







视频:GPT,GPT-2,GPT-3 论文精读【论文精读】_哔哩哔哩_bilibili
MAE论文:把bert用回计算机视觉领域
CLIP论文:打通文本和图像
GPT
论文:Improving Language Understanding by Generative Pre-Training
半监督学习:使用没有标号的文本进行预训练一个语言模型,用有标号的数据训练一个微调模型
Bert是Transformer的encoder(既能用前面 也能用后面特征),GPT是Transformer的decoder部分(带掩码的注意力机制,因为任务是预测下一个词,只能用来自前面的特征)
Bert是带掩码的语言模型,完形填空(挖掉中间的词 用上下文来预测该词)
无标号数据上做预训练
目标函数1:

给定 k 个词 预测下一个词,如何预测:

和Bert的区别不只是编码器解码器,更主要的区别是目标函数的选取,GPT的目标函数更难
有标号数据上做微调
标准的分类目标函数2:
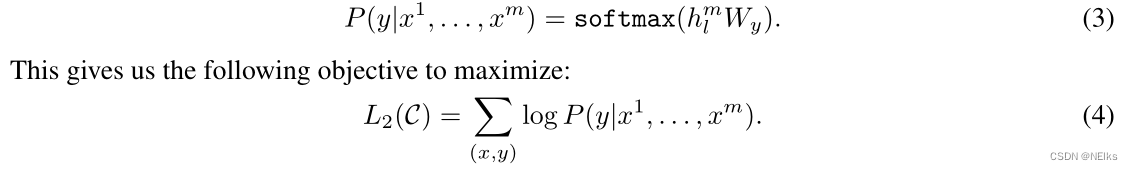
将语言模型作为微调的辅助,得到的目标函数:

接下来考虑怎么把NLP中很多不一样的子任务表示成序列+标号的形式,调整数据而不调整模型,预训练好Transformer模型后 在做下游任务时候不需要改变模型结构(GPT跟以往相比的特点)
实验部分
12层Transformer的decoder 每层维度768(跟bert-base一样)
在预训练语言模型时是在自然文本上训练,但在下游任务时对其输入进行了构造(开始 结束 分隔符)
GPT-2
论文:Language Models are Unsupervised Multitask Learners
改进对每一个下游任务都需要微调(在每一个任务上还要提供部分样本用于训练)的缺点,好处是训练一个模型 在任何地方都能用
zero-shot
做到下游任务时,不需要任何标注信息,也不需要训练模型,使用 prompt
采样策略
预测出下一个词的概率,不一定选择概率最大的 可能希望具有多样性
参数 Temperature、Top k、Top p
Temperature = 1:不变,softmax 选出概率最大的数
Temperature越大,越多样
Top k:采样前k个词
Top p:累加概率 达到该概率就停止采样,一般95%
GPT-3
论文:Language Models are Few-Shot Learners
在做下游任务时不做任何梯度更新
核心的下游任务方式:
- Zero-shot
- One-shot:给出一个参考的问题和回答,要GPT根据给出的参考回答一个新问题
- Few-shot















 3918
3918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









