







导入所需要的库:
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split随机生成数据集,并且将数据集进行划分,下面是按1:4划分的。
X,y=make_moons(n_samples=500,noise=0.18,random_state=0)
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=0)引用支持线性核函数向量机(svm)模型,并且对模型进行训练。
#使用线性核函数的SVM
line_svm = SVC(kernel="linear")
line_svm=line_svm.fit(X_train, y_train)使用模型对测试集进行预测,并且输出分类准确率、混淆矩阵。
y_line=line_svm.predict(X_test)
print("线性核函数SVM的分类准确率:",accuracy_score(y_test,y_line))
print("混淆矩阵:")
print(confusion_matrix(y_test,y_line))依次使用多项式核函数、高斯核函数的支持向量机,并且输出其准确率和混淆矩阵。
#使用多项式核函数的SVM
poly_svm = SVC(kernel="poly")
poly_svm=poly_svm.fit(X_train, y_train)
#预测
y_poly=poly_svm.predict(X_test)
print("多项式核函数SVM的分类准确率:",accuracy_score(y_test,y_poly))
print("混淆矩阵:")
print(confusion_matrix(y_test,y_poly))
# print("其他度量:")
# print(classification_report(y_test,y_poly))
#使用高斯核函数的SVM
rbf_svm = SVC(kernel="rbf")
rbf_svm=rbf_svm.fit(X_train, y_train)
#预测
y_rbf=rbf_svm.predict(X_test)
print("高斯核函数SVM的分类准确率:",accuracy_score(y_test,y_rbf))
print("混淆矩阵:")
print(confusion_matrix(y_test,y_rbf))对上述三种方法进行可视化展示:
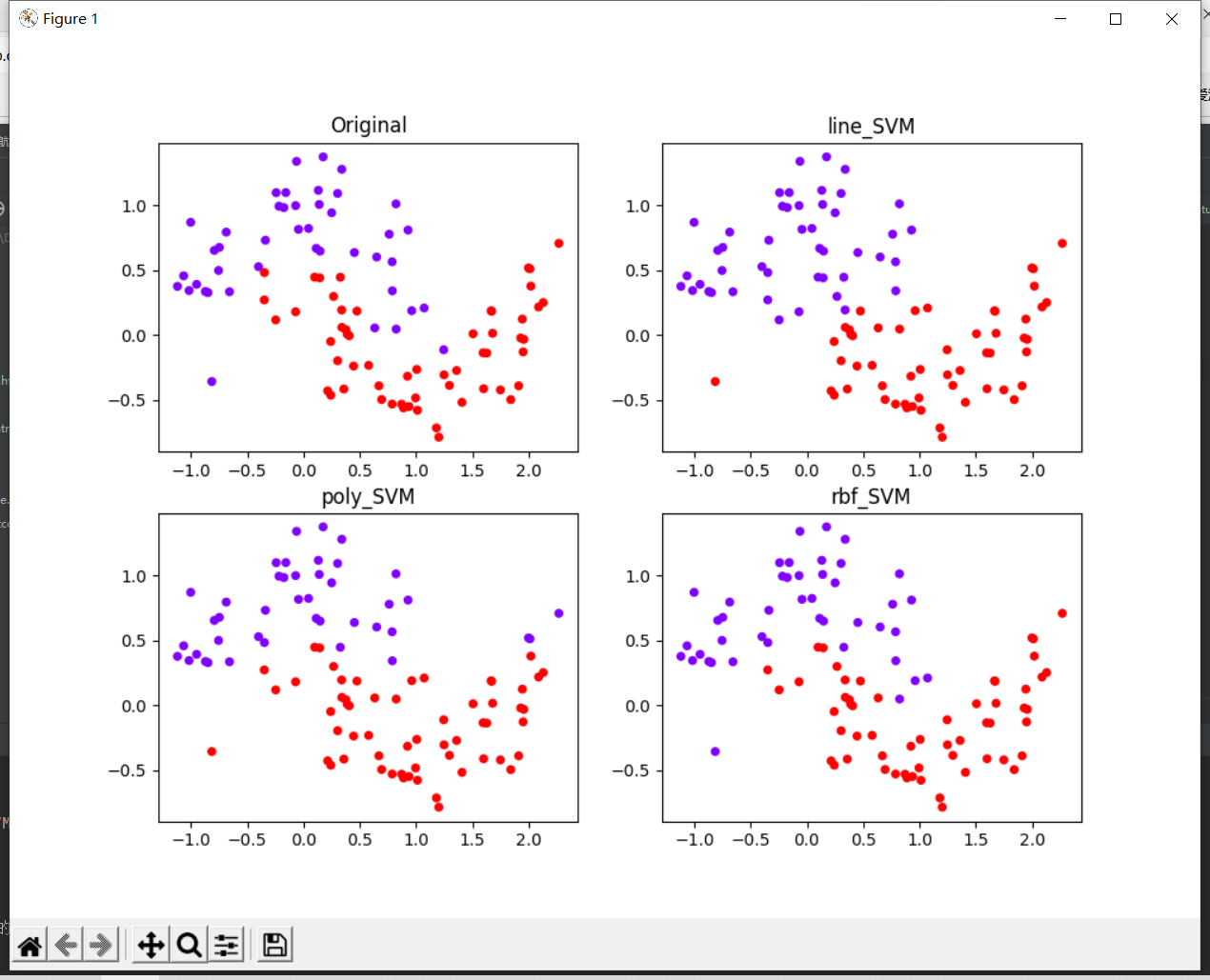
plt.figure(figsize=(10,10))
plt.subplot(221)
plt.scatter(X_test[:,0],X_test[:,1],c=y_test,s=20,cmap="rainbow")
plt.title("Original")
plt.subplot(222)
plt.scatter(X_test[:,0],X_test[:,1],c=y_line,s=20,cmap="rainbow")
plt.title("line_SVM")
plt.subplot(223)
plt.scatter(X_test[:,0],X_test[:,1],c=y_poly,s=20,cmap="rainbow")
plt.title("poly_SVM")
plt.subplot(224)
plt.scatter(X_test[:,0],X_test[:,1],c=y_rbf,s=20,cmap="rainbow")
plt.title("rbf_SVM")
plt.show()运行结果:
全部代码如下:
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
X,y=make_moons(n_samples=500,noise=0.18,random_state=0)
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=0)
#使用线性核函数的SVM
line_svm = SVC(kernel="linear")
line_svm=line_svm.fit(X_train, y_train)
#预测
y_line=line_svm.predict(X_test)
print("线性核函数SVM的分类准确率:",accuracy_score(y_test,y_line))
print("混淆矩阵:")
print(confusion_matrix(y_test,y_line))
# print("其他度量:")
# print(classification_report(y_test,y_line))
#使用多项式核函数的SVM
poly_svm = SVC(kernel="poly")
poly_svm=poly_svm.fit(X_train, y_train)
#预测
y_poly=poly_svm.predict(X_test)
print("多项式核函数SVM的分类准确率:",accuracy_score(y_test,y_poly))
print("混淆矩阵:")
print(confusion_matrix(y_test,y_poly))
# print("其他度量:")
# print(classification_report(y_test,y_poly))
#使用高斯核函数的SVM
rbf_svm = SVC(kernel="rbf")
rbf_svm=rbf_svm.fit(X_train, y_train)
#预测
y_rbf=rbf_svm.predict(X_test)
print("高斯核函数SVM的分类准确率:",accuracy_score(y_test,y_rbf))
print("混淆矩阵:")
print(confusion_matrix(y_test,y_rbf))
# print("其他度量:")
# print(classification_report(y_test,y_rbf))
plt.figure(figsize=(10,10))
plt.subplot(221)
plt.scatter(X_test[:,0],X_test[:,1],c=y_test,s=20,cmap="rainbow")
plt.title("Original")
plt.subplot(222)
plt.scatter(X_test[:,0],X_test[:,1],c=y_line,s=20,cmap="rainbow")
plt.title("line_SVM")
plt.subplot(223)
plt.scatter(X_test[:,0],X_test[:,1],c=y_poly,s=20,cmap="rainbow")
plt.title("poly_SVM")
plt.subplot(224)
plt.scatter(X_test[:,0],X_test[:,1],c=y_rbf,s=20,cmap="rainbow")
plt.title("rbf_SVM")
plt.show()














 281
281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









