







1.BlockManager
BlockManager是Spark的分布式存储系统
主从结构:BlockManagerMaster/BlockManager(Slave)
BlockManagerMaster 在Driver端启动 :负责接受Executor上的BlockManager的注册 管理BlockManager的元数据信息
BlockManager 在每个Executor中启动 :负责管理所在节点上的数据
1.1 BlockManager
主要由四部分构成
MemoryStore:负责对内存上的数据进行存储和读写
DiskStore:负责对磁盘上的数据进行存储和读写
BlockTransferService:负责建立网络连接
BlockManagerWorker:负责对其他的BlockManager的数据进行读写
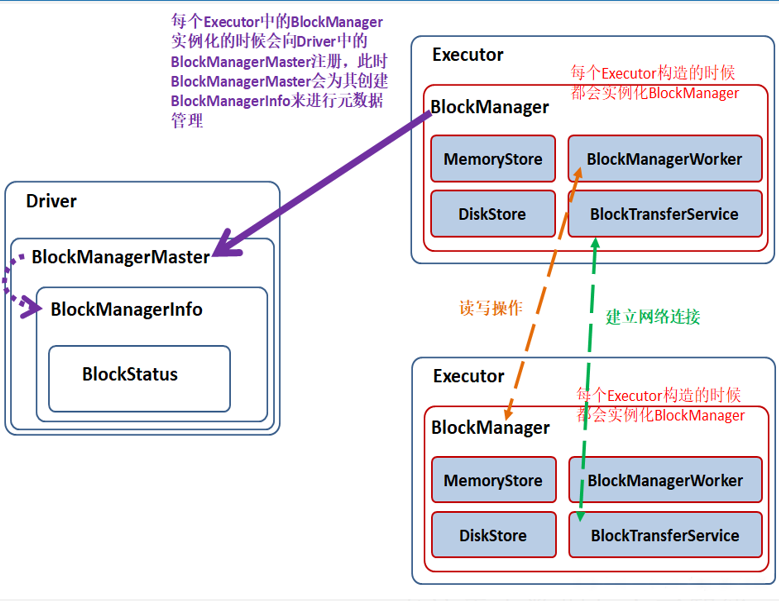
当Executor 的BlockManager 执行了增删改操作,那就必须将 block 的 blockStatus 上报给Driver端的BlockManagerMaster
BlockManagerMaster 内部的BlockManagerMasterEndPoint 内维护了元数据信息的映射,其内部通过Map、Set等数据结构实现,易于维护增加、更新、删除元数据
BlockManager主要维护以下三类数据: Cache缓存的数据 广播变量和累加器 Shuffle产生的数据
1.2 广播变量获取流程
广播变量获取流程如下:
算子内部使用了广播变量
Task会向Executor申请获取广播变量,若Executor暂无数据,则 Executor首先会向同机架的其他Executor获取
若获取不到再向跨机架的Executor获取
如果还是获取不到,则向Driver端获取数据
广播变量获取后会优先放入内存中,由BlockManager管理维护
后续Task可直接从MemoryStore中获取使用
1.3 Shuffle文件获取过程
Shuffle文件获取过程: MapOutputTrack也属于BlockManager中的一个服务,用于管理MapTask的输出
当MapTask在Executor中执行完成之后会生成Shuffle文件,由MapOutputTrack管理,并向Driver端汇报文件地址
下游ReduceTask执行时会向Driver端先获取地址,再连接对应的Executor获取Shuffle文件
MapTask为什么需要向Driver端汇报地址?
基于RDD第五大特性: Spark为每个Task尽可能的提供最佳计算位置 ,移动计算,不移动数据
尽可能让MapTask和ReduceTask在一个Executor中执行,避免大批量的Shuffle文件通过网络在不同的Executor之间进行传输,提升任务运行效率
即让每个Task的数据本地化级别最优
2.数据本地化级别
Spark任务主要有5个数据本地化级别:
PROCESS_LOCAL进程本地化:计算的数据在本进程的内存中
NODE_LOCAL节点本地化:1.计算的数据在本节点所在的磁盘上 2.计算的数据在本届点其他Executor进程的内存中
NO_PREF无最佳位置:所计算数据在外部系统,例如MySQL,故无最佳计算位置
RACK_LOCAL机架本地化:Task所计算的数据在同机架的不同节点的磁盘或者Executor进程的内存中
ANY跨机架调用:Task所计算的数据在不同机架的不同节点的磁盘或者Executor进程的内存中
3.资源申请和任务调度
Spark等计算任务运行分为两个步骤:资源申请,任务调度
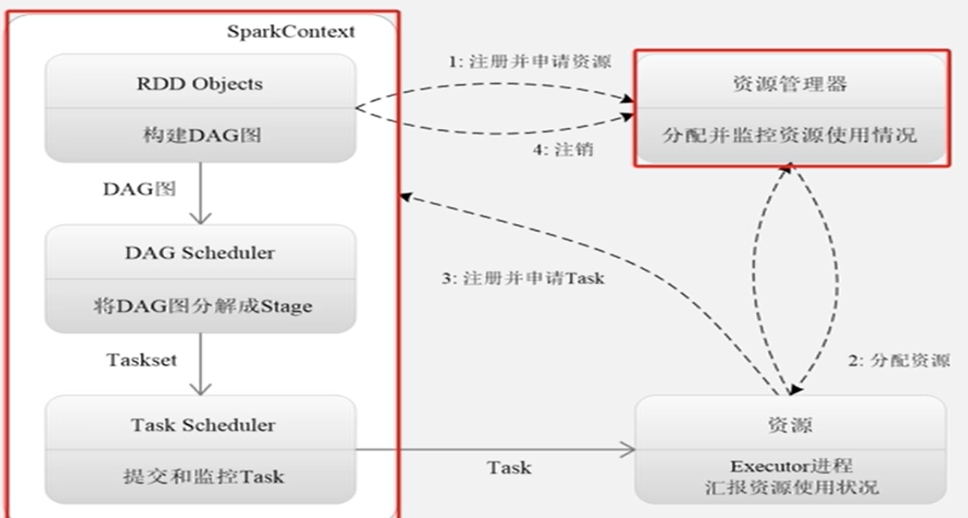
3.1 资源申请
On Yarn分为两种运行模式:client客户端模式和cluster集群模式
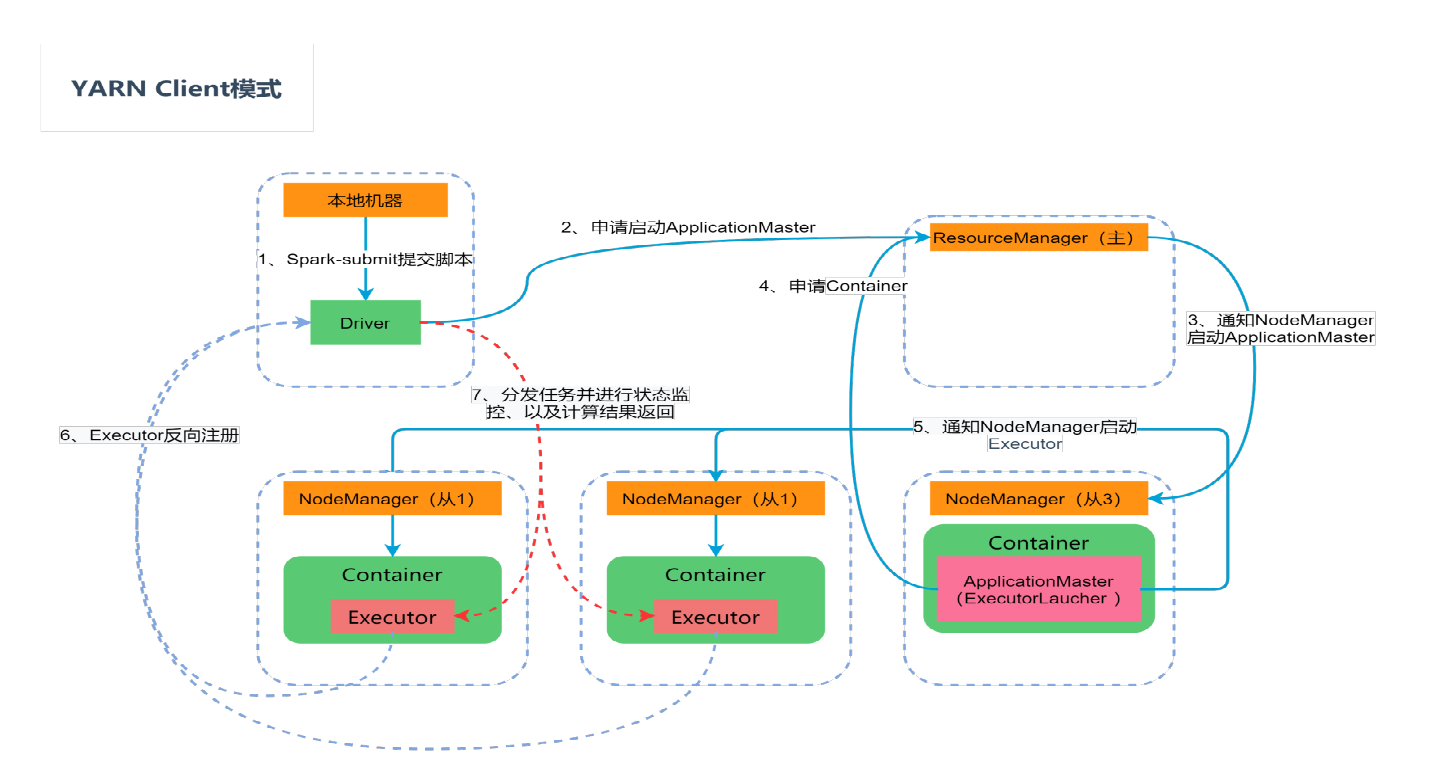
Yarn Client模式
运行流程:
在 YARN Client 模式下,spark-submit提交 Spark Job之后,就会提交的本地机器上启动Driver端
Driver 启动后会与 ResourceManager (RM)建立通讯并发起启动 ApplicationMaster(AM)
请求 RM接收到这个 Job 时,会在集群中选一个合适的 NodeManager (NM)并分配一个 Container(具有计算资源的一个容器),然后启动 ApplicationMaster(初始化SparkContext)
AM的功能相当于一个 ExecutorLaucher (Executor启动器),负责向 RM申请 Container 资源 ,RM收到请求后便会与 NM通信,启动 Container
AM对RM指定 NM分配的 Container 发出启动 Executor 进程请求
Executor进程启动后会向 Driver 反向注册,Executor 全部注册完成后 Driver 开始执行执行 Job 任务
Driver 中的 SparkContext 分配 Task 给 Executor 执行,Executor 运行 Task 并向 Driver 汇报运行的状态、进度、以及最终的计算结果;让 Driver 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务
应用程序运行完成后,AM向 RM申请注销并关闭自己。
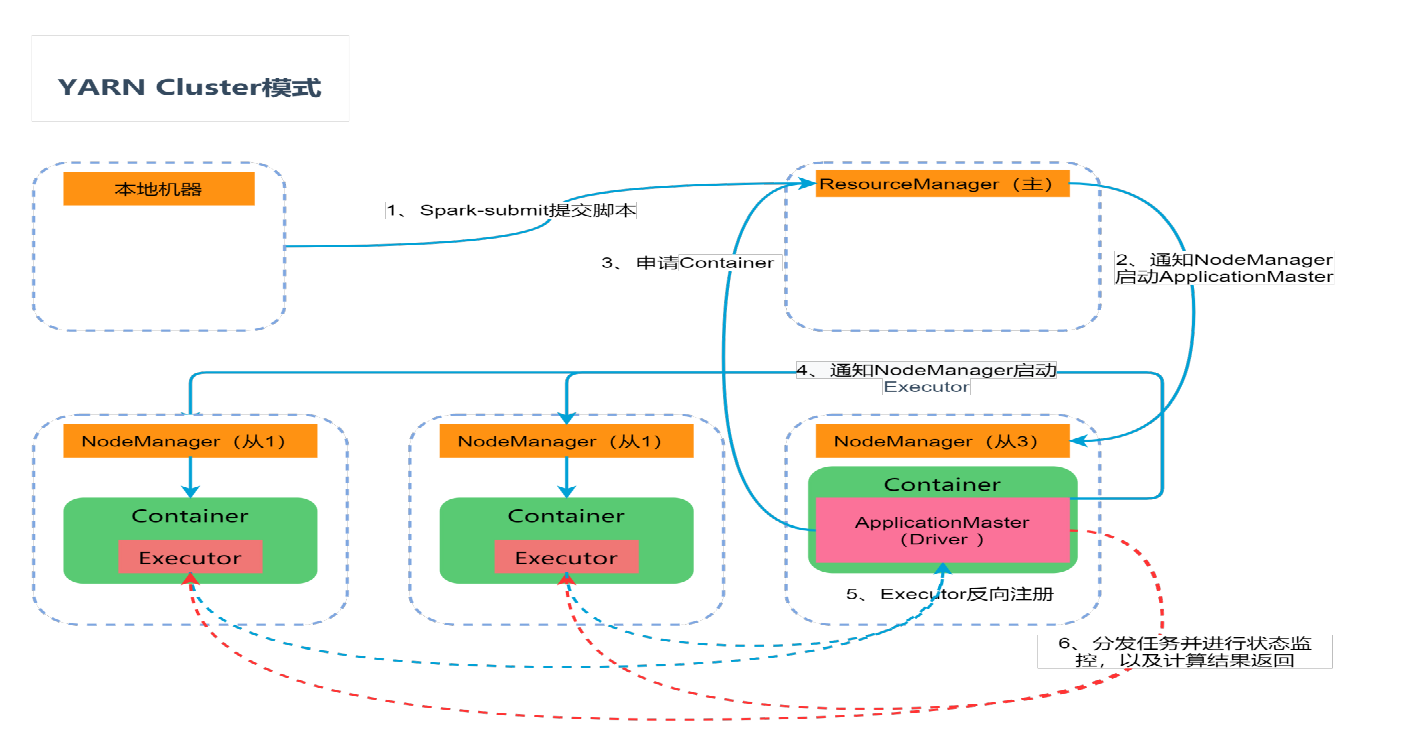
Yarn Cluster模式
在 YARN Cluster 模式下,Spark 任务提交之后会与 RM建立通讯,并发出申请启动 AM请求
RM接收到这个 Job 时,会在集群中选一个合适的 NodeManager 并分配一个 Container,然后启动 AM,此时的 AM不仅负责ExecutorLauncher,还兼顾 Driver的作用
AM启动后向 RM申请资源启动Executor,RM接到 AM的资源申请后会在合适(有资源的情况下)的 NodeManager 中分配 Container
AM对RM指定 NodeManager 分配的 Container 发出启动 Executor 进程请求
Executor 进程启动后会向 AM(Driver)反向注册,Executor 全部注册完成后,开始执行执行 Job 任务
AM中的 SparkContext 分配 Task 给 Executor 执行,Executor 运行 Task 并向AM(Driver)汇报运行状态、进度、以及最终结果;让 AM(Driver)随时掌握各任务的运行状态,从而可在任务失败时重新启动任务
应用程序运行完成后,ApplicationMaster 向 ResourceManager 申请注销并关闭自己;
3.2 任务调度
术语解释
Application:基于Spark的应用程序,包含了Driver端和Executor端
Driver程序:运行main函数并且新建SparkContext的程序
ClusterManager:集群资源管理者,例如Yarn中的
ResourceManager WorkerNode:工作节点,启动Executor的地方,例如Yarn中的NodeManager
Executor:在WorkerNode上为某应用启动的一个进程,该进程负责运行任务,并且负责维护存在内存或者磁盘上的数据,每个应用都有各自自独立的
Executor Task:线程对象,被发送到某个Executor上的执行单元
DAGSchedule: 基于DAG及宽窄依赖切分Stage,决定每个任务的最佳位置 记录哪个RDD或者Stage输出被物化 将Taskset传给底层调度器TaskScheduler 重新提交shuffle输出丢失的stage
TaskSchedule: 提交Taskset(一组并行task)到集群运行并汇报结果 出现Shuffle输出lost要报告fetchfailed错误 碰到straggle任务需要放到别的节点上重试 为每一一个TaskSet维护一一个TaskSetManager(追踪本地性及错误信息)
一个Spark Application包含多个Job
每个Action算子对应一个Job
一个Job又可以根据有宽窄依赖划分成多个Stage
Stage是一组可以并行计算的Task,即一个Stage中包含了很多个Task
Task是Spark任务执行调度的最小单元
Task最终会被Driver端发送到Executor中执行 当资源申请过程完成后,Executor启动成功,即可进行任务调度
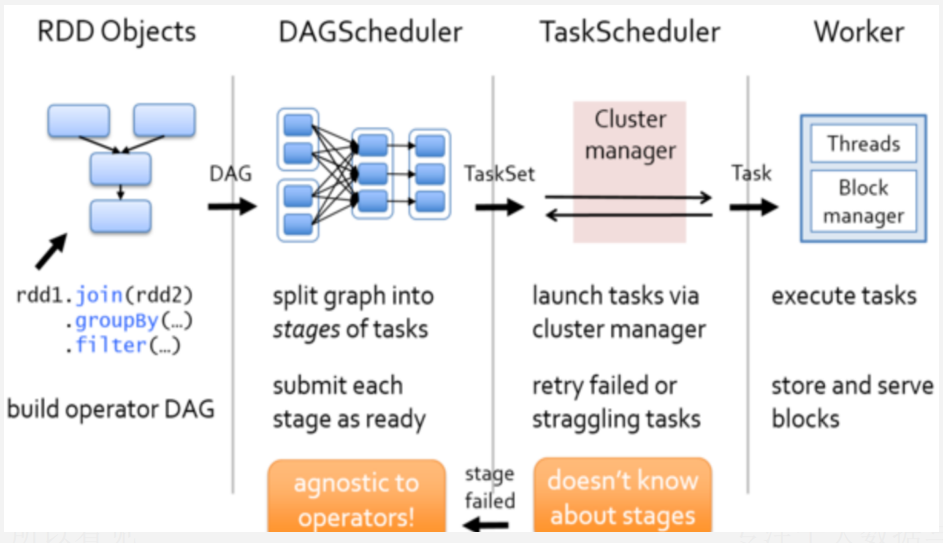
具体流程:
RDD之间存在着依赖关系,基于这些依赖关系可以形成DAG有向无环图
DAGScheduler会对形成DAG图根据宽窄依赖进行Stage划分 划分的规则很简单,从后往前回溯 遇到窄依赖加入本stage 遇见宽依赖进行Stage切分
DAGScheduler会将每个Stage以TaskSet的形式提交给TaskScheduler
TaskScheduler 负责具体的Task调度,将Task发送到Worker节点执行
当Task失败时会由TaskScheduler进行重试,默认重试3次,三次之后如果还是失败则认定该Task所在的job失败
若遇到Shuffle File Not Found问题,则DAGSchedule会重新提交Shuffle输出丢失的Stage,默认重试4次,四次之后还是失败则认定Application失败
推测执行:碰到计算缓慢Task,会在其他节点的Executor上启动一个相同的Task,哪个Task先完成,就以最先完成的Task其计算结果作为最终结果
















 1480
1480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









