







以该问题为例
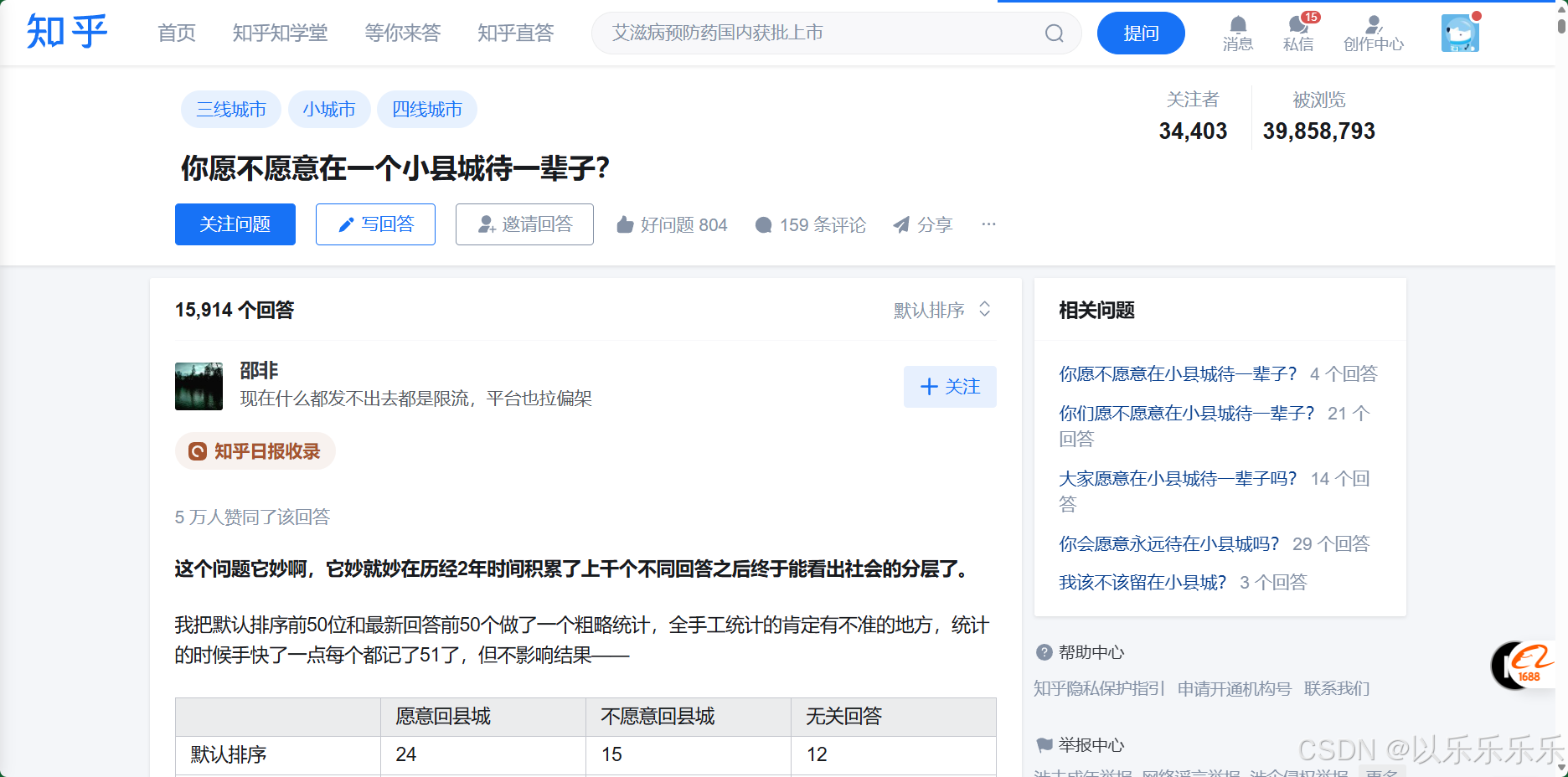
问题地址为:(15 封私信) 你愿不愿意在一个小县城待一辈子? - 知乎
可以看到这个问题下面有15914个回答,由于知乎接口限制,是不可能把这些全部都爬下来的,根据博主测试最多就只能爬2k多个回答,多了就限制了。
首先接口地址是在知乎滚动加载时发现
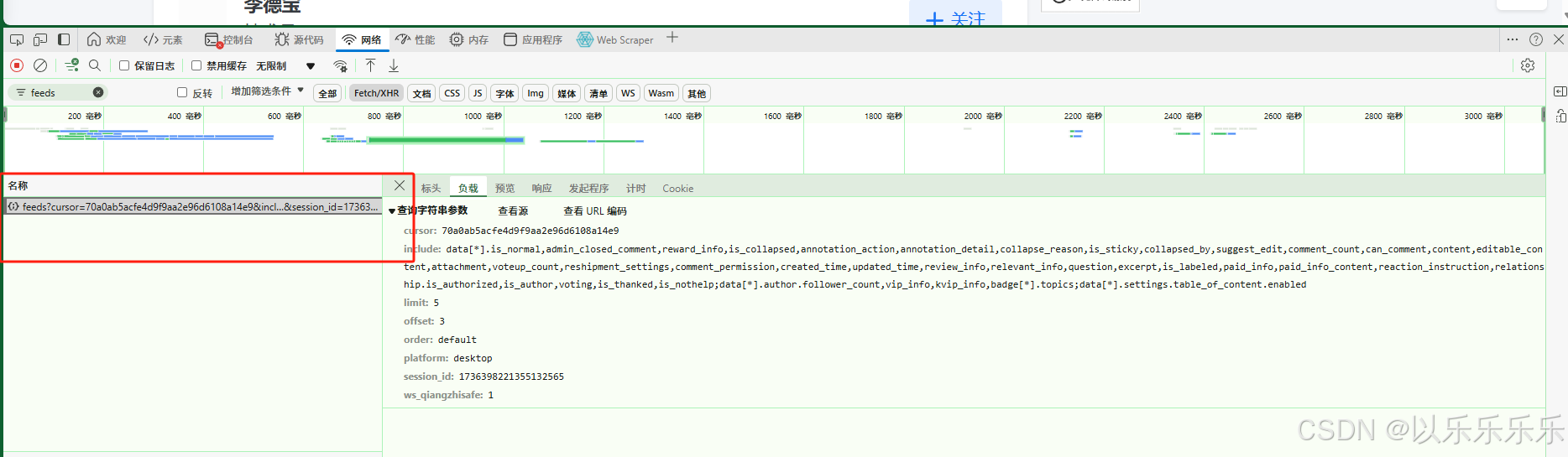
这个接口请求出来就是我们所需要的回答内容了
# 目标API的URL
url = "https://www.zhihu.com/api/v4/questions/417662243/feeds"
# 初始请求参数设置,后续第一次请求会用到,后续请求可能根据返回数据中的链接来进行,但先保留此参数格式
params = {
"include": "data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,attachment,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,is_labeled,paid_info,paid_info_content,reaction_instruction,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp;data[*].author.follower_count,vip_info,kvip_info,badge[*].topics;data[*].settings.table_of_content.enabled",
"limit": 10,
"offset": 0,
"order": "default",
"ws_qiangzhisafe": 1
}这是我们的初始参数,limit是指的每次请求可以返回的回答条数,offset是跟页面有关的参数,order指的是排序方式,默认和按照最新排序两种。
由于直接更改offset并不能达成翻页的效果,所以需要通过第一次请求返回的接口内容来获得下一页的内容请求接口,继而完成持续爬取的目的。
源代码如下,cookie和url的文章ID需要自己进行更换
import requests
import time
from datetime import datetime
from bs4 import BeautifulSoup
import pandas as pd
# 目标API的URL
url = "https://www.zhihu.com/api/v4/questions/417662243/feeds"
# 初始请求参数设置,后续第一次请求会用到,后续请求可能根据返回数据中的链接来进行,但先保留此参数格式
params = {
"include": "data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,attachment,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,is_labeled,paid_info,paid_info_content,reaction_instruction,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp;data[*].author.follower_count,vip_info,kvip_info,badge[*].topics;data[*].settings.table_of_content.enabled",
"limit": 10,
"offset": 0,
"order": "default",
"ws_qiangzhisafe": 1
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
}
# 从文件中读取Cookie信息,假设文件名为cookie.txt,每行一个Cookie键值对
cookies = {}
with open("cookie.txt", "r") as f:
for line in f.readlines():
key, value = line.strip().split("=", 1)
cookies[key] = value
# 用于存储所有请求获取到的数据
all_data = []
next_url = url # 初始化为第一次请求的URL
first_request = True # 标记是否为第一次请求
while next_url:
try:
if first_request:
# 第一次请求使用原有的请求方式,带上params参数
print(f"第1次请求,请求地址:{url}")
response = requests.get(url, params=params, headers=headers, cookies=cookies)
first_request = False
else:
# 非第一次请求,按照返回数据中的链接进行请求
print(f"请求地址:{next_url}")
response = requests.get(next_url, headers=headers, cookies=cookies)
if response.status_code == 200:
data = response.json()
new_data = data['data']
if len(new_data) == 0: # 添加判断,如果本次获取到的数据长度为0,则停止请求
print("本次获取数据长度为0,停止请求")
break
all_data.extend(new_data)
print(f"请求成功,已获取{len(all_data)}条数据")
# 提取每条回答对应的相关数据并整合为DataFrame
extracted_data_list = []
for item in data['data']:
target = item.get('target') # 使用get方法获取target字段,避免不存在时报错
if target:
author_name = target.get('author', {}).get('name', '无值') # 若对应字段不存在则标注为无值
# 清洗HTML内容并去除空白行
content = target.get('content', '无值')
soup = BeautifulSoup(content, 'html.parser')
text_content = soup.get_text(separator='\n')
lines = text_content.splitlines()
cleaned_lines = [line.strip() for line in lines if line.strip()]
cleaned_content = '\n'.join(cleaned_lines)
comment_count = target.get('comment_count', '无值')
# 将时间戳转换为标准时间格式,若时间戳不存在则标注为默认时间格式的无值
timestamp = target.get('created_time', 0)
created_time = datetime.fromtimestamp(timestamp).strftime('%Y-%m-%d %H:%M:%S') if timestamp else '无值'
voteup_count = target.get('voteup_count', '无值')
extracted_data_list.append({
"作者名称": author_name,
"回答内容": cleaned_content,
"评论数": comment_count,
"回答时间": created_time,
"赞同数": voteup_count
})
df = pd.DataFrame(extracted_data_list)
# 保存为CSV文件,文件名按照请求次数编号,指定中文编码为utf-8-sig避免乱码,并创建对应的文件夹用于存放文件
df.to_csv(f"./知乎回答/zhihu_data_{len(all_data)}.csv", index=False, encoding='utf-8-sig')
# 获取下一次请求的链接,如果不存在则循环结束
next_url = data.get('paging', {}).get('next', None)
print(next_url)
else:
print(f"请求失败,状态码: {response.status_code}")
print("等待10分钟后重新尝试...")
time.sleep(60) # 等待1分钟(60秒)
continue # 继续从当前循环处尝试
# 每次请求后暂停5秒钟,模拟正常用户操作间隔,避免频繁请求
time.sleep(1)
except requests.RequestException as e:
print(f"请求发生异常: {e}")
print("等待10分钟后重新尝试...")
time.sleep(60) # 等待1分钟(60秒)
continue # 继续从当前循环处尝试
print("所有请求完成,共获取到", len(all_data), "条数据")
















 433
433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









