






一、Ollama
Ollama 是一个旨在帮助用户轻松在本地运行、部署和管理模型的开源项目。它仅通过一个简单的命令行界面(CLI)就可让用户下载、运行和与各种开源大语言模型进行交互。
Ollama 的主要特点:
(1) 本地运行:可以在个人电脑或服务器上运行大模型,无需依赖云服务。
(2) 模型管理:支持一键下载、更新和切换不同模型。
(3) 跨平台支持:支持 macOS、Linux 和 Windows(通过 WSL)。
(4) API 兼容性:提供类似 OpenAI 的 API,方便开发者集成到自己的应用中。
(5) 轻量化:优化了模型加载和推理效率,适合本地开发和研究。
适用场景:
(1) 本地开发测试:快速验证 LLM 应用逻辑。
(2) 隐私敏感任务:数据无需上传到云端。
(3) 离线环境使用:在没有网络的情况下运行模型。
Ollama 支持的模型列表:library
1. Ollama 的安装
macOS/Linux :
curl -fsSL https://ollama.com/install.sh | shWindows (需WSL):
在 WSL(Ubuntu)中运行上述命令Windows 安装 WSL 的教程:Windows安装WSL教程-CSDN博客
2. 模型下载和运行
# 下载
ollama pull llama2
# 运行
ollama run llama2Ollama 默认提供 REST API(http://localhost:11434),也可像 OpenAI API 一样调用:
curl http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt": "为什么天空是蓝色的?"
}'二、vLLM
vLLM 是一个高效的大语言模型(LLM)推理和服务库,特别适合高吞吐量和低延迟的场景。
它支持多种API,此处仅展示常用的Chat API、Embeddings API 和 Rerank API。
vLLM 官方文档:Welcome to vLLM — vLLM
1. vLLM 的安装
# 创建虚拟环境
conda create -n myenv python=3.12 -y
# 激活虚拟环境
conda activate myenv
# 安装 vllm
pip install vllm2. vLLM 的使用
2.1 Chat Completions API
vllm serve Qwen/Qwen2.5-1.5B-InstructvLLM 框架部署模型时可指定多种参数,具体可参考:OpenAI-Compatible Server — vLLM
CLI (命令行调用) :
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-1.5B-Instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"}
]
}'SDK 调用:
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="Qwen/Qwen2.5-1.5B-Instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a joke."},
]
)
print("Chat response:", chat_response)2.2 Embeddngs API
vllm serve bge/bge-base-zh-v1.5
SDK 调用:
from openai import OpenAI
# 初始化客户端,指向你的本地 vLLM 服务
client = OpenAI(
base_url="http://localhost:8000/v1", # 你的 vLLM 服务地址
api_key="no-api-key-required" # 本地部署通常不需要 API key
)
# 调用 Embedding 接口
response = client.embeddings.create(
model="bge/bge-base-zh-v1.5", # 你的模型路径
input="你好,世界"
)
# 打印结果
print(response.data[0].embedding) # 输出 embedding 向量2.3 Rerank API
vllm serve your/rerank/model/path
SDK 调用:
from typing import Union
import cohere
from cohere import Client, ClientV2
model = "BAAI/bge-reranker-base"
query = "What is the capital of France?"
documents = [
"The capital of France is Paris", "Reranking is fun!",
"vLLM is an open-source framework for fast AI serving"
]
def cohere_rerank(client: Union[Client, ClientV2], model: str, query: str,
documents: list[str]) -> dict:
return client.rerank(model=model, query=query, documents=documents)
def main():
# cohere v1 client
cohere_v1 = cohere.Client(base_url="http://localhost:8000",
api_key="sk-fake-key")
rerank_v1_result = cohere_rerank(cohere_v1, model, query, documents)
print("-" * 50)
print("rerank_v1_result:\n", rerank_v1_result)
print("-" * 50)
# or the v2
cohere_v2 = cohere.ClientV2("sk-fake-key",
base_url="http://localhost:8000")
rerank_v2_result = cohere_rerank(cohere_v2, model, query, documents)
print("rerank_v2_result:\n", rerank_v2_result)
print("-" * 50)
if __name__ == "__main__":
main()# cohere 可以理解为类似 openai,也可提供 API 服务。
三、Xinference
Xinference 是一个由 Xorbits 团队开发的开源大模型推理和服务框架,旨在帮助用户高效地部署和运行各种开源大语言模型及其他生成式 AI 模型(如嵌入模型、多模态模型等)。它支持本地和分布式推理,并提供兼容 OpenAI API 的接口,方便集成到现有应用中。
Xinference 官方文档:Welcome to Xinference! — Xinference
主要特性:
(1) 多模型支持。
支持多种开源大模型、嵌入模型、多模态模型和自定义模型加载等。
(2) 灵活部署。
可在本地运行(适合开发测试),也支持分布式集群部署(适合生产环境)。同时支持 GPU/CPU 推理,优化计算资源利用。
(3) OpenAI 兼容 API。
提供类似 OpenAI 的 API,便于直接替换或集成现有应用。
(4) 量化与优化。
支持模型量化(如 4-bit/8-bit 量化),降低显存占用,提升推理速度。
(5) Web 界面。
内置管理界面,方便监控模型状态、资源使用情况等。
Xinference 支持多种后端来运行模型,例如Transformers,vLLM,Llama.cpp,SGLang 和 MLX 等。
gguf(GPT-Generated Unified Format)是专为优化和部署大型语言模型(如LLaMA、GPT等)设计的一种二进制文件格式,由llama.cpp团队开发。它通过量化技术和硬件适配,使大模型能在资源受限的设备上高效运行。其核心优势在于平衡性能、体积和易用性,适合本地化AI应用。
SGLang(Structured Generation Language)是一种专为结构化文本生成设计的领域特定语言,旨在更高效地控制大语言模型的生成过程,尤其适用于复杂推理、模板化输出和多步骤交互场景。
MLX 是苹果专为Apple Silicon芯片(如M1/M2/M3)优化的机器学习框架,旨在高效利用苹果硬件(如统一内存架构和GPU加速)来运行和训练深度学习模型。
1. Xinference 的安装
# 创建虚拟环境
conda create -n xinference python=3.12 -y
# 激活虚拟环境
conda activate xinference
# 安装xinferernce
pip install "xinference[all]"2. Xinference 的使用
# 指定端口和模型下载源运行
XINFERENCE_MODEL_SRC=modelscope xinference-local --host 0.0.0.0 --port 9997打开 web 页面:
# 如果是在服务器上运行,而需要在本机打开 Xinference 的 web 页面,则可在本机命令行窗口中输入以下命令进行端口映射:
ssh -CNg -L 9987:127.0.0.1:9997 root@主机号 -p 主机端口经过映射后,本机便可在浏览器中输入网址 http://127.0.0.1:9987 打开 Xinference 的 web 页面。
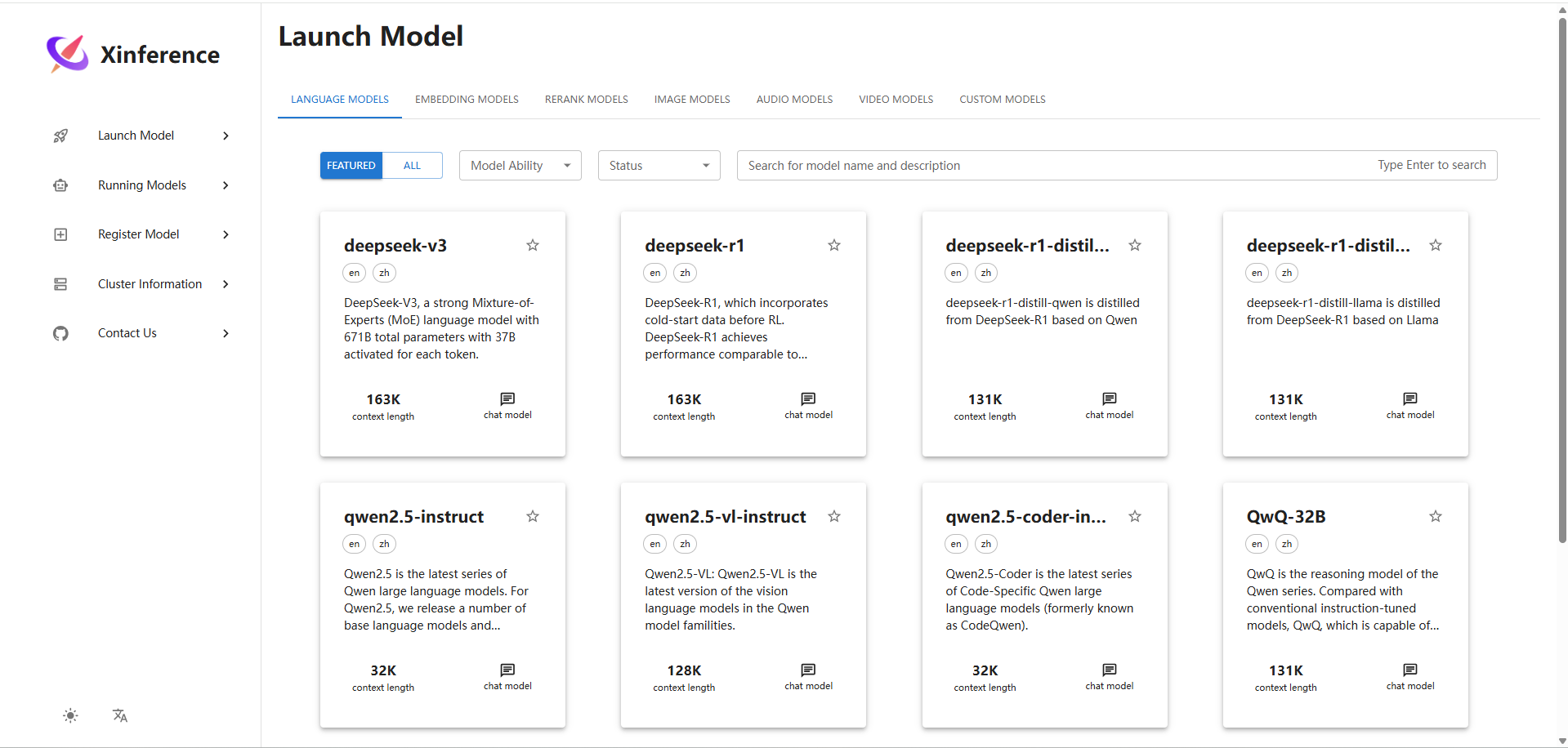
接下来便可选择不同类型的模型进行部署,以语言模型中的 qwen2.5-instruct-3b 为例,部署时可手动选择参数。
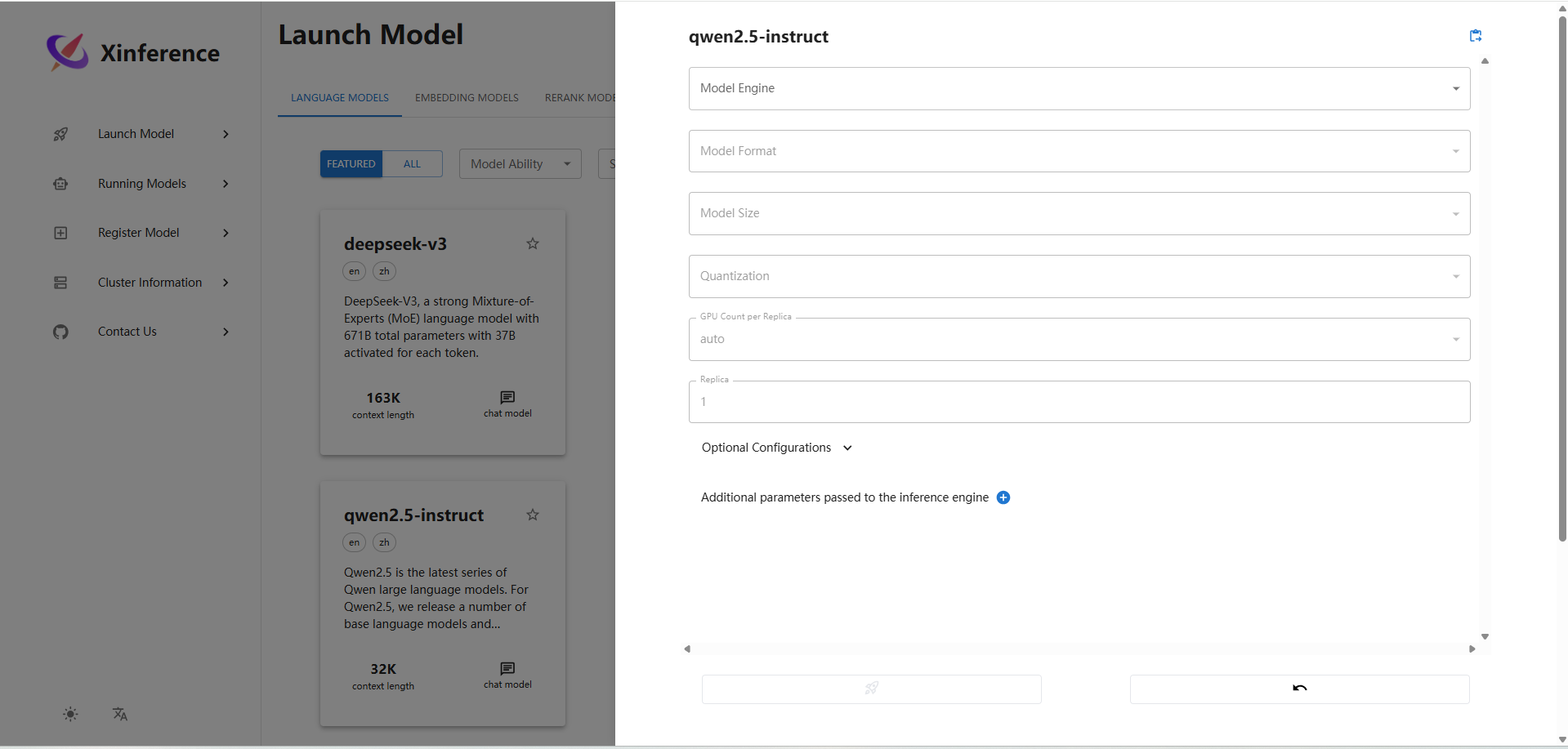
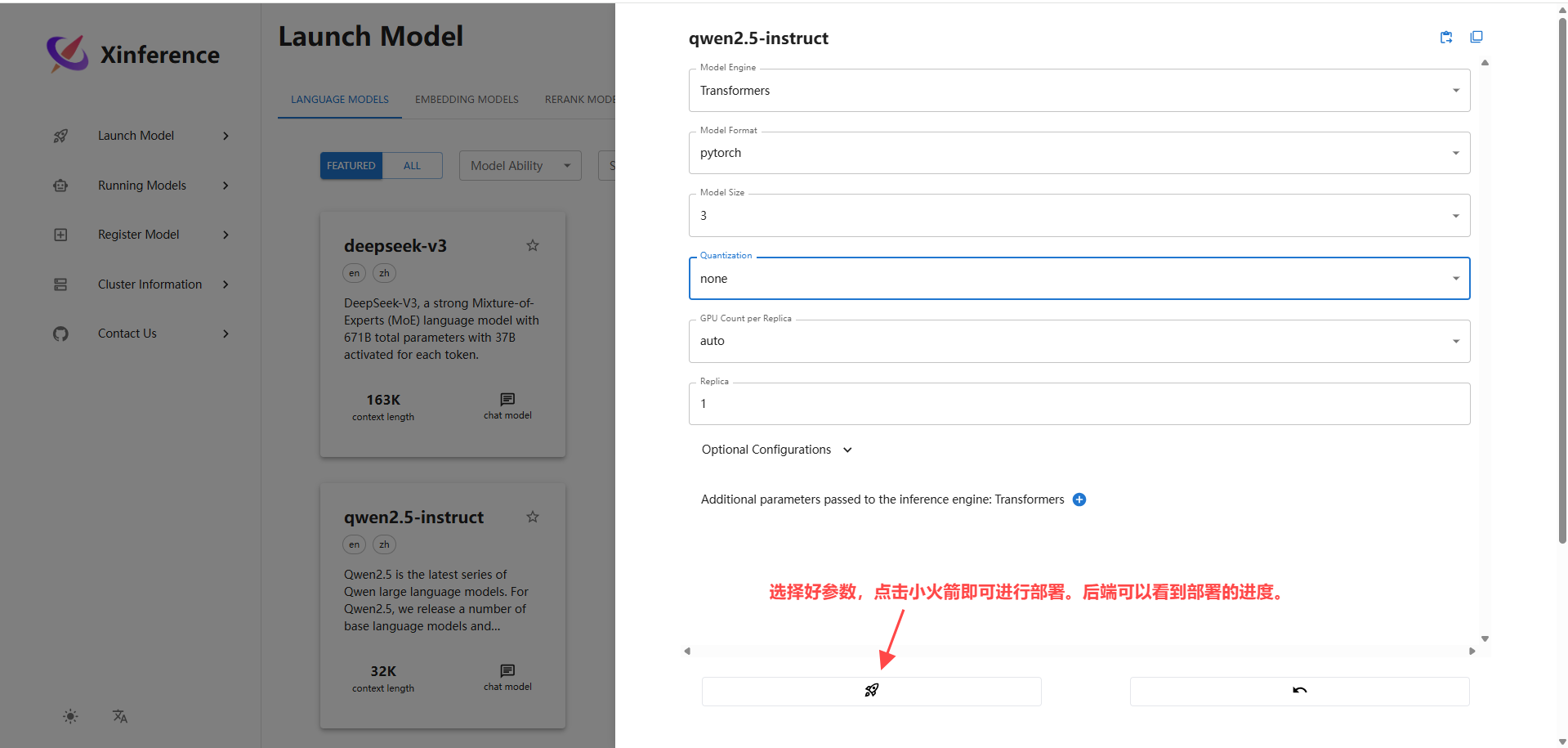
选择完参数后,点击左下角的小火箭开始部署,后端同时可以看到部署进度。
点击主页左侧导航栏中的 Running Models 可以查看正在运行的模型。
其使用方式基本与上述vLLM的一致,通过 xinference client 或者openai 调用。
2.1 使用语言模型
通过 Xinference Client 使用:
from xinference.client import Client
client = Client("http://localhost:9997")
model = client.get_model("MODEL_UID")
# Chat to LLM
model.chat(
messages=[{"role": "system", "content": "You are a helpful assistant"}, {"role": "user", "content": "What is the largest animal?"}],
generate_config={"max_tokens": 1024}
)
# Chat to VL model
model.chat(
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": "http://i.epochtimes.com/assets/uploads/2020/07/shutterstock_675595789-600x400.jpg",
},
},
],
}
],
generate_config={"max_tokens": 1024}
)通过 OpenAI Client 使用:
import openai
# Assume that the model is already launched.
# The api_key can't be empty, any string is OK.
client = openai.Client(api_key="not empty", base_url="http://localhost:9997/v1")
client.chat.completions.create(
model=model_uid,
messages=[
{
"content": "What is the largest animal?",
"role": "user",
}
],
max_tokens=1024
)2.2 使用嵌入模型
通过 Xinference Client 使用:
from xinference.client import Client
client = Client("http://localhost:9997")
model = client.get_model("MODEL_UID")
model.create_embedding("What is the capital of China?")通过 OpenAI Client 使用:
import openai
# Assume that the model is already launched.
# The api_key can't be empty, any string is OK.
client = openai.Client(api_key="not empty", base_url="http://localhost:9997/v1")
client.embeddings.create(model=model_uid, input=["What is the capital of China?"])2.3 使用重排模型
通过 Xinference Client 使用:
from xinference.client import Client
client = Client("http://localhost:9997")
model = client.get_model("MODEL_UID")
query = "A man is eating pasta."
corpus = [
"A man is eating food.",
"A man is eating a piece of bread.",
"The girl is carrying a baby.",
"A man is riding a horse.",
"A woman is playing violin."
]
print(model.rerank(corpus, query))
















 5429
5429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









