






数据压缩实验四--DPCM
实验原理
DPCM编解码原理

DPCM为差分预测编码。在DPCM系统中,预测器的输入是已经解码以后的样本。在解码端无法得到原始样本,只能得到存在误差的样本,因此不用原始样本来做预测。在DPCM编码器中实际内嵌了一个解码器,如编码器中虚线框中所示。
在一个DPCM系统中,有两个因素需要设计:预测器和量化器。理想情况下,预测器和量化器应进行联合优化。实际中,采用一种次优的设计方法:分别进行线性预测器和量化器的优化设计。
在本次实验中,我们采用固定预测器和均匀量化器。预测器采用左侧预测。量化器采用8比特均匀量化,以及4比特,2比特,1比特均匀量化。对原始图像和预测误差分别进行熵编码,验证DPCM编码的编码效率。
PSNR计算压缩质量
psnr是“Peak Signal to Noise Ratio”的缩写,即峰值信噪比,是一种评价图像的客观标准。它是原图像与被处理图像之间的均方误差相对于(2n-1)2的对数值(信号最大值的平方,n是每个采样值的比特数),它的单位是dB。PSNR值越大,就代表失真越少。
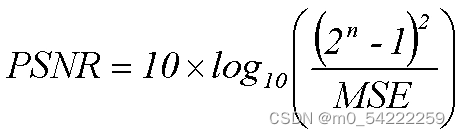
其中,MSE是原图像(语音)与处理图像(语音)之间均方误差。
实验代码
DPCM.cpp
#include<stdlib.h>
#include<stdio.h>
#include<math.h>
void DPCM(unsigned char* y_buffer, unsigned char* differ_buffer, unsigned char* rebuild_buffer,int width, int height,int bitnum)
{
for (int i = 0; i < height; i++)
{
for (int j = 0; j < width; j++)
{
if (j == 0)
{
differ_buffer[i * width] = ((y_buffer[i * width] - 128)+255)/pow(2,(double)(9-bitnum));
rebuild_buffer[i * width] = differ_buffer[i * width] * pow(2, (double)(9 - bitnum)) - 255 + 128;
}
else
{
differ_buffer[i * width+j] = ((y_buffer[i * width+j] - rebuild_buffer[i * width+j-1]) + 255) / pow(2, (double)(9 - bitnum));
rebuild_buffer[i * width + j] = differ_buffer[i * width+j] * pow(2, (double)(9 - bitnum)) - 255 + rebuild_buffer[i * width + j-1];
}
if (differ_buffer[i * width + j] > 255)
differ_buffer[i * width + j] = 255;
if(differ_buffer[i * width + j] <0)
differ_buffer[i * width + j] = 0;
if (rebuild_buffer[i * width + j] > 255)
rebuild_buffer[i * width + j] = 255;
if (rebuild_buffer[i * width + j] < 0)
rebuild_buffer[i * width + j] = 0;
}
}
}
main.cpp
#include<stdlib.h>
#include<stdio.h>
#include"math.h"
#include"DPCM.h"
void calculate_fre(unsigned char* buffer, double* frequency, int width, int height)
{
int size = width * height;
for (int i = 0; i < size; i++)
{
frequency[buffer[i]]++;
}
for (int k = 0; k < 256; k++)
{
frequency[k] /= size;
}
}
int main(int argc, char** argv)
{
const char* ori_name = argv[1];
const char* differ_name = argv[2];
const char* rebu_name = argv[3];
int bitnum = atoi(argv[4]);
FILE* ori_file = NULL;
FILE* differ_file = NULL;
FILE* rebu_file = NULL;
if ((ori_file = fopen(ori_name, "rb")) == NULL)
printf("Failed to open the original picture\n");
else
printf("succeeded to open the original picture\n");
if ((differ_file = fopen(differ_name, "wb")) == NULL)
printf("Failed to open the difference picture\n");
else
printf("succeeded to open the difference picture\n");
if ((rebu_file = fopen(rebu_name, "wb")) == NULL)
printf("Failed to open the rebulid picture\n");
else
printf("succeeded to open the rebulid picture\n");
int width = 256;
int height = 256;
unsigned char* y_buffer = new unsigned char[width * height];
unsigned char* u_buffer = new unsigned char[width * height / 4];
unsigned char* v_buffer = new unsigned char[width * height / 4];
unsigned char* differ_buffer = new unsigned char[width * height];
unsigned char* rebuild_buffer = new unsigned char[width * height];
fread(y_buffer, 1, width * height, ori_file);
fread(u_buffer, 1, width * height / 4, ori_file);
fread(v_buffer, 1, width * height / 4, ori_file);
//计算原图像的概率分布
double frequency[256] = { 0 };
calculate_fre(y_buffer, frequency, width, height);
FILE* orin_fre;
orin_fre = fopen("ori_frequency.txt", "wb");
fprintf(orin_fre, "%s\t%s\t", "symbol", "freq");
for (int i = 0; i < 256; i++)
{
fprintf(orin_fre, "%d\t%f\t", i, frequency[i]);
}
DPCM(y_buffer, differ_buffer, rebuild_buffer,width,height,bitnum);
//计算预测误差的概率分布
double frequency2[256] = { 0 };
calculate_fre(differ_buffer, frequency2, width, height);
FILE* differ_fre;
differ_fre = fopen("differ_frequency.txt", "wb");
fprintf(differ_fre, "%s\t%s\t", "symbol", "freq");
for (int i = 0; i < 256; i++)
{
fprintf(differ_fre, "%d\t%f\t", i, frequency2[i]);
}
//写入预测误差图像
fwrite(differ_buffer,1,width*height,differ_file);
fwrite(u_buffer, 1, width * height/4, differ_file);
fwrite(v_buffer, 1, width * height / 4, differ_file);
//写入重建图像
fwrite(rebuild_buffer, 1, width * height, rebu_file);
fwrite(u_buffer, 1, width * height / 4, rebu_file);
fwrite(v_buffer, 1, width * height / 4, rebu_file);
// 计算PSNR
double mse = 0;
double psnr = 0;
for (int i = 0; i < width*height; i++) {
mse += pow((y_buffer[i]-rebuild_buffer[i]),2);
}
mse = mse / (width * height);
psnr = 10 * log10(pow(255,2) / mse);
printf("PSNR=%f", psnr);
fclose(ori_file);
fclose(differ_file);
fclose(rebu_file);
delete[] y_buffer;
delete[] u_buffer;
delete[] v_buffer;
delete[] differ_buffer;
delete[] rebuild_buffer;
return 0;
}
DPCM.h
#pragma once
#ifndef DPCM_H_
#define DPCM_H_
void DPCM(unsigned char* y_buffer, unsigned char* differ_buffer, unsigned char* rebuild_buffer, int width, int height, int bitnum);
#endif
实验步骤
实验图片的准备
首先准备实验所需yuv文件,调用给定bmp2yuv.exe将bmp文件转换为yuv文件
但是发现得到的yuv文件都是0kb,写入失败,因此调用之前的BMP2YUV程序得到相应的yuv文件。
命令参数
在项目属性页更改命令参数,运行程序,得到8bit量化后的预测图像和重建图像。

图像质量比较
8比特量化
8bit量化时图像质量比较(以PSNR进行计算)
| 原图 | 预测误差 | 重建图像 | PSNR |
|---|---|---|---|
 |  |  | 51.133820 |
 |  |  | 51.142562 |
 |  |  | 44.182261 |
 |  |  | 14.886160 |
 |  |  | 18.241523 |
 |  |  | 17.084274 |
我们可以看到,当用8bit量化时,前三张重建图像的PSNR均大于40dB,说明图像质量很好,人眼很难看出差异,而后三张图片的PSNR均小于20dB,说明图像质量很差,人眼可以很明显的看出差异。由此反映了DPCM对不同图像所起的效果是不同的。由于此次实验采用左侧预测,因此对于水平方向有较强相关性的图像,重建图像的效果会更好。
4比特,2比特,1比特量化
下面我们来比较对于一张相同的图片,分别用8bit,4bit,2bit,1bit量化时,所得重建图像的差别。
| 8bit | 4bit | 2bit | 1bit |
|---|---|---|---|
 |  |  |  |
 |  |  |  |
 |  |  |  |
随着量化比特数的减小,重建图像的质量大大降低,图像失真明显。当只用1bit量化时,重建图像已完全分辨不出其原图像。
Huffman熵编码
用给定的huff_run程序进行huffman编码,在命令行窗口输入:
huff_run.exe -i Lena256B_error.yuv -o Lena_error.huff -c -t Lena_error.txt

运行程序,得到编码后的huff文件和概率统计文本文件。

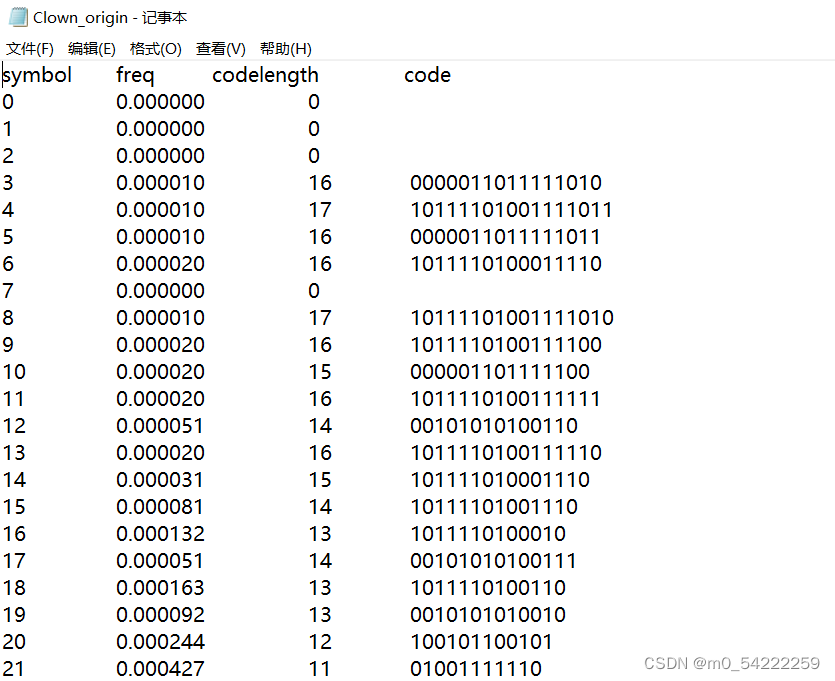
分别对原始yuv文件和预测误差文件进行哈夫曼编码
比较编码效率
| 原始图像 | 原始图像大小 | 直接熵编码 | 压缩效率 | DPCM+熵编码 | 压缩效率 |
|---|---|---|---|---|---|
| Lena.yuv | 96.0 KB | 68.2 KB | 140% | 45.0 KB | 213% |
| Clown.yuv | 96.0 KB | 73.4 KB | 130% | 47.4 KB | 202% |
| Fruit.yuv | 96.0 KB | 73.9 KB | 130% | 41.8 KB | 229% |
| Noise.yuv | 96.0 KB | 70.3 KB | 136% | 74.1 KB | 129% |
| Odie.yuv | 96.0 KB | 20.3 KB | 473% | 17.7 KB | 542% |
| Zone.yuv | 96.0 KB | 73.7 KB | 130% | 43.5 KB | 220% |
可以看出,经过DPCM后再进行熵编码,一般来说,压缩效率比直接熵编码大大提高。对于个别图像,经过DPCM后再进行熵编码,压缩效率反而下降。可能是由于图像水平方向的相关性太低,不适合做预测。
原始图像与预测误差概率分布
| 图像 | 原始图像概率分布 | 预测误差概率分布 |
|---|---|---|
| Lena.yuv | 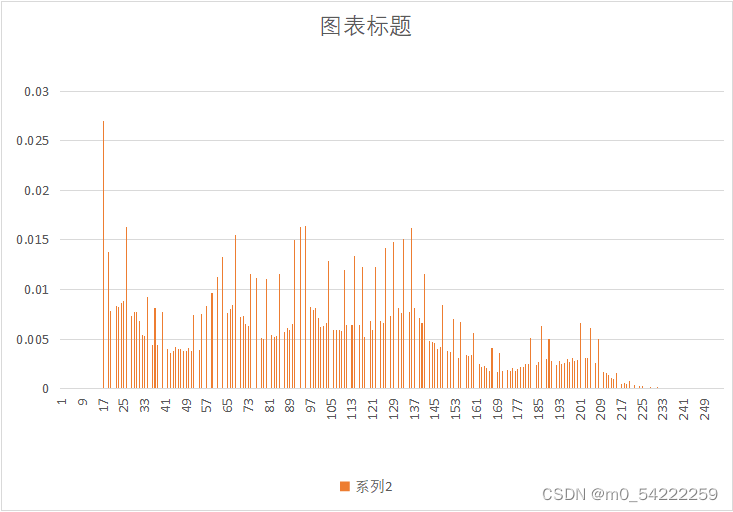 | 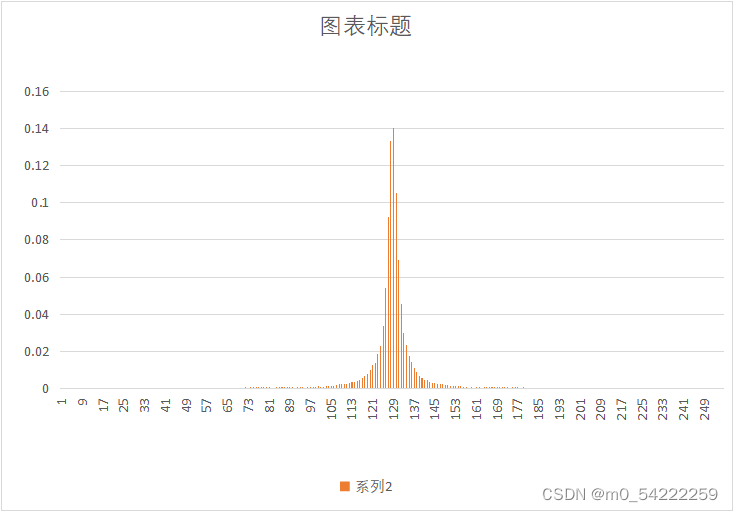 |
| Clown.yuv |  | 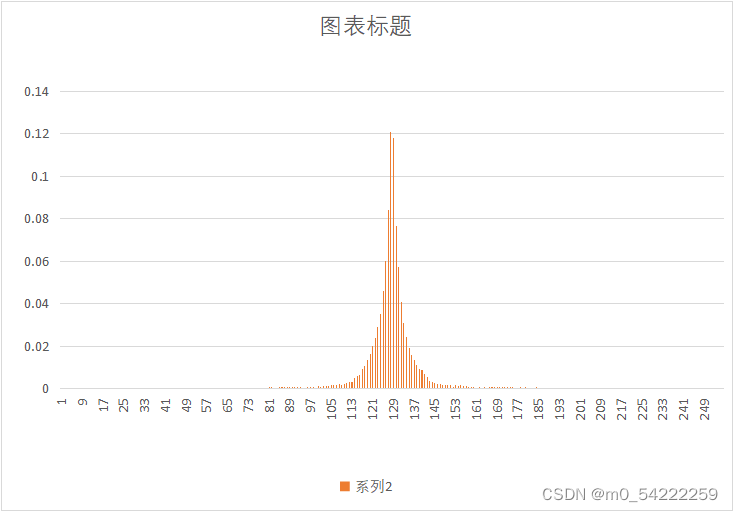 |
| Fruit.yuv |  | 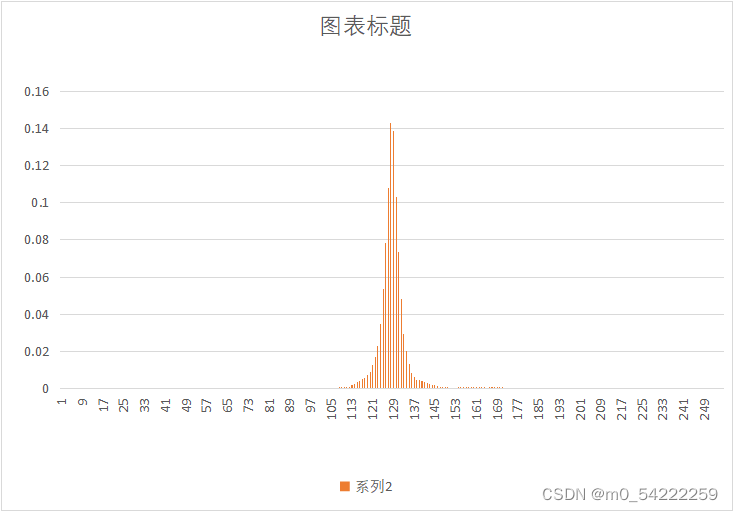 |
| Noise.yuv | 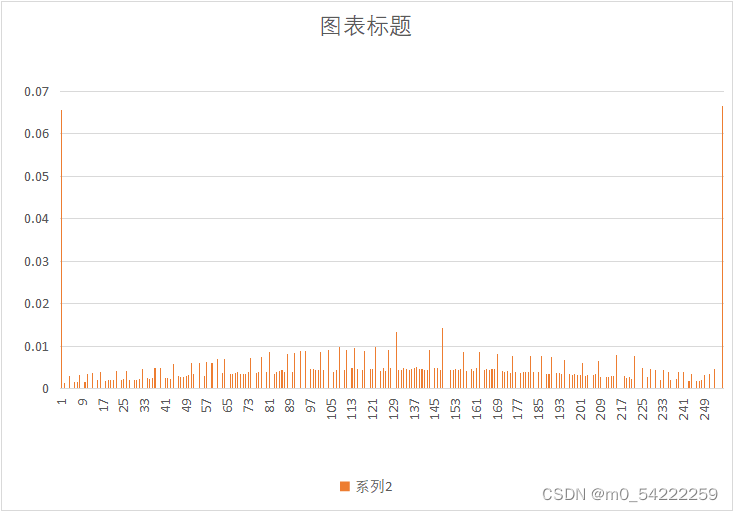 | 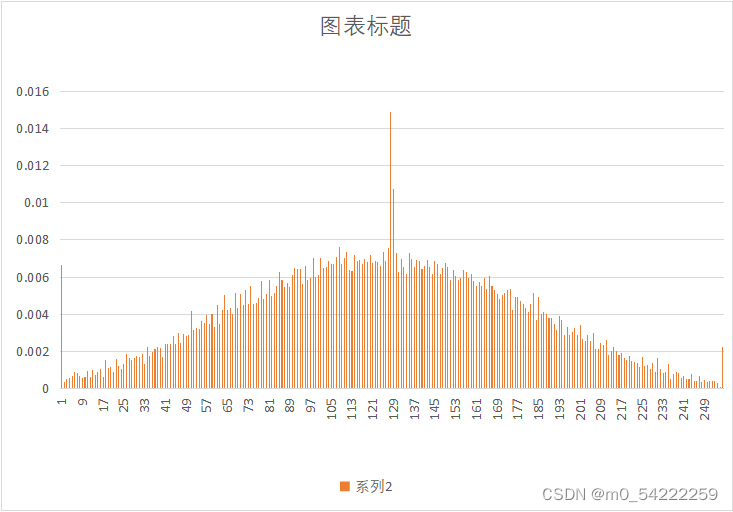 |
| Odie.yuv |  |  |
| Zone.yuv | 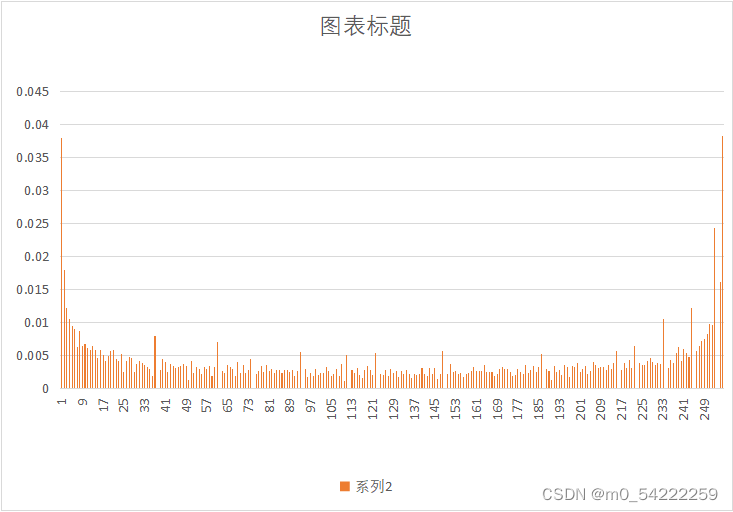 | 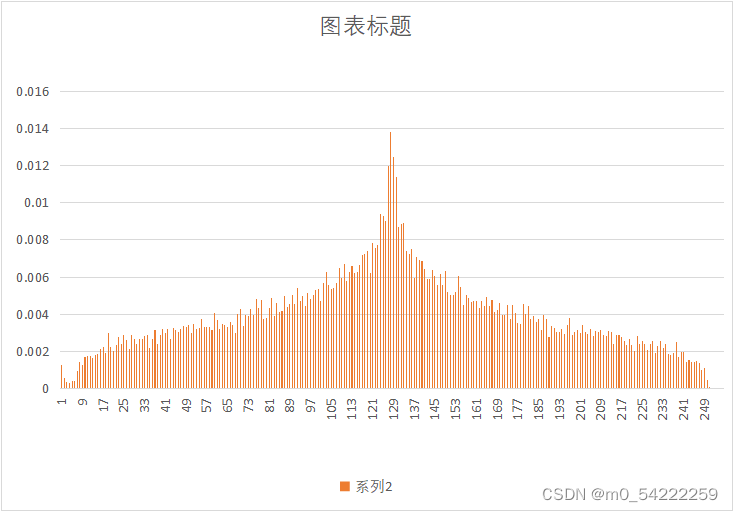 |
可以很明显的看出,经过DPCM后,预测误差的概率分布趋向于拉普阿斯分布,概率分布很不均匀,适合用哈夫曼熵编码,因此可以提高压缩效率。















 1567
1567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









