







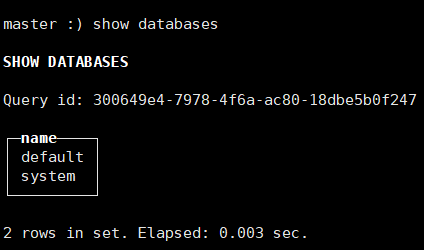
1.数据库
show databases //显示数据库
创建数据库(使用默认的引擎): CREATE DATABASE db_name;
创建数据库使用Mysql引擎 :
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]
ENGINE = MySQL('host:port', ['database' | database], 'user', 'password')
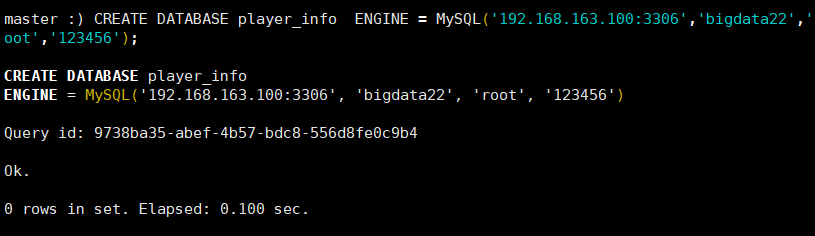
CREATE DATABASE player_info ENGINE = MySQL('192.168.163.100:3306','bigdata22','r
oot','123456');
删除数据库 drop database 名称
use 数据库名字 //使用某个数据库
show tables //显示数据库中的表
MySQL引擎

2.数据类型
2.1 整型
UInt8, UInt16, UInt32, UInt64, UInt128, UInt256, Int8, Int16, Int32, Int64, Int128, Int256
固定长度的整型,包括有符号整型或无符号整型。
创建表时,可以为整数设置类型参数 (例如. TINYINT(8), SMALLINT(16), INT(32), BIGINT(64)), 但 ClickHouse 会忽略它们.
别名:
Int8—TINYINT,BOOL,BOOLEAN,INT1.Int16—SMALLINT,INT2.Int32—INT,INT4,INTEGER.Int64—BIGINT.
注:想要多行输入,需在后面加一个-m
![]()
建表:
CREATE TABLE type_int_info(
int_value8 BOOL COMMENT 'int8-bool类型',
int_value16 SMALLINT COMMENT 'int8-small类型',
uint_value8 UInt8 COMMENT 'Uint8类型',
uint_value16 UInt16 COMMENT 'Uint16类型'
)ENGINE=TinyLog;
//clickhouse里语句中的字符串用单引号 且严格区分大小写插入数据:
INSERT INTO type_int_info values (1,1,1,1);
INSERT INTO type_int_info values (0,1,1,1);
INSERT INTO type_int_info values (0,1,-1,-1);
2.2 字符串
字符串可以任意长度的。它可以包含任意的字节集,包含空字节。因此,字符串类型可以代替其他 DBMSs 中的 VARCHAR、BLOB、CLOB 等类型。
此外,clickhouse中还有固定字符串。
clickhouse里字符串没有长度限制 且没有编码概念
建表语句:
CREATE TABLE type_str_info(
name String,
age UInt8
)ENGINE=TinyLog;插入语句:
INSERT INTO type_str_info values ('张三',20),('李四',23);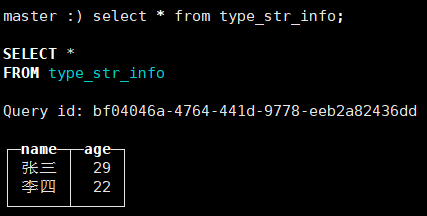
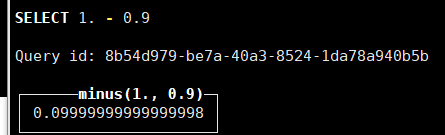
2.3 浮点类型
浮点型:
一般不能用于来存储精度要求高的数据
类型与以下 C 语言中类型是相同的:
Float32-floatFloat64-double
Decimal 类型:
有符号的定点数,可在加、减和乘法运算过程中保持精度。对于除法,最低有效数字会被丢弃(不舍入)。在做计算时,不会丢失精度。
建表语句
CREATE TABLE type_dec_float_info (
float_ Float32,
Decimal_ Decimal64(2)
)ENGINE = TinyLog;
//decimal保留两位小数插入语句
INSERT INTO type_dec_float_info values (1.202000,3.4444),(1.20,3.44)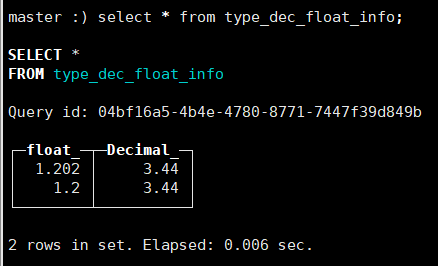
2.4 日期类型
Date类型
建表语句:
CREATE TABLE type_date_info (
date1 Date,
date2 Date32
)ENGINE = TinyLog插入语句:
INSERT INTO type_date_info values (1677826652,'2023-03-03'),('2023-03-03',1677826652);注意:插入数据时,可以用时间戳,也可以使用字符串方式
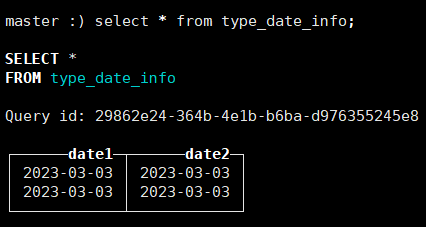
注意:对于Date日期类型不能直接将字符串格式的时间插入进去,可以将其转换成时间戳再插入
INSERT INTO type_date_info values ('2023-03-03 15:26:23','2023-03-03 15:26:23')
上面这种方式不可行。
Datetime类型
建表语句:
CREATE TABLE type_datetime_info (
datetime DateTime
)ENGINE = TinyLog
插入语句:
INSERT INTO type_datetime_info values (1677826652),('2023-03-03'),('2023-03-03 15:26:23')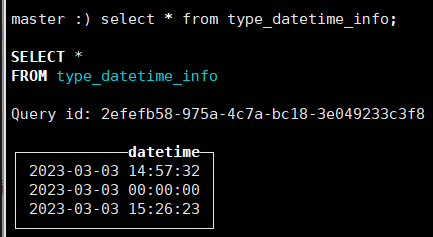
2.5 枚举类型
建表语句:
CREATE TABLE type_enum_info(
id UInt8,
gender Enum('男'=1,'女'=0)
)ENGINE = TinyLog插入语句:
INSERT INTO type_enum_info values(101,1),(102,0),(103,'女'),(104,'男');
执行结果:
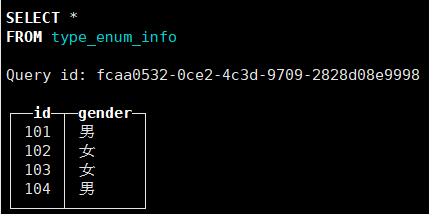
注意: 对于枚举类型来说,插入1和'男'在表中表示内容一致
更多数据类型请查看官网:Fast Open-Source OLAP DBMS - ClickHouse
3 表引擎
3.1 表引擎类型
MergeTree 可以支持排序,对数据进行分区,可以对查询进行优化
ReplacingMergeTree 可以对数据进行做去重操作
SummingMergeTree 可以对数据进行做预聚合操作
TinyLog 日志引擎,不支持索引 用于测试
集成引擎: Mysql Kafka
Memory 内存引擎 将数据存储在内存当中,速度极快,但是重启服务后,数据丢失
3.2 MergeTree
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
CREATE TABLE student(
id String,
name String,
age UInt8,
gender Enum('男'=1,'女' = 0),
clazz String,
create_time Date
)ENGINE = MergeTree()
ORDER BY (id,age);INSERT INTO student values('1003','张三',24,1,'文科一班','2023-03-03'),
('1002','李四',23,1,'理科一班','2023-03-03'),
('1001','王五',22,0,'文科二班','2023-03-03'),
('1004','赵六',21,1,'文科一班','2023-03-03');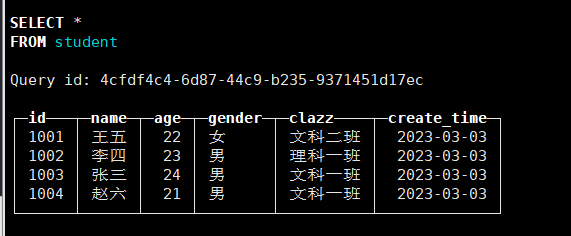
在MergeTree 中order by必须有,表示按什么排序
插入俩遍,得到如下结果
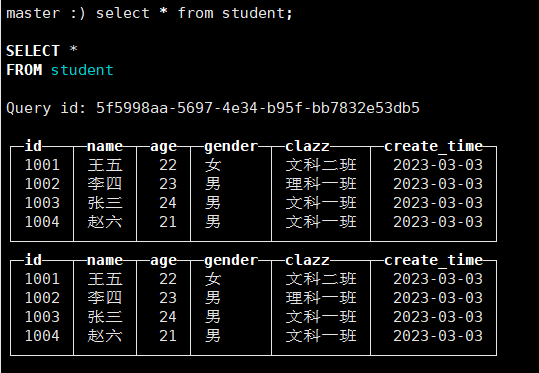
刚开始会在/var/lib/clickhouse/data/student下生成俩个目录,经过一段时间后,系统会自动将俩个文件夹合并在一起。


可以看出,all_1_1_0和all_2_2_0合并成了all_1_2_1(第一个1代表最小值,2代表最大值,第二个1代表合并的次数)
PARTITION
对数据进行分区
建表
CREATE TABLE student_partition(
id String,
name String,
age UInt8,
gender Enum('男'=1,'女' = 0),
clazz String,
create_time Date
)ENGINE = MergeTree()
ORDER BY (id,age)
PARTITION BY toYYYYMMDD(create_time);分俩次插入数据
INSERT INTO student_partition values('1003','张三',24,1,'文科一班','2023-03-03'),
('1002','李四',23,1,'理科一班','2023-03-03'),
('1001','王五',22,0,'文科二班','2023-03-03'),
('1004','赵六',21,1,'文科一班','2023-03-03');INSERT INTO student_partition values('1003','张三',24,1,'文科一班','2023-03-03'),
('1002','李四',23,1,'理科一班','2023-03-02'),
('1001','王五',22,0,'文科二班','2023-03-02'),
('1004','赵六',21,1,'文科一班','2023-03-02');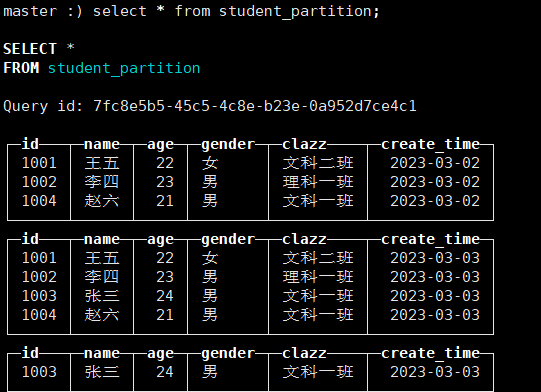
解释:
1.toYYYYMMDD是一个时间格式转换的函数,将数据从'2023-03-03'转换为 20230303 格式
2.PARTITION BY 对数据进行分区,
在表目录中,会根据分区字段将不同的数据分别存放在不同的子目录中,
通过对数据进行分区操作,那么在做数据查询时比如:
SELECT * FROM student_partition WHERE create_time = '2023-03-03'
时,那么只需要去加载如下目录即可:
20230303_1_1_0
20230303_2_2_0
可以提高查询效率
3.PARTITION BY 之后跟的是一个表达式,为具体的函数比如toYYYYMMDD
4.当数据分两次插入时,会形成如下格式:
原因是:在MergeTree引擎中,每次插入数据都不会对数据进行做合并操作,
插入的数据会形成新的分区,按照合并逻辑,对于如下文件
drwxr-x---. 2 clickhouse clickhouse 203 3月 3 15:51 20230302_3_3_0
drwxr-x---. 2 clickhouse clickhouse 203 3月 3 15:51 20230303_1_1_0
drwxr-x---. 2 clickhouse clickhouse 203 3月 3 15:51 20230303_2_2_0
应该会生成两个日期的目录 分别为 20230302 和 20230303 但是现在有三个,
是因为在后插入数据时,不会将新插入的数据,合并到之前的目录中。
当 MergeTree引擎 在15-20分钟之后会对表中的数据进行自动合并,之后就会有两个目录
手动合并:
OPTIMIZE TABLE student_partition FINAL
手动合并时,会在表的目录中,对应生成新的数据目录
drwxr-x---. 2 clickhouse clickhouse 203 3月 4 09:22 20230303_1_2_1
drwxr-x---. 2 clickhouse clickhouse 203 3月 4 09:22 20230302_3_3_1
在 20230303_1_2_1 目录名称中 包含为 分区值_合并前最小标记数_合并前最大标记数_合并次数
当手动合并完成之后,会间隔一段时间,再将之前的数据删除
PRIMARY KEY
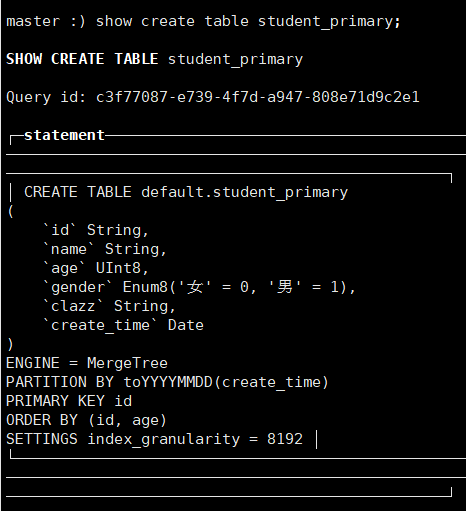
CREATE TABLE student_primary(
id String,
name String,
age UInt8,
gender Enum('男'=1,'女' = 0),
clazz String,
create_time Date
)ENGINE = MergeTree()
ORDER BY (id,age)
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id;间隔粒度:
SETTINGS index_granularity = 8192 //每隔8192个id建立一个索引(根据主键来建立)
INSERT INTO student_primary values('1003','张三',24,1,'文科一班','2023-03-03'),
('1002','李四',23,1,'理科一班','2023-03-03'),
('1001','王五',22,0,'文科二班','2023-03-03'),
('1004','赵六',21,1,'文科一班','2023-03-03');
INSERT INTO student_primary values('1003','张三',24,1,'文科一班','2023-03-03'),
('1002','李四',23,1,'理科一班','2023-03-02'),
('1001','王五',22,0,'文科二班','2023-03-02'),
('1004','赵六',21,1,'文科一班','2023-03-02');OPTIMIZE TABLE student_primary FINAL;
对于ORDER BY来说,如果没有分区,那么是全局有序,如果有分区,那么是分区内有序。
TTL
设置当前表的生命周期,可以添加在字段后,也可以添加在表中。
1.添加在字段后
CREATE TABLE student_ttl(
id String,
name String,
age UInt8,
gender Enum('男'=1,'女' = 0),
clazz String TTL create_time + INTERVAL 20 Second,
create_time DateTime
)ENGINE = MergeTree()
ORDER BY (id,age)
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id插入数据:
INSERT INTO student_ttl values('1003','张三',24,1,'文科一班','2023-03-06 17:00:00');
在还没到17:00:20查看数据,如下:
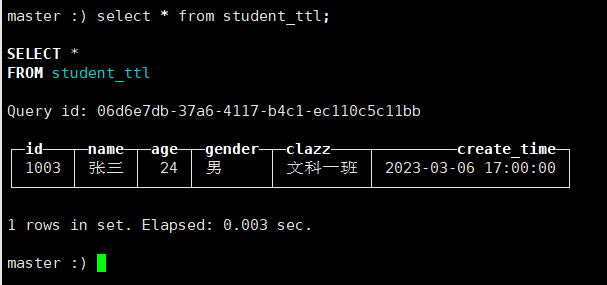
到了这个时间,发现clazz已经没有了。
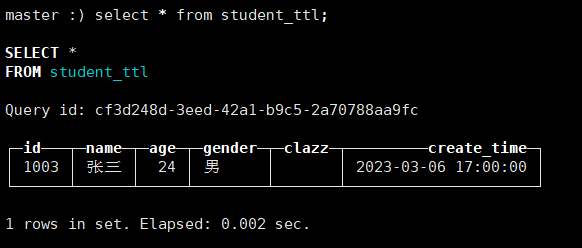
如果添加在列中 当对应列的数据达到表达式的指定时间,那么该列数据会被删除
2.添加在表中
CREATE TABLE student_ttl2(
id String,
name String,
age UInt8,
gender Enum('男'=1,'女' = 0),
clazz String ,
create_time DateTime
)ENGINE = MergeTree()
ORDER BY (id,age)
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
TTL create_time + INTERVAL 20 Second;插入数据:
INSERT INTO student_ttl2 values('1003','张三',24,1,'文科一班','2023-03-06 17:07:00');
在还没到17:07:20查看数据,如下:
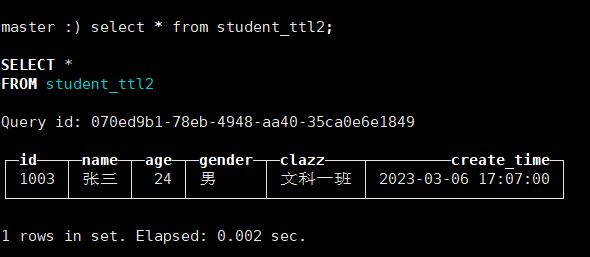
到了这个时间
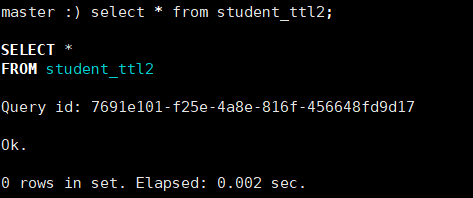
如果添加在表中 当达到表达式时间,那么对应整条数据会被删除
应用场景:
可以通过该方式,定期对表中过期的数据进行删除
INDEX索引
创建索引的目的是对于索引列做查询过滤时,可以提升速度
CREATE TABLE student_index(
id String,
name String,
age UInt8,
gender Enum('男'=1,'女' = 0),
clazz String,
create_time Date,
INDEX age_index (age) TYPE minmax GRANULARITY 2
)ENGINE = MergeTree()
ORDER BY (id,age)
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id ;INSERT INTO student_index values('1003','张三',24,1,'文科一班','2023-03-04')
,('1003','张三',25,1,'文科一班','2023-03-04')
,('1003','张三',26,1,'文科一班','2023-03-04')
,('1003','张三',27,1,'文科一班','2023-03-04')
,('1003','张三',28,1,'文科一班','2023-03-04')3.3 ReplacingMergeTree 引擎
对于MergeTree引擎来说,并不能对字段进行去重重复值,或者限定字段值唯一
那么如果要实现该功能 可以通过 ReplacingMergeTree 引擎实现
建表语句:
CREATE TABLE myFirstReplacingMT
(
key Int64,
someCol String,
eventTime DateTime
)
ENGINE = ReplacingMergeTree
ORDER BY key;插入语句:
INSERT INTO myFirstReplacingMT Values (1, 'first', '2020-01-01 01:01:01');插入俩遍上述语句
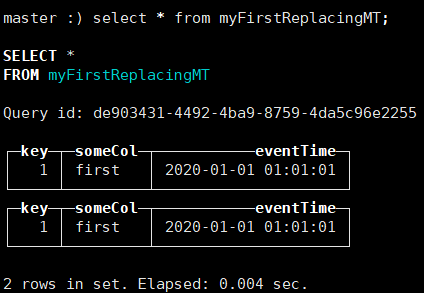
由上图可知
-- 当连续插入两条相同数据时,对于myFirstReplacingMT表来说,并没有起到合并的效果
-- 因为 ReplacingMergeTree 引擎 是定期对数据进行去重。
手动合并 OPTIMIZE TABLE myFirstReplacingMT FINAL;
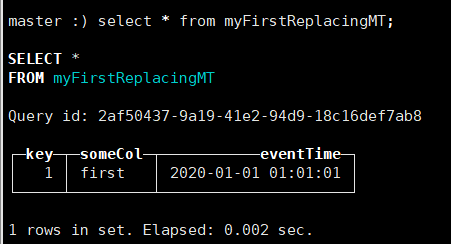
-- 通过插入下面这条数据,并手动合并之后,
INSERT INTO myFirstReplacingMT Values (1, 'first2', '2020-01-02 01:01:01');-- 可以看出,合并的依据是Key列,并且最新插入的数据会覆盖原先的数据
-- 可以得到 ReplacingMergeTree 合并依据是按照ORDER BY提供的列信息进行合并
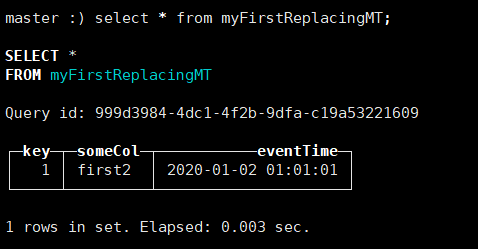
-- 应用场景:对于业务数据,有些需要对数据内容进行更新,可以用该方式实现
-- 注意:ReplacingMergeTree 并不能一定保证当前表中的数据是一定不重复的
3.4 SummingMergeTree引擎
CREATE TABLE comsumer_count
(
comsumer_id String COMMENT '消费ID',
shop_id String COMMENT '商店ID',
count Int64 COMMENT '消费额度',
comsumer_date Date COMMENT '消费日期'
)
ENGINE = SummingMergeTree
ORDER BY (shop_id, comsumer_date)INSERT INTO comsumer_count values ('0001','shop_1',1000,'2023-03-04'),
('0002','shop_1',1000,'2023-03-03'),
('0003','shop_2',2000,'2023-03-04'),
('0004','shop_2',3000,'2023-03-04'),
('0005','shop_1',4000,'2023-03-03'),
('0006','shop_1',4000,'2023-03-04');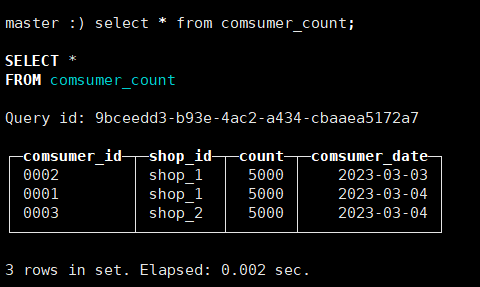
求和的依据是order by后的属性
INSERT INTO comsumer_count values ('0007','shop_1',1000,'2023-03-04'),
('0008','shop_1',1000,'2023-03-03'),
('0009','shop_2',2000,'2023-03-04'),
('0010','shop_2',3000,'2023-03-04'),
('0011','shop_1',4000,'2023-03-03'),
('0012','shop_1',4000,'2023-03-04'); 
分俩次插入数据,发现插入的数据并未合并
通过手动合并
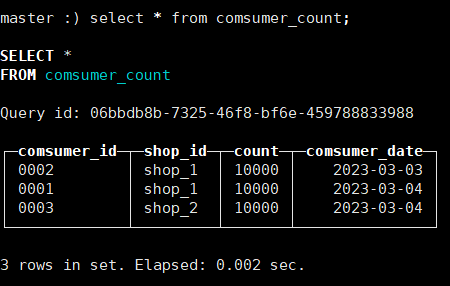
-- SummingMergeTree引擎 主要用于对ORDER BY中的列进行分组聚合,
-- 每次插入一批数据,会对该批次数据做轻量的聚合 ,
-- 但是SummingMergeTree引擎并不会保证所有的数据都已经聚合完成
-- 在查询数据时,依旧需要对数据做分组 求和 GROUP BY SUM操作
-- 优点: 通过SummingMergeTree引擎 可以对一部分数据提前做聚合,
-- 减少后续SELECT 查询时的数据量,从而提升整体的查询效率
-- 注意:SummingMergeTree引擎并不能保证所有的数据已经聚合完成,需要定期执行合并聚合操作
3.5 Memory引擎
建表语句
CREATE TABLE memory_table
(
comsumer_id String COMMENT '消费ID',
shop_id String COMMENT '商店ID',
count Int64 COMMENT '消费额度',
comsumer_date Date COMMENT '消费日期'
)
ENGINE = Memory插入语句
INSERT INTO memory_table values ('0007','shop_1',1000,'2023-03-04'),
('0008','shop_1',1000,'2023-03-03'),
('0009','shop_2',2000,'2023-03-04'),
('0010','shop_2',3000,'2023-03-04'),
('0011','shop_1',4000,'2023-03-03'),
('0012','shop_1',4000,'2023-03-04');查找表
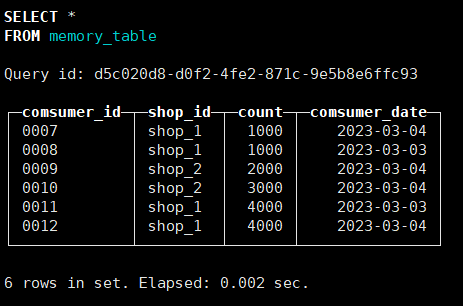
重启clickhouse发现其中没有数据。
-- 该引擎会将所有数据存放至内存当中,并且当CLickHouse重启服务后,所有的数据都会丢失。
-- 应用场景: 对于小批量数据做高频快速查询,可以将该部分数据加载至内存当中做数据的缓存
4.SQL语法
4.1 WITH语句
1.需求:查询每个商店每天净利润大于15000的商店
首先,在3.5中的memory_table表中插入三条数据,插入后如图
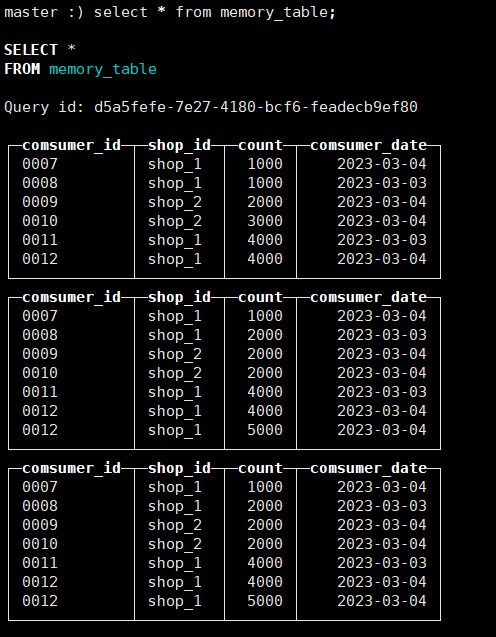
将上图数据库中的数据按照comsumer_id和shop_id进行分组得到的结果如图:
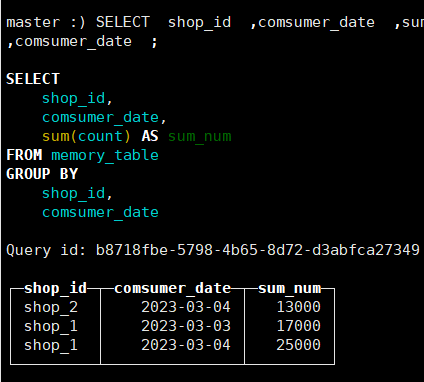
使用with...as将上图得到的数据查询结果作为一张表,从中得到总和大于15000的数据
WITH shop_id_every_count_tbl AS (
SELECT
shop_id
,comsumer_date
,sum(count) as sum_num
FROM memory_table
GROUP BY shop_id,comsumer_date
)
SELECT
*
FROM shop_id_every_count_tbl
WHERE sum_num > 15000得到结果如下:
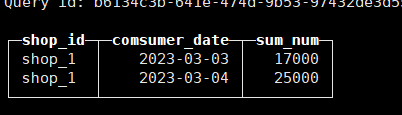
2.需求:查询每个商店每天净利润大于所有商店平均每天销售额一半
WITH shop_id_every_count_tbl AS (
SELECT
shop_id
,comsumer_date
,sum(count) as sum_num
FROM memory_table
GROUP BY shop_id,comsumer_date
)
,total_every_count_tbl AS (
SELECT
comsumer_date
,sum(count)/2 as all_sum_num
FROM memory_table
GROUP BY comsumer_date
)
SELECT
T1.*
,T2.all_sum_num
FROM shop_id_every_count_tbl T1
JOIN total_every_count_tbl T2 ON T1.comsumer_date = T2.comsumer_date
WHERE T1.sum_num > T2.all_sum_num将每天的净利润作为一张表,所有商店平均每天销售额一半作为一张表,通过comsumer_date进行连接,得到净利润大于销售额一般的结果。
-- WITH AS 用法: 可以将查询到的数据保存成一个临时表,加载至内存当中,
-- 并且在SELECT整个SQL查询结束后注销,通常应用在一个子查询数据被重复使用时,
-- 可以用该用法,避免重复计算
4.2 多维分析
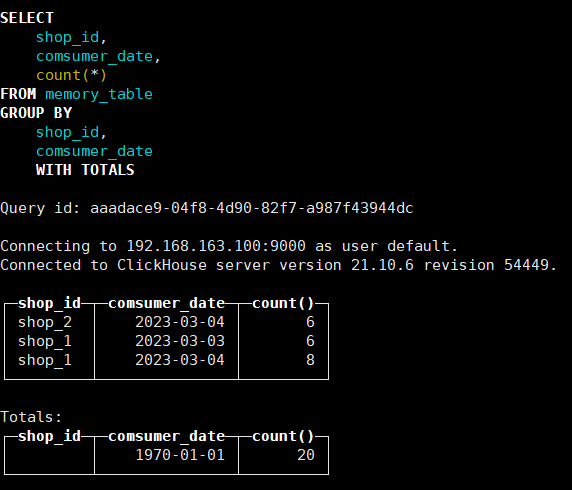
WITH TOTALS 用法:
SELECT
shop_id,comsumer_date,count(*)
FROM memory_table
GROUP BY shop_id,comsumer_date WITH TOTALS;统计总数:
CUBE是对GROUP BY中的字段重新组合并做计算
SELECT
shop_id,comsumer_date,count(*)
FROM memory_table
GROUP BY shop_id,comsumer_date WITH CUBE;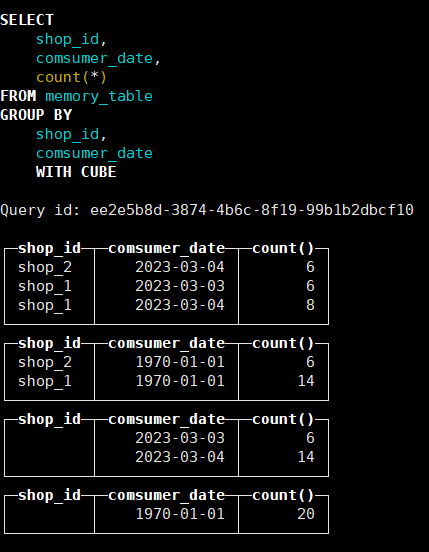
4.3 join
注意:虽然CLickHouse中对Join是有支持的,但是在通常情况下,最好不要频繁使用JOIN操作
JOIN 操作在ClickHouse中效率较低,对于ClickHouse来说,其存储数据方式为列式存储,而Join
是对字段进行判别,取其中行的数据进行比较。那么对于一些经常关联的数据,可以提前关联并将数据
保存至表中,形成一张宽表
4.4 LIMIT
LIMIT 行数N BY 分组字段 :从每个分组字段中取前N行数据
SELECT
*
FROM memory_table
ORDER BY shop_id,comsumer_date
Limit 2 BY shop_idLIMIT M, 行数N BY 分组字段 :从每个分组字段中跳过前M行,取N行数据
SELECT
*
FROM memory_table
ORDER BY shop_id,comsumer_date
Limit 1,2 BY shop_id4.5 判断函数
IF
SELECT
comsumer_id
,shop_id
,count
,IF(count >= 5000,'合格','不合格') AS flag
FROM memory_table CASE
SELECT
count
,CASE WHEN count >=10000 THEN '销售冠军' WHEN count >= 5000 THEN '合格' ELSE '不合格' END
FROM memory_table
MultiIF
SELECT
count
,multiIf(count >=10000,'销售冠军',count >= 5000,'合格','不合格')
FROM memory_table4.6 更新和删除
-- 对于大数据开发过程中,数据的更新和删除操作较少
删除
ALTER TABLE [db.]table [ON CLUSTER cluster] DELETE WHERE filter_expr
-- 在ClickHouse中对数据进行删除操作,会比较重,其是将当前分区中的数据进行标记,之后再对数据进行清除
-- 一般来说ClickHouse不适合删除其中部分数据
ALTER TABLE student_primary DELETE WHERE create_time = '2023-03-04';更新
-- 更新操作,对于Clickhouse来说,数据的更新相对比较重,因为一旦做数据更新后,就会重新对该分区中的数据
-- 进行重新写入,并在间隔一段时间后,将过期数据进行删除。不推荐使用
-- 注意: 修改的字段不能是关键字段: 分区字段、主键字段、排序字段
ALTER TABLE [db.]table UPDATE column1 = expr1 [, ...] WHERE filter_expr
ALTER TABLE student_primary UPDATE gender=1 WHERE id = '1001' ;5 数据导入导出
5.1 数据导出
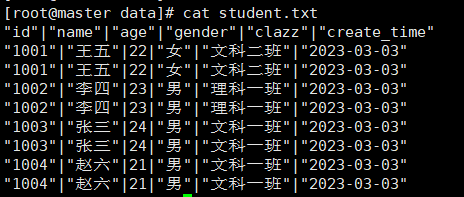
clickhouse-client --password 123456 -d default -q "select * from student FORMAT CSVWithNames" --format_csv_delimiter='|' > /usr/local/soft/data/student.txt
将default数据库中的student表里数据通过csv的格式导入到/usr/local/soft/data/student.txt文件中,分隔符为‘|’
参数:
--format_csv_delimiter 表示字段间的分隔符
-q 表示查询语句 FORMAT CSVWithNames 表示格式中带有字段名称 如果不携带 可以使用 FORMAT CSV
-d 表示数据库

5.2 数据导入
clickhouse-client --password 123456 -d default -q " insert into student FORMAT CSVWithNames" --format_csv_delimiter='|' < /usr/local/soft/data/student.txt
5.3 数据插入
当Mysql中的数据通过数据库引擎连接后,可以直接使用 数据插入方式将数据导入到ClickHose中 将查询的结果创建成一个ClickHouse中的表
CREATE TABLE [IF NOT EXISTS] [db.]table_name[(name1 [type1], name2 [type2], ...)] ENGINE = engine AS SELECT ...
//使用引擎连接mysql数据库
CREATE DATABASE my_mysql_bigdata21 ENGINE = MySQL('192.168.253.80:3306','bigdata21','root','123456');
//将mysql中student表中的内容导入clickhouse中
CREATE TABLE default.mysql_student ENGINE = TinyLog AS SELECT * FROM my_mysql_bigdata21.student;
CREATE TABLE default.dept ENGINE = Memory AS SELECT * FROM my_mysql_bigdata21.dept; 
-- 将1000万条数据插入至ClickHose中
clickhouse-client --password 123456 -d default -q " insert into cars FORMAT CSV" --format_csv_delimiter=',' < /usr/local/soft/data/cars.csv
CREATE TABLE cars (
kkbh String,
clbh String,
jgsj String,
kkjd String,
kkwd String,
cs String,
ccm String,
dlm String,
qxm String
)
ENGINE = MergeTree
ORDER BY (kkbh,ccm)
PARTITION BY ccm
经过对比,ClickHouse 在做Count(*) FROM 表时,对应速度达到 0.009毫秒 而Mysql时间在 2s左右
SELECT
count(*)
FROM (
SELECT
kkbh
FROM cars GROUP BY kkbh
)
同样的SQL在ClickHose中查询,对应的速度为 0.1秒 而Mysql中需要 4秒
需求: 对于各部门中薪资排名第二的员工
SELECT
DEPTNO,EMPNO,SAL
FROM my_mysql_bigdata21.emp
ORDER BY DEPTNO,SAL desc
LIMIT 1,1 BY DEPTNO6 clickhouse连接python
# pip install clickhouse_driver
from clickhouse_driver import Client
client = Client(host='192.168.253.100', port=9000, password='123456',database='default')
# 结果为列表类型,对应每一条数据为一个tuple
res = client.execute("SELECT * FROM student limit 100")
for row in res:
print(row[1],row[4])

















 2463
2463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









