ETL具体指的是( )
A. 转换和清洗,抽取,加载
B. 抽取,转换和清洗,加载
C. 转换和清洗,加载,抽取
D. 抽取,加载,转换和清洗
正确答案: B:抽取,转换和清洗,加载;
2. (单选题)【单选题】下列哪些属于Hive的数据模型( )
A. 视图、托管表、外部表、桶表、分区表
B. 二维表、关系表、Excel表、CVS表
C. 桶表、分区表、二维表、关系表
D. Excel表、CVS表、视图、托管表、外部表
正确答案: A:视图、托管表、外部表、桶表、分区表;
3. (单选题)【单选题】在有关数据仓库测试,下列说法不正确的是 ( )。
A. 在完成数据仓库的实施过程中,需要对数据仓库进行各种测试。测试工作中要包括单元测试和系统测试。
B. 系统的集成测试需要对数据仓库的所有组件进行大量的功能测试和回归测试。
C. 在测试之前没必要制定详细的测试计划。
D. 当数据仓库的每个单独组件完成后,就需要对他们进行单元测试。
正确答案: C:在测试之前没必要制定详细的测试计划。;
4. (单选题)【单选题】数据仓库是随着时间变化的,下面的描述不正确的是( )
A. 捕捉到的新数据会覆盖原来的快照
B. 数据仓库随时间的变化不断增加新的数据内容
C. 数据仓库随事件变化不断删去旧的数据内容
D. 数据仓库中包含大量的综合数据,这些综合数据会随着时间的变化不断地进行重新综合
正确答案: C:数据仓库随事件变化不断删去旧的数据内容;
5. (单选题)【单选题】有关数据仓库的开发特点,不正确的描述是( )。
A. 数据仓库开发要从数据出发
B. 数据仓库使用的需求在开发初期就要明确
C. 在数据仓库环境中,并不存在操作型环境中所固定的和较确切的处理流,数据仓库中数据分析和处理更灵活,且没有固定的模式
D. 数据仓库的开发是一个不断循环的过程,是启发式的开发
正确答案: A:数据仓库开发要从数据出发;
二. 判断题(共5题)
6. (判断题)【判断题】数据仓库的数据量越大,其应用价值也越大。
A. 对
B. 错
正确答案: 错
7. (判断题)【判断题】数据仓库和数据库是完全不相关的两种技术。
A. 对
B. 错
正确答案: 错
8. (判断题)【判断题】数据仓库“粒度”越细,记录越少。
A. 对
B. 错
正确答案: 错
9. (判断题)【判断题】数据仓库是面向主题的、集成的、稳定的、随时间变化的数据集合,用以支持管理决策的过程。
A. 对
B. 错
正确答案: 对
10. (判断题)【判断题】数据仓库跟数据库的功能一样,只不数据量要大于数据库。
A. 对
B. 错
正确答案: 错
三. 简答题(共8题)
11. (简答题)【简答题】数据转换、清洗结束后,需要把数据装载到数据仓库中,数据的装载有三种方式。
正确答案:分别是初始装载、增量装载、完全刷新。
12. (简答题)【简答题】请以学校图书管理为例,支持学校教务处根据统计出来大一借阅最多的书籍类型,购买更多相关类型书籍,以方便学生借阅书籍解释。解释其中技术层、功能层、组织层的主要功能和内容。
正确答案:
业务层:学校图书管理系统,选取大一部分学校图书管理系统中学生借阅书籍信息,把借阅的书籍归类、筛选,加载至新的数据仓库。
技术层:负责对来自业务层的原始数据进行抽取、转换、加载等加工,并把处理好的数据放入数据仓库以及利用数据集成服务将数据进行实时存储。我们可以抽取部分学校图书管理系统中学生借阅书籍信息,把属于大一的学生借阅的书籍加载至新的数据仓库。
功能层:将技术层处理好的数据进行分析,以辅助运营和决策支持,并得到模型库、知识库,例如:分析抽取属于大一学生借阅情况,哪类书籍学生是借阅最多的。
组织层:功能层得到的数据分析结果、各种知识信息等,把借阅数据类型最多的提交给学校教务处。
战略层:在以上4层的支撑下,实施战略计划,学校教务处根据统计出来借阅最多的书籍类型,购买更多相关类型书籍,以方便学生借阅书籍。
13. (简答题)【简答题】数据库是数据仓库的基础,数据库是为了捕获数据而设计的,而数据仓库是为了分析数据而设计的,是在数据库已经大量存在的情况下,为了进一步发现数据资源,为了支持决策而产生,它并不是所谓的“大型数据库”,数据仓库并不能取代数据库而独立存在。请你回答三点数据库与数据仓库的区别。
正确答案:
(1)数据内容:数据库一般存储在线交易数据,数据仓库存储的一般是历史数据。
(2)数据目标:数据库是为捕获数据而设计,面向业务操作程序,重复处理;数据仓库是为分析数据而设计,面向主题域、管理决策分析应用。
(3)数据特性:数据库主要由原子事物组成,数据更新频繁,需要并行控制和恢复机制。而数据仓库往往处理的是复杂的数据查询,大部分是只读操作,不能直接更新、只定时添加。
(4)数据结构:数据库中的建模一般遵循三范式,是高度结构化、复杂、适合操作计算的数据,而数据仓库的建模有特定的方式,一般采用维度建模,数据结构比较简单,可以提高查询效率,适合统计分析。
(5)数据规模:数据仓库中的数据通常来源于多个不同的联机事物处理系统数据库(存储多年的数据),数据量远远大于操作型数据库,一般作为企业数据中心用。
(6)使用频率:数据库存储的是联机事务处理的操作数据,通常联机事务处理每时每刻都在进行着对数据的读写,对数据的使用频率较高。而数据仓库是为分析型系统提供数据支持,一般是企业管理层或者决策者需要,使用频率较低。
(7)设计方式:数据库设计是尽量避免冗余,一般采用符合范式的规则来设计,数据仓库在设计是有意引入冗余,采用反范式的方式来设计。
(8)处理性能:联机事务处理系统涉及频繁、简单的数据存取,因此对数据库的性能要求较高,需要数据库在短时间内做出响应,而分析型系统对响应的时间要求不是那么苛刻,有的分析甚至可能需要几个小时。
任选三点即可。
14. (简答题)【简答题】数据仓库的数据通常来源于多个异构的数据库,因此源数据在加载到数据仓库之前,需要对数据进行一定的数据转换,以保证数据的一致性。下面请你说说这三个数据转换。
正确答案:
(1)不一致数据的转换;
(2)数据粒度的转换;
(3)商务规则的计算。
15. (简答题)【简答题】张三打算设计一个商务智能的系统,请你跟他解释一下商务智能基本需求。
正确答案:
商务智能系统必须是信息易于访问,且内容也必须是可以理解的。数据须对业务用户来说是直观和明显的,而不仅仅只考虑到开发人员。数据的结构和标签以及词汇应该模仿业务用户的思维过程。业务用户通常会希望将分析数据分离并进行无限制的组合,访问数据的业务智能工具和应用程序必须简单易用,且必须以最少的等待时间将查询结果返回给用户。
16. (简答题, 2)【程序阅读题】请解释如下Hive每条语句的含义。
1)create database dblab;
2)use dblab;
3)create external table dblab.bigdata_user(id int,uid string,item_id string,behavior_type int,item_category string,visit_date date,province string) comment'Welcome to xmu dblab!' row format delimited fields terminated by '\t' stored as textfile location '/bigdata/dataset'
4)show tables;
5)select * from bigdata_user limit 10;
6)desc bigdata_user;
7)select visit_date,item_category from bigdata_user limit 20;
8)select count(distinct uid) from bigdata_user;
9)select count(*) from bigdata_user where province='江西' and visit_date='2014-12-12' and behavior_type='4';
10)select uid from bigdata_user where behavior_type='4' and visit_date='2014-12-12' group by uid having count(behavior_type='4')>5;
说明:id为序号,uid为用户号,behavior_type为用户行为,'4'表示用户进行了购买行为,item_category为商品类别,visit_date为访问日期,province为省。
正确答案:
1) 在Hive中创建一个数据库dblab
2) 进入数据库dblab
3) 创建一个外部表bigdata_user,它包含字段(id, uid, item_id, behavior_type, item_category, date, province)
4) 查询表格,看看bigdata_user是否已经创建成功
5) 查询前10位数据记录
6) 查看bigdata_user的表结构
7) 查询前20位用户购买商品时的时间和商品的种类
8) 查出uid不重复的数据有多少条
9) 给定时间'2014-12-12',给定地点'江西',给定购买行为,整个数据有多少条
10) 给定购买商品的数量范围,查询给定时间'2014-12-12',并且购买行为超过5次的用户uid
17. (简答题)【简答题】下图是领域概念建模阶段我们运用了实体建模法:
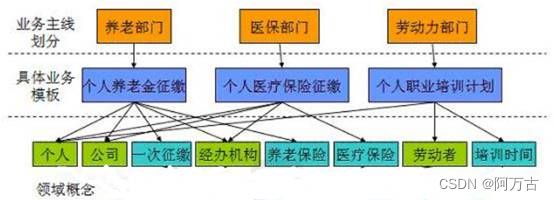
在领域概念里,属于实体、事件和说明的对象分别有哪些?
例如:实体:个人。
正确答案:
(1)实体:个人、公司、经办机构、养老保险、医疗保险和劳动者;
(2)事件:一次征缴
(3)说明:培训时间
18. (简答题)【简答题】数据处理常规处理分为四个步骤,请说明四个步骤的含义。
正确答案:
(1)数据清理:数据清理例程通过填写缺失的值、光滑噪声数据、识别或删除离群点并解决不一致性来“清理”数据。主要是达到如下目标:格式标准化,异常数据清除,错误纠正,重复数据的清除。
(2)数据集成:数据集成例程将多个数据源中的数据结合起来并[统一存储],建立数据仓库的过程实际上就是数据集成。
(3)数据变换:通过平滑聚集,数据概化,规范化等方式将数据转换成适用于数据挖掘的形式。
(4)数据归约:数据挖掘时往往数据量非常大,在少量数据上进行挖掘分析需要很长的时间,数据归约技术可以用来得到数据集的归约表示,它小得多,但仍然接近于保持原数据的完整性,并结果与归约前结果相同或几乎相同。















 7313
7313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









