






机器学习——决策树
一、决策树相关介绍
1、简介
决策树顾名思义就是一棵用来进行决策的树,是一种以树结构形式表达的预测分析模型。由结点和有向边组成;结点有两种类型:内部节点(表示一个特征或属性)和叶子节点(表示一个类)。
用决策树进行分类,从根结点开始,对实例的某一个特征进行测试,根据测试结果分配往对应的子结点中去,每个子结点对应一个特征的取值,递归的进行分类测试和分配,最终到达对应的叶结点。(if-then规则的集合)
2、实例
人生处处都是决策树,比如高考填志愿,会对一个学校一个专业提出多个问题,根据问题的不同答案有不同的选择。(简略版)当你看到福建厦门的集美大学智能科学与技术专业的时候首先想:对专业感不感兴趣——不感兴趣就继续往下考虑,感兴趣也继续往下考虑;专业前景怎么样——不好pass,好继续考虑;所在的大学集美大学好不好——不好pass,好就继续往下考虑;所在的城市厦门好不好——不好pass,好就产生最后结果——最终决定填报厦门集美大学的智能科学与技术专业。
其中一部分树: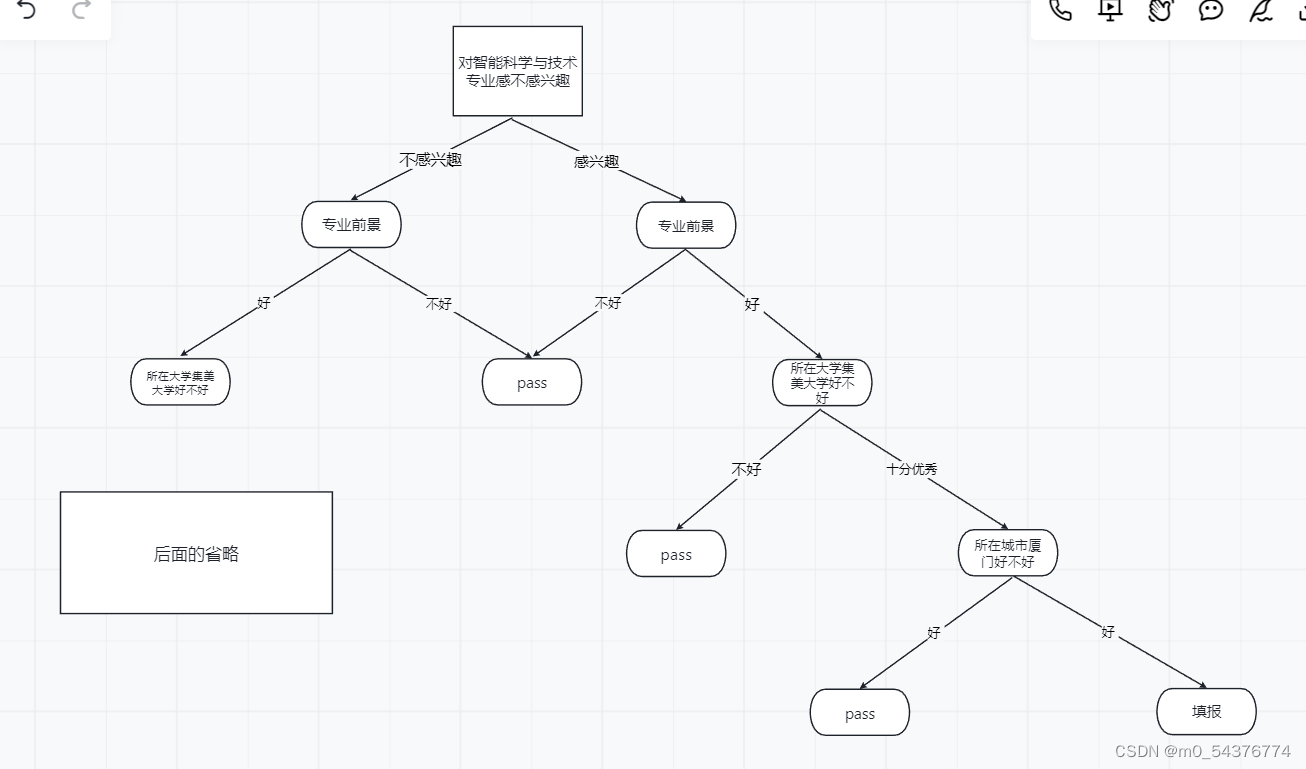
3、一般流程
- 收集数据:可以使用任何方法
- 准备数据:树构造算法只适用于标称型数据,因此数值型数据必须离散化
- 分析数据:可以使用任何方法,构造树完成之后,我们应该检查图形是否符合预期
- 训练算法:构造树的数据结构
- 测试算法:使用经验树计算错误率
- 使用算法:此步骤可以适用于任何监督学习算法,而使用决策树可以更好地理解数据的内在含义
4、学习过程
-
特征选择: 特征选择是指从训练数据中众多的特征中选择一个特征作为当前节点的分裂标准,如何选择特征有着很多不同量化评估标准标准,从而衍生出不同的决策树算法。
-
决策树生成: 根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止生长。 树结构来说,递归结构是最容易理解的方式。
-
剪枝: 决策树容易过拟合,一般来需要剪枝,缩小树结构规模、缓解过拟合。剪枝技术有预剪枝和后剪枝两种。
5、优缺点
- 优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关的特征数据。
- 缺点:可能会产生过度匹配(过拟合)的问题
- 适用数据类型:数值型和标称型
6、划分选择
决策树学习的关键在于如何选择最优划分属性。那我们用什么方法来划分属性呢?有以下三种经典的方法:
- 信息增益:ID3算法
- 增益率:C4.5算法
- 基尼指数:CART算法
(1)信息增益
- 信息熵
表示随机变量不确定性的度量,即物体的混乱程度
度量样本集合纯度最常用的一种指标,假定当前样本集合D中第k类样本所占的比例为pk (K=1, 2, …, |y|),则D的信息熵定义为
Ent(D)的值越小,则D的纯度越高
p=0,则plog2p=0
Ent(D)的最小值为0,最大值为log2|y|

- 信息增益
划分数据集之前之后信息发生的变化称之为信息增益,是计算分支属性对于样本集分类好坏程度的度量
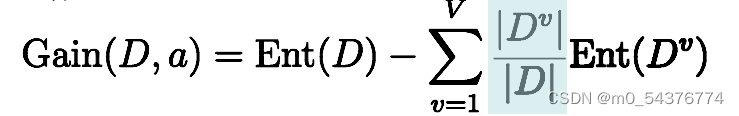
一般来说,信息增益越大,使用该属性来进行划分所获得的“纯度提升”越大,即效果越好。选择信息增益最大的属性作为划分属性。
与信息熵的关系:信息增益越大,信息的不确定性越小,信息熵是度量信息混乱程度的,因此信息熵越大,信息的的不确定性越大。
(2)增益率

先从候选划分属性中找出信息增益高于平均水平的属性,再从中选取增益率最高的
(3)基尼指数
表示在样本集合中一个随机选中的样本被分错的概率。基尼指数越小,表示集合中被选中的样本被分错的概率越小,集合的纯度越高。所以选择使得划分后基尼指数最小的属性作为最有划分属性

二、代码实现(决策树的创建与使用决策树进行分类,展示创建的决策树)
1、代码
1. 开始导包
import math
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rc("font", family='Microsoft YaHei')
2. 创建数据集
def createDataXG20():
data = np.array([['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑']
, ['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑']
, ['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑']
, ['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑']
, ['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑']
, ['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘']
, ['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘']
, ['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑']
, ['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑']
, ['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘']
, ['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑']
, ['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘']
, ['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑']
, ['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑']
, ['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘']
, ['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑']
, ['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑']])
label = np.array(['是', '是', '是', '是', '是', '是', '是', '是', '否', '否', '否', '否', '否', '否', '否', '否', '否'])
name = np.array(['色泽', '根蒂', '敲声', '纹理', '脐部', '触感'])
return data, label, name
def splitXgData20(xgData, xgLabel):
xgDataTrain = xgData[[0, 1, 2, 5, 6, 9, 13, 14, 15, 16],:]
xgDataTest = xgData[[3, 4, 7, 8, 10, 11, 12],:]
xgLabelTrain = xgLabel[[0, 1, 2, 5, 6, 9, 13, 14, 15, 16]]
xgLabelTest = xgLabel[[3, 4, 7, 8, 10, 11, 12]]
return xgDataTrain, xgLabelTrain, xgDataTest, xgLabelTes
3.创建基础函数
(1)定义计算信息熵和条件信息熵的函数
# 定义一个常用函数 用来求numpy array中数值等于某值的元素数量
equalNums = lambda x,y: 0 if x is None else x[x==y].size
# 定义计算信息熵的函数
def singleEntropy(x):
"""计算一个输入序列的信息熵"""
# 转换为 numpy 矩阵
x = np.asarray(x)
# 取所有不同值
xValues = set(x)
# 计算熵值
entropy = 0
for xValue in xValues:
p = equalNums(x, xValue) / x.size
entropy -= p * math.log(p, 2)
return entropy
# 定义计算条件信息熵的函数
def conditionnalEntropy(feature, y):
"""计算 某特征feature 条件下y的信息熵"""
# 转换为numpy
feature = np.asarray(feature)
y = np.asarray(y)
# 取特征的不同值
featureValues = set(feature)
# 计算熵值
entropy = 0
for feat in featureValues:
# 解释:feature == feat 是得到取feature中所有元素值等于feat的元素的索引(类似这样理解)
# y[feature == feat] 是取y中 feature元素值等于feat的元素索引的 y的元素的子集
p = equalNums(feature, feat) / feature.size
entropy += p * singleEntropy(y[feature == feat])
return entropy
(2)信息增益
# 定义信息增益
def infoGain(feature, y):
return singleEntropy(y) - conditionnalEntropy(feature, y)
# 定义信息增益率
def infoGainRatio(feature, y):
return 0 if singleEntropy(feature) == 0 else infoGain(feature, y) / singleEntropy(feature)
4. 创建决策树生成相关函数(特征选取、数据分割、树生成等)
# 特征选取
def bestFeature(data, labels, method = 'id3'):
assert method in ['id3', 'c45'], "method 须为id3或c45"
data = np.asarray(data)
labels = np.asarray(labels)
# 根据输入的method选取 评估特征的方法:id3 -> 信息增益; c45 -> 信息增益率
def calcEnt(feature, labels):
if method == 'id3':
return infoGain(feature, labels)
elif method == 'c45' :
return infoGainRatio(feature, labels)
# 特征数量 即 data 的列数量
featureNum = data.shape[1]
# 计算最佳特征
bestEnt = 0
bestFeat = -1
for feature in range(featureNum):
ent = calcEnt(data[:, feature], labels)
if ent >= bestEnt:
bestEnt = ent
bestFeat = feature
# print("feature " + str(feature + 1) + " ent: " + str(ent)+ "\t bestEnt: " + str(bestEnt))
return bestFeat, bestEnt
# 根据特征及特征值分割原数据集 删除data中的feature列,并根据feature列中的值分割 data和label
def splitFeatureData(data, labels, feature):
"""feature 为特征列的索引"""
# 取特征列
features = np.asarray(data)[:,feature]
# 数据集中删除特征列
data = np.delete(np.asarray(data), feature, axis = 1)
# 标签
labels = np.asarray(labels)
uniqFeatures = set(features)
dataSet = {}
labelSet = {}
for feat in uniqFeatures:
dataSet[feat] = data[features == feat]
labelSet[feat] = labels[features == feat]
return dataSet, labelSet
# 多数投票
def voteLabel(labels):
uniqLabels = list(set(labels))
labels = np.asarray(labels)
finalLabel = 0
labelNum = []
for label in uniqLabels:
# 统计每个标签值得数量
labelNum.append(equalNums(labels, label))
# 返回数量最大的标签
return uniqLabels[labelNum.index(max(labelNum))]
# 创建决策树
def createTree(data, labels, names, method = 'id3'):
data = np.asarray(data)
labels = np.asarray(labels)
names = np.asarray(names)
# 如果结果为单一结果
if len(set(labels)) == 1:
return labels[0]
# 如果没有待分类特征
elif data.size == 0:
return voteLabel(labels)
# 其他情况则选取特征
bestFeat, bestEnt = bestFeature(data, labels, method = method)
# 取特征名称
bestFeatName = names[bestFeat]
# 从特征名称列表删除已取得特征名称
names = np.delete(names, [bestFeat])
# 根据选取的特征名称创建树节点
decisionTree = {bestFeatName: {}}
# 根据最优特征进行分割
dataSet, labelSet = splitFeatureData(data, labels, bestFeat)
# 对最优特征的每个特征值所分的数据子集进行计算
for featValue in dataSet.keys():
decisionTree[bestFeatName][featValue] = createTree(dataSet.get(featValue), labelSet.get(featValue), names, method)
return decisionTree
# 树信息统计 叶子节点数量 和 树深度
def getTreeSize(decisionTree):
nodeName = list(decisionTree.keys())[0]
nodeValue = decisionTree[nodeName]
leafNum = 0
treeDepth = 0
leafDepth = 0
for val in nodeValue.keys():
if type(nodeValue[val]) == dict:
leafNum += getTreeSize(nodeValue[val])[0]
leafDepth = 1 + getTreeSize(nodeValue[val])[1]
else :
leafNum += 1
leafDepth = 1
treeDepth = max(treeDepth, leafDepth)
return leafNum, treeDepth
# 使用模型对其他数据分类
def dtClassify(decisionTree, rowData, names):
names = list(names)
# 获取特征
feature = list(decisionTree.keys())[0]
# 决策树对于该特征的值的判断字段
featDict = decisionTree[feature]
# 获取特征的列
feat = names.index(feature)
# 获取数据该特征的值
featVal = rowData[feat]
# 根据特征值查找结果,如果结果是字典说明是子树,调用本函数递归
if featVal in featDict.keys():
if type(featDict[featVal]) == dict:
classLabel = dtClassify(featDict[featVal], rowData, names)
else:
classLabel = featDict[featVal]
return classLabel
5. 树可视化
import matplotlib.pyplot as plt
decisionNodeStyle = dict(boxstyle = "sawtooth", fc = "0.8")
leafNodeStyle = {"boxstyle": "round4", "fc": "0.8"}
arrowArgs = {"arrowstyle": "<-"}
# 画节点
def plotNode(nodeText, centerPt, parentPt, nodeStyle):
createPlot.ax1.annotate(nodeText, xy = parentPt, xycoords = "axes fraction", xytext = centerPt
, textcoords = "axes fraction", va = "center", ha="center", bbox = nodeStyle, arrowprops = arrowArgs)
# 添加箭头上的标注文字
def plotMidText(centerPt, parentPt, lineText):
xMid = (centerPt[0] + parentPt[0]) / 2.0
yMid = (centerPt[1] + parentPt[1]) / 2.0
createPlot.ax1.text(xMid, yMid, lineText)
# 画树
def plotTree(decisionTree, parentPt, parentValue):
# 计算宽与高
leafNum, treeDepth = getTreeSize(decisionTree)
# 在 1 * 1 的范围内画图,因此分母为 1
# 每个叶节点之间的偏移量
plotTree.xOff = plotTree.figSize / (plotTree.totalLeaf - 1)
# 每一层的高度偏移量
plotTree.yOff = plotTree.figSize / plotTree.totalDepth
# 节点名称
nodeName = list(decisionTree.keys())[0]
# 根节点的起止点相同,可避免画线;如果是中间节点,则从当前叶节点的位置开始,
# 然后加上本次子树的宽度的一半,则为决策节点的横向位置
centerPt = (plotTree.x + (leafNum - 1) * plotTree.xOff / 2.0, plotTree.y)
# 画出该决策节点
plotNode(nodeName, centerPt, parentPt, decisionNodeStyle)
# 标记本节点对应父节点的属性值
plotMidText(centerPt, parentPt, parentValue)
# 取本节点的属性值
treeValue = decisionTree[nodeName]
# 下一层各节点的高度
plotTree.y = plotTree.y - plotTree.yOff
# 绘制下一层
for val in treeValue.keys():
# 如果属性值对应的是字典,说明是子树,进行递归调用; 否则则为叶子节点
if type(treeValue[val]) == dict:
plotTree(treeValue[val], centerPt, str(val))
else:
plotNode(treeValue[val], (plotTree.x, plotTree.y), centerPt, leafNodeStyle)
plotMidText((plotTree.x, plotTree.y), centerPt, str(val))
# 移到下一个叶子节点
plotTree.x = plotTree.x + plotTree.xOff
# 递归完成后返回上一层
plotTree.y = plotTree.y + plotTree.yOff
# 画出决策树
def createPlot(decisionTree):
fig = plt.figure(1, facecolor = "white")
fig.clf()
axprops = {"xticks": [], "yticks": []}
createPlot.ax1 = plt.subplot(111, frameon = False, **axprops)
# 定义画图的图形尺寸
plotTree.figSize = 1.5
# 初始化树的总大小
plotTree.totalLeaf, plotTree.totalDepth = getTreeSize(decisionTree)
# 叶子节点的初始位置x 和 根节点的初始层高度y
plotTree.x = 0
plotTree.y = plotTree.figSize
plotTree(decisionTree, (plotTree.figSize / 2.0, plotTree.y), "")
plt.show()
6. 测试
xgData, xgLabel, xgName = createDataXG20()
xgTree = createTree(xgData, xgLabel, xgName, method = 'id3')
print(xgTree)
createPlot(xgTree)
7. 结果

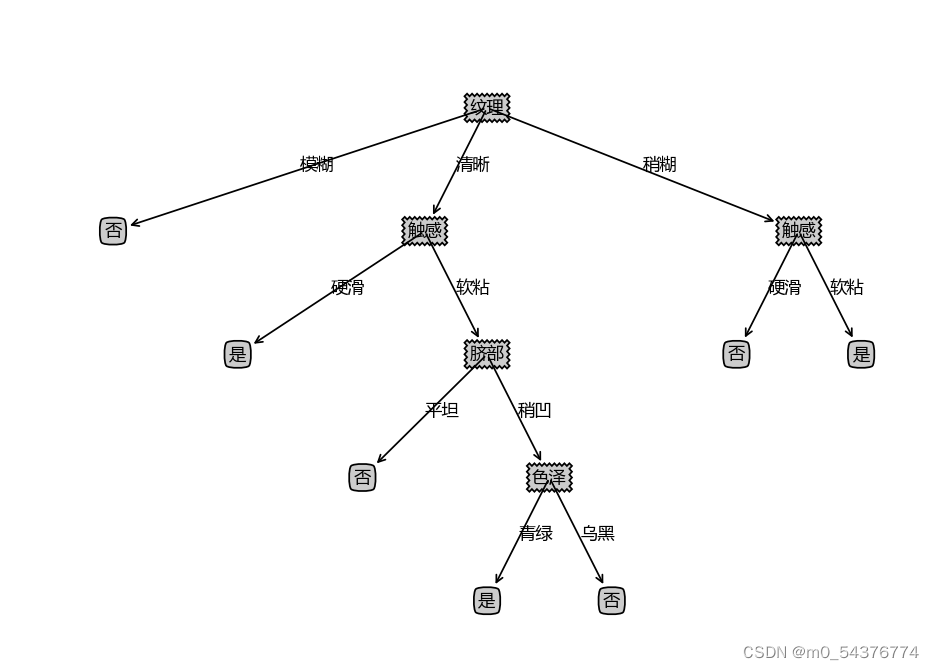
完整代码
import math
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rc("font", family='Microsoft YaHei')
def createDataXG20():
data = np.array([['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑']
, ['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑']
, ['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑']
, ['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑']
, ['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑']
, ['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘']
, ['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘']
, ['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑']
, ['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑']
, ['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘']
, ['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑']
, ['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘']
, ['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑']
, ['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑']
, ['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘']
, ['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑']
, ['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑']])
label = np.array(['是', '是', '是', '是', '是', '是', '是', '是', '否', '否', '否', '否', '否', '否', '否', '否', '否'])
name = np.array(['色泽', '根蒂', '敲声', '纹理', '脐部', '触感'])
return data, label, name
def splitXgData20(xgData, xgLabel):
xgDataTrain = xgData[[0, 1, 2, 5, 6, 9, 13, 14, 15, 16],:]
xgDataTest = xgData[[3, 4, 7, 8, 10, 11, 12],:]
xgLabelTrain = xgLabel[[0, 1, 2, 5, 6, 9, 13, 14, 15, 16]]
xgLabelTest = xgLabel[[3, 4, 7, 8, 10, 11, 12]]
return xgDataTrain, xgLabelTrain, xgDataTest, xgLabelTest
# 定义一个常用函数 用来求numpy array中数值等于某值的元素数量
equalNums = lambda x, y: 0 if x is None else x[x == y].size
# 定义计算信息熵的函数
def singleEntropy(x):
"""计算一个输入序列的信息熵"""
# 转换为 numpy 矩阵
x = np.asarray(x)
# 取所有不同值
xValues = set(x)
# 计算熵值
entropy = 0
for xValue in xValues:
p = equalNums(x, xValue) / x.size
entropy -= p * math.log(p, 2)
return entropy
# 定义计算条件信息熵的函数
def conditionnalEntropy(feature, y):
"""计算 某特征feature 条件下y的信息熵"""
# 转换为numpy
feature = np.asarray(feature)
y = np.asarray(y)
# 取特征的不同值
featureValues = set(feature)
# 计算熵值
entropy = 0
for feat in featureValues:
# 解释:feature == feat 是得到取feature中所有元素值等于feat的元素的索引(类似这样理解)
# y[feature == feat] 是取y中 feature元素值等于feat的元素索引的 y的元素的子集
p = equalNums(feature, feat) / feature.size
entropy += p * singleEntropy(y[feature == feat])
return entropy
# 定义信息增益
def infoGain(feature, y):
return singleEntropy(y) - conditionnalEntropy(feature, y)
# 定义信息增益率
def infoGainRatio(feature, y):
return 0 if singleEntropy(feature) == 0 else infoGain(feature, y) / singleEntropy(feature)
# 特征选取
def bestFeature(data, labels, method='id3'):
assert method in ['id3', 'c45'], "method 须为id3或c45"
data = np.asarray(data)
labels = np.asarray(labels)
# 根据输入的method选取 评估特征的方法:id3 -> 信息增益; c45 -> 信息增益率
def calcEnt(feature, labels):
if method == 'id3':
return infoGain(feature, labels)
elif method == 'c45':
return infoGainRatio(feature, labels)
# 特征数量 即 data 的列数量
featureNum = data.shape[1]
# 计算最佳特征
bestEnt = 0
bestFeat = -1
for feature in range(featureNum):
ent = calcEnt(data[:, feature], labels)
if ent >= bestEnt:
bestEnt = ent
bestFeat = feature
# print("feature " + str(feature + 1) + " ent: " + str(ent)+ "\t bestEnt: " + str(bestEnt))
return bestFeat, bestEnt
# 根据特征及特征值分割原数据集 删除data中的feature列,并根据feature列中的值分割 data和label
def splitFeatureData(data, labels, feature):
"""feature 为特征列的索引"""
# 取特征列
features = np.asarray(data)[:, feature]
# 数据集中删除特征列
data = np.delete(np.asarray(data), feature, axis=1)
# 标签
labels = np.asarray(labels)
uniqFeatures = set(features)
dataSet = {}
labelSet = {}
for feat in uniqFeatures:
dataSet[feat] = data[features == feat]
labelSet[feat] = labels[features == feat]
return dataSet, labelSet
# 多数投票
def voteLabel(labels):
uniqLabels = list(set(labels))
labels = np.asarray(labels)
finalLabel = 0
labelNum = []
for label in uniqLabels:
# 统计每个标签值得数量
labelNum.append(equalNums(labels, label))
# 返回数量最大的标签
return uniqLabels[labelNum.index(max(labelNum))]
# 创建决策树
def createTree(data, labels, names, method='id3'):
data = np.asarray(data)
labels = np.asarray(labels)
names = np.asarray(names)
# 如果结果为单一结果
if len(set(labels)) == 1:
return labels[0]
# 如果没有待分类特征
elif data.size == 0:
return voteLabel(labels)
# 其他情况则选取特征
bestFeat, bestEnt = bestFeature(data, labels, method=method)
# 取特征名称
bestFeatName = names[bestFeat]
# 从特征名称列表删除已取得特征名称
names = np.delete(names, [bestFeat])
# 根据选取的特征名称创建树节点
decisionTree = {bestFeatName: {}}
# 根据最优特征进行分割
dataSet, labelSet = splitFeatureData(data, labels, bestFeat)
# 对最优特征的每个特征值所分的数据子集进行计算
for featValue in dataSet.keys():
decisionTree[bestFeatName][featValue] = createTree(dataSet.get(featValue), labelSet.get(featValue), names,
method)
return decisionTree
# 树信息统计 叶子节点数量 和 树深度
def getTreeSize(decisionTree):
nodeName = list(decisionTree.keys())[0]
nodeValue = decisionTree[nodeName]
leafNum = 0
treeDepth = 0
leafDepth = 0
for val in nodeValue.keys():
if type(nodeValue[val]) == dict:
leafNum += getTreeSize(nodeValue[val])[0]
leafDepth = 1 + getTreeSize(nodeValue[val])[1]
else:
leafNum += 1
leafDepth = 1
treeDepth = max(treeDepth, leafDepth)
return leafNum, treeDepth
# 使用模型对其他数据分类
def dtClassify(decisionTree, rowData, names):
names = list(names)
# 获取特征
feature = list(decisionTree.keys())[0]
# 决策树对于该特征的值的判断字段
featDict = decisionTree[feature]
# 获取特征的列
feat = names.index(feature)
# 获取数据该特征的值
featVal = rowData[feat]
# 根据特征值查找结果,如果结果是字典说明是子树,调用本函数递归
if featVal in featDict.keys():
if type(featDict[featVal]) == dict:
classLabel = dtClassify(featDict[featVal], rowData, names)
else:
classLabel = featDict[featVal]
return classLabel
import matplotlib.pyplot as plt
decisionNodeStyle = dict(boxstyle="sawtooth", fc="0.8")
leafNodeStyle = {"boxstyle": "round4", "fc": "0.8"}
arrowArgs = {"arrowstyle": "<-"}
# 画节点
def plotNode(nodeText, centerPt, parentPt, nodeStyle):
createPlot.ax1.annotate(nodeText, xy=parentPt, xycoords="axes fraction", xytext=centerPt
, textcoords="axes fraction", va="center", ha="center", bbox=nodeStyle,
arrowprops=arrowArgs)
# 添加箭头上的标注文字
def plotMidText(centerPt, parentPt, lineText):
xMid = (centerPt[0] + parentPt[0]) / 2.0
yMid = (centerPt[1] + parentPt[1]) / 2.0
createPlot.ax1.text(xMid, yMid, lineText)
# 画树
def plotTree(decisionTree, parentPt, parentValue):
# 计算宽与高
leafNum, treeDepth = getTreeSize(decisionTree)
# 在 1 * 1 的范围内画图,因此分母为 1
# 每个叶节点之间的偏移量
plotTree.xOff = plotTree.figSize / (plotTree.totalLeaf - 1)
# 每一层的高度偏移量
plotTree.yOff = plotTree.figSize / plotTree.totalDepth
# 节点名称
nodeName = list(decisionTree.keys())[0]
# 根节点的起止点相同,可避免画线;如果是中间节点,则从当前叶节点的位置开始,
# 然后加上本次子树的宽度的一半,则为决策节点的横向位置
centerPt = (plotTree.x + (leafNum - 1) * plotTree.xOff / 2.0, plotTree.y)
# 画出该决策节点
plotNode(nodeName, centerPt, parentPt, decisionNodeStyle)
# 标记本节点对应父节点的属性值
plotMidText(centerPt, parentPt, parentValue)
# 取本节点的属性值
treeValue = decisionTree[nodeName]
# 下一层各节点的高度
plotTree.y = plotTree.y - plotTree.yOff
# 绘制下一层
for val in treeValue.keys():
# 如果属性值对应的是字典,说明是子树,进行递归调用; 否则则为叶子节点
if type(treeValue[val]) == dict:
plotTree(treeValue[val], centerPt, str(val))
else:
plotNode(treeValue[val], (plotTree.x, plotTree.y), centerPt, leafNodeStyle)
plotMidText((plotTree.x, plotTree.y), centerPt, str(val))
# 移到下一个叶子节点
plotTree.x = plotTree.x + plotTree.xOff
# 递归完成后返回上一层
plotTree.y = plotTree.y + plotTree.yOff
# 画出决策树
def createPlot(decisionTree):
fig = plt.figure(1, facecolor="white")
fig.clf()
axprops = {"xticks": [], "yticks": []}
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
# 定义画图的图形尺寸
plotTree.figSize = 1.5
# 初始化树的总大小
plotTree.totalLeaf, plotTree.totalDepth = getTreeSize(decisionTree)
# 叶子节点的初始位置x 和 根节点的初始层高度y
plotTree.x = 0
plotTree.y = plotTree.figSize
plotTree(decisionTree, (plotTree.figSize / 2.0, plotTree.y), "")
plt.show()
plt.rcParams['font.sans-serif'] = ['simHei'] # 指定默认字体
xgData, xgLabel, xgName = createDataXG20()
xgTree = createTree(xgData, xgLabel, xgName, method = 'id3')
print(xgTree)
createPlot(xgTree)
2、注意注意!!(可视化树时出现的问题)

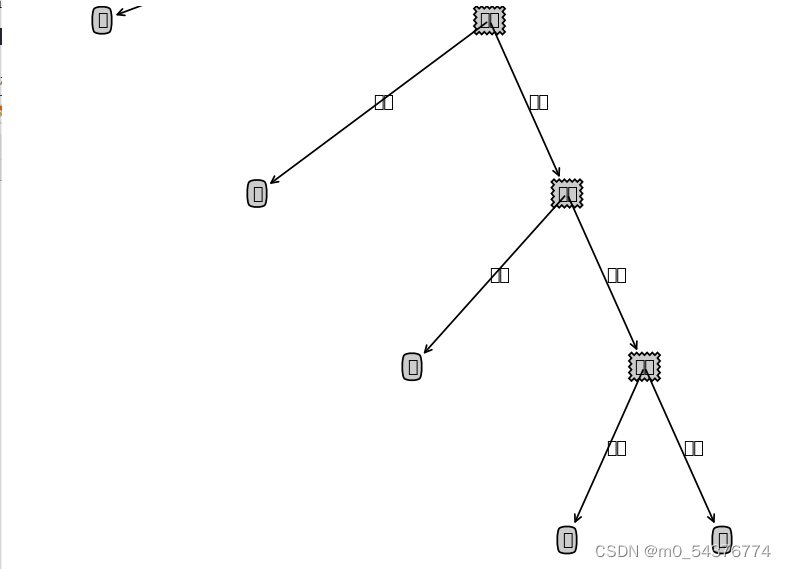
问题:决策树可视化的结果,中文显示不出来
原因:是因为Matplotlib库中没有与所输入的中文字符匹配的语言,所以无法正常显示中文
解决方法:
添加:
import matplotlib
matplotlib.rc("font", family='Microsoft YaHei')`















 1463
1463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









