







 文章详细解读注意力机制及其在Transformer中的应用,包括自注意力机制和多头注意力,适合深度学习和自然语言处理读者。
文章详细解读注意力机制及其在Transformer中的应用,包括自注意力机制和多头注意力,适合深度学习和自然语言处理读者。
本文参考了b站博主蘅芜仙菌的视频以及文章Transformer:注意力机制(attention)和自注意力机制(self-attention)的学习总结
如有侵权,联系删除。
注意力机制其实是源自于人对于外部信息的处理能力。由于人每一时刻接受的信息都是无比的庞大且复杂,远远超过人脑的处理能力,因此人在处理信息的时候,会将注意力放在需要关注的信息上,对于其他无关的外部信息进行过滤,这种处理方式被称为注意力机制。
针对于注意力机制的引起方式,可以分为两类,一种是非自主提示,另一种是自主提示。其中非自主提示指的是由于物体本身的特征十分突出引起的注意力倾向,自主提示指的是经过先验知识的介入下,对具有先验权重的物体引起的注意力倾向。换句话说,可以理解为非自主提示源自于物体本身,而自主提示源自于一种主观倾向。
一、注意力机制
Self-Attention是个啥,自己注意自己?Q、K、V又是什么?为什么它们要叫query、key、value,它们有啥关系?
先来看一个问题,假设我们现在有一个键值对(Python字典),如下图所示。现在我给出一个人的腰围为57,想要预测其体重。自然地,我们推断其体重在43~48之间,但是我们还需要定量计算体重预测值,由于57到56、58的距离一样,所以一种方法是取它们对应体重的平均值。
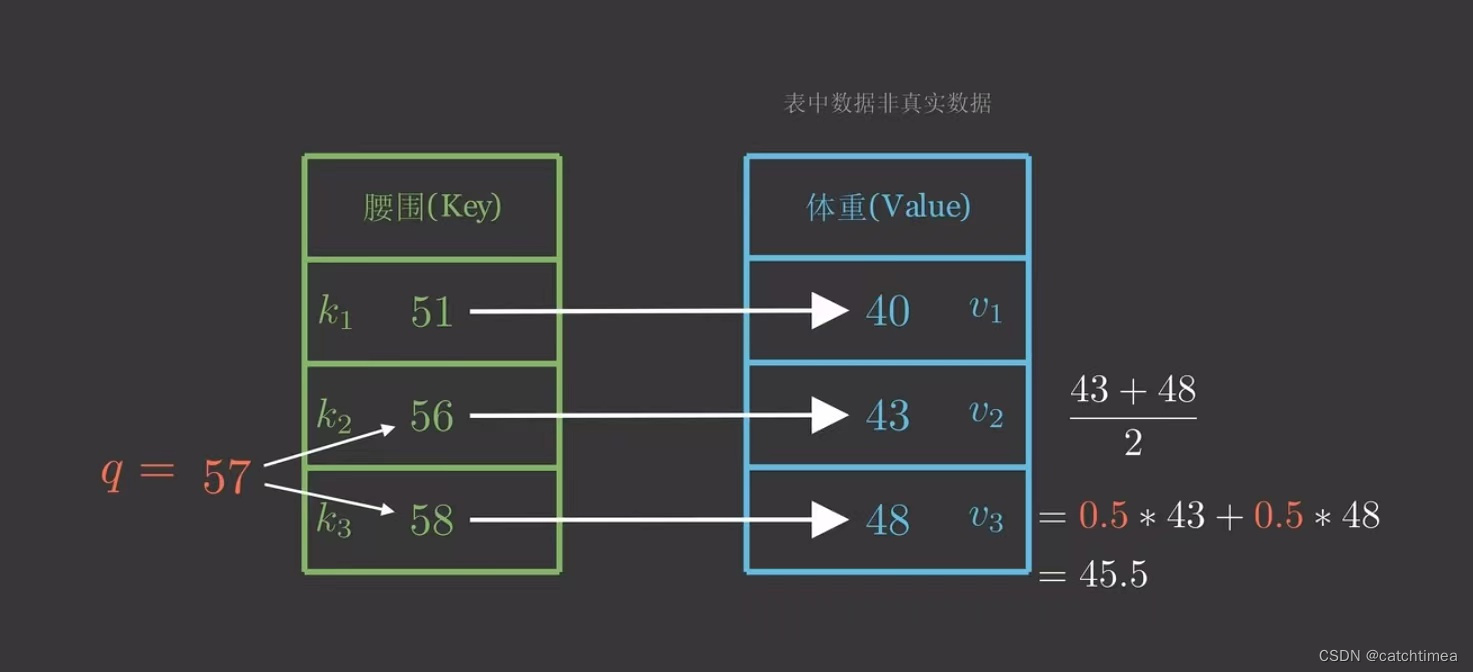
因为57距离56、58最近,我们自然会非常“注意”它们,所以我们分给它们的注意力权重各为0.5,不过我们没有用上其他的(Key,Value),似乎我们应该调整一下注意力权重,但权重如何计算?
假设用 来表示 q 与 k 对应的注意力权重,则体重预测值
为:

是任意能刻画相关性的函数,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









