






1.并行和并发有什么区别?
并行是多个任务在同一个CPU核上,按时间片轮流执行
并发是多个处理器或多核处理器同时执行多个任务
2.创建线程的三种方式
1.继承Thread类(thread实现了runnable接口):重写run方法。用对象实例调用start()方法启动线程
2.实现Runnable接口:重写run()方法,在main()中创建该类实例,作为thread类的构造参数,得到的thread对象才是真正的线程对象,用该对象调用start()方法启动线程
3.实现callable接口:重写call()方法并指定返回值,在main()中先创造该类实例,使用FutureTask包装类来包装callable实例对象,用FutureTask实例作为Thread构造器参数,thread实例调用start启动线程
开发中我们更倾向于使用实现Runnable接口的方式创建线程,因为接口没有类的单继承性的局限性,其次实现接口的方式更适合处理多个线程有共享数据的情况
3.Runnable()和Callable()区别?
- 实现Runnable是重写run方法,Callable()是实现call方法
- Run方法没有返回值,call方法有返回值
- Call方法可以抛出异常,run方法不能抛出异常
- 使用Callable可以获得一个FutureTask对象,通过这个对象可以了解任务执行情况,可以取消任务的执行,还可以获得任务执行的结果
4.线程有几种状态?
线程有5种状态:新建,就绪,运行,阻塞,死亡
新建:当new出一个thread时,线程并未开始运行,此时线程处于一个新建状态
就绪:一个新建线程并不会自动进入运行状态,当调用start()方法之后即启动了线程,start()方法创建了线程运行的系统资源,并调度线程运行run()方法,当start()方法返回后,线程就处于就绪状态。处于就绪状态并不一定会立即执行run(),只有当该线程获得cpu分配的时间后才能执行
运行:线程获得了cpu分配的时间,进入了运行状态,执行run()方法
阻塞:线程在运行过程中遇到下面几种情况会进入阻塞状态
- sleep()方法
- 线程进行的是IO阻塞的操作,即在读写完成之前不会返回
- 线程在等待锁等等
阻塞状态时,该线程会暂时让出cpu,让其他正在就绪状态的线程进入运行状态
死亡:run方法执行结束,线程自然死亡;也可能是由于出现异常终止了run方法
Sleep()和wait()的区别?
Sleep()是Thread类提供的方法,wait()是Object类提供的方法。Sleep会让线程休眠,但不会释放锁;wait会让线程等待,会释放锁。Sleep后线程进入阻塞状态,wait后线程进入就绪状态
线程安全问题:同一时间多个线程访问同一数据,会导致数据的混乱,想解决线程安全问题通常有两种方式:锁(Synchronized重量级锁和lock)和volatile关键字
Volatile关键字
首先先看一下指令重排序的定义,指令重排序,主要是为了优化代码执行效率,一般分为三种类型的重排序:编译器优化重排序,指令并行重排序,内存指令优化重排序。重排序必须保证在单线程的情况下,执行的结果和重排之前的结果要一致,在多线程条件下不能保证结果正确
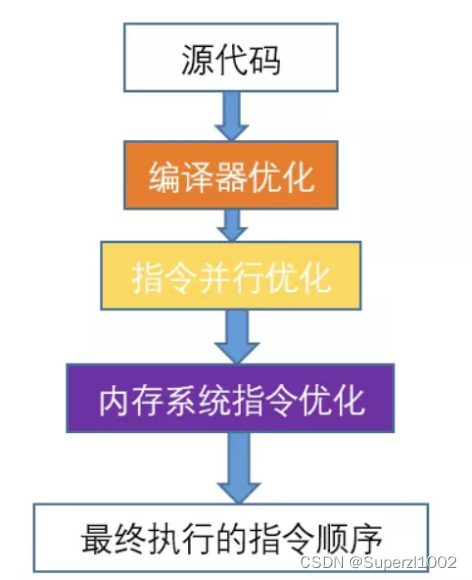
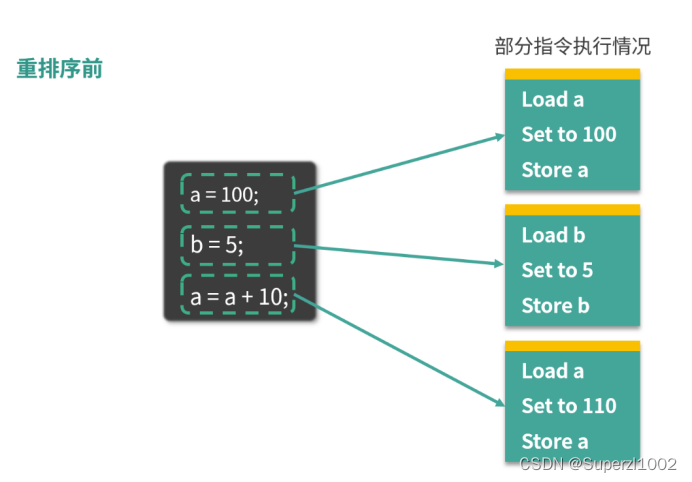
这里给出一个重排序的实例

并发的三个基本概念:
- 原子性:即一个操作要么执行完成要么不执行,不会卡在一个中间状态,就像过河,要么就过,要么就不过,不会卡在河中间。具有原子性的量,是拒绝多线程操作的,即同一时刻只能有一个线程对他操作
- 可见性:指当多个线程访问同一个变量时,某个线程修改了这个变量的值,其他线程能立刻看到这个修改。在多线程环境下,一个线程对共享变量的操作其他线程是不可见的。如果这个共享变量被Volatile修饰,那他就拥有了可见性,此时这个线程被修改后会被立即更新到主内存中,其他线程读取该变量时,会从主内存中读取。Synchronized和lock也能够保证可见性,因为线程在释放锁之前会将对变量的修改刷新到主内存中。
- 有序性:即按照代码的先后顺序执行
锁的互斥性和可见性
互斥也就是说锁一次只能给一个线程,在线程拥有锁的期间只有这个线程可以操作共享数据
可见性参考上文
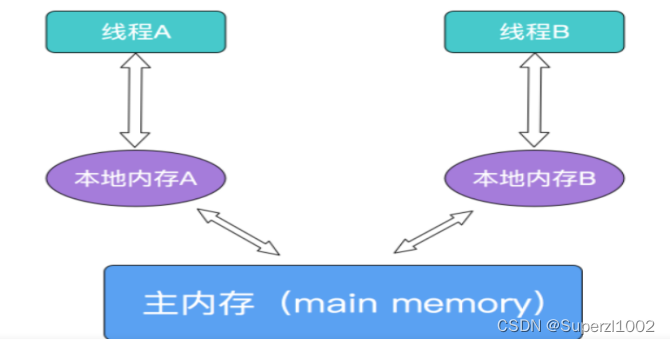
JMM(Java内存模型)
我们需要知道JMM中包含了本地内存和主内存,共享变量储存在主内存中,每个线程都拥有一个私有的本地内存,本地内存中保存了该线程需要使用到的主内存的副本拷贝,线程对变量的操作都在本地内存中进行,不能直接读写主内存的数据,这就造成一个问题,A线程操作完共享变量后没有马上同步到主内存中去,那么B线程使用的就是修改之前的值。要解决这种不可见性,可以通过加锁或者用volatile修饰共享变量。
Volatile变量的特性:
特性1:保证可见性但不能保证原子性
当一个线程对一个volatile变量进行写操作时,JMM会把该线程本地内存中的变量强制刷新到主内存中去,同时会导致其他线程中的volatile变量缓存失效(MESI协议)。所以volatile变量不适用于非原子性操作
1.1为什么不能保证原子性呢?
举个例子,i++操作。i的初始值为100,此时有两个线程A和B同时对i进行操作。A和B读到i的值到他们的寄存器中,当A操作完成,并把i=101刷新回主存中,并使B本地内存中的缓存无效,但B的寄存器的值仍然有效,此时B再进行i++操作,i=101刷新回主存,导致结果是101而不是102。所以volatile虽然可以保证将最新数据刷新到主存,但仍然不能保证原子性
下面还有一个例子

特性2:禁止指令重排,实现原理是jvm中volatile使用了内存屏障,他相当于将被volatile修饰的变量保护了起来,后面的代码不会跑到屏障前面去,前面的代码也不会跑到屏障后面去,也就是说在该变量之前的代码已经执行完成。
我们前面说到,volatile并不能解决原子性的问题,那么有方法可以解决吗?
有,Synchronized,lock和juc中的原子操作类java.util.concurrent.automic包下的类。Synchronized和lock我们知道,他们本身就具有原子性,那么原子操作类是什么原理呢。
原子操作类底层实现了CAS,要了解CAS,首先我们先了解一下乐观锁和悲观锁。
乐观锁:在并发情况下对数据进行修改时保持乐观的态度,认为在自己修改数据的过程中,其他线程不会对这个数据进行修改,所以此时不对数据加锁,但是会在最终更新数据前,判断一下这个数据有没有被修改过,若没有被修改,才会将他更新为自己修改后的值
悲观锁:在并发情况下对数据进行修改时保持悲观的态度,认为自己在修改数据的过程中其他线程也会对这个数据进行修改,所以在操作前会对数据加锁,在操作完成之后才会释放锁,在释放锁之前,其他线程无法操作该数据。
通过上面的定义我们能够知道,Synchronized就是典型的悲观锁,而CAS其实就是乐观锁的一种实现。
CAS全称Compare and swap,他包含三个数据,需要修改的数据的内存地址(记作A),被操作数据的旧值(记作B),要将他修改为的值(记作C)。
CAS操作流程如下:
1.首先记录要修改数据的地址(记作A)
2.将现在的值做记录,记作B
3.查看A地址下的值是否仍然为B,如果是,说明其他线程没有对其进行修改,那么将C替换B;如果不是,说明在上面流程中,其他线程对数据进行了修改,那么就不更新变量的值,回到步骤2重新执行,这被称为自旋
CAS的操作过程中可能会遇到ABA问题,就是在CAS进行数据比对的过程中其他线程也可能会对此数据进行修改,比如在线程A在CAS过程中线程B拿到了i = 1,把它改为i=2,又改成i=1,这样CAS判断数据未被修改过,但其实修改过,这就是ABA问题。
解决ABA问题:引入版本号,在对比时不止对比数据的值,还对比版本号。在数据每次被修改后都会有一个新的版本号。
当下次我们需要确保i++的原子性时,就可以使用automic包下的AutomicInteger类,他有一个incrementAndGet方法,同样也是让i+1,但是能够保证其原子性
总结一下volatile:他能实现可见性和有序性,但是不能保证原子性,他能够禁止cpu的指令重排
锁的优化:
一:锁升级
锁一共有四种状态:无锁,偏向锁,轻量级锁,重量级锁。锁的状态只能升级,不能降级,(偏向锁状态可以转为无锁状态)
偏向锁
在很多场景下,其实线程的竞争并不那么激烈,如果一直都是同一个线程拿到这个锁,那就没必要每次都去竞争锁,因为竞争锁要付出很大的代价,所以就引进了偏向锁。当A线程获取到锁对象时,会将该线程的threadID记录在锁对象的对象头和栈帧中,当线程A再次来获取锁时,会先对比线程的threadID和对象头中的threadID是否一致,如果一致,说明还是线程A来获取锁,那此时就不需要加锁和释放锁了;如果threadID不一致,说明是其他线程,那么此时需要查看线程A是否存活,如果没有存活,那么锁被置为无锁状态,其他线程将其设置为偏向锁;如果存活,那么查看线程A的栈帧信息,如果仍然需要持有锁对象,那么将该偏向锁升级为轻量级锁。
轻量级锁:如果此时线程之间有竞争但是竞争也并不激烈,并且线程持有锁的时间不长,此时因为线程拿不到锁而变为阻塞状态,代价有点大,因为阻塞线程需要CPU从用户态转换为内核态,如果线程刚阻塞没多久锁又被释放了,那么付出的代价得不偿失,所以这种情况下我们选择不对线程进行阻塞,而是让他在原地自旋等待锁释放。但是自旋也需要消耗cpu资源,所以自旋是有次数限制的,如果自旋次数达到限制并且此时锁还没有释放,那么此时轻量级锁就会膨胀变为重量级锁,重量级锁会把除了拥有锁的线程都阻塞,防止cpu空转
重量级锁:当线程拿到这个锁后,其他竞争的线程都进入阻塞状态,所以系统性能开销很大
二:锁消除
JIT编译器在编译时进行逃逸分析,分析锁对象是不是只会被一个线程加锁,不存在线程竞争的情况,此时就会把锁消除,减少系统性能消耗
三:锁粗化
JIT编译器在编译时发现代码中出现了频繁加锁释放锁的过程,此时会把这些锁合并为一个锁
5.什么是死锁?
当线程A持有a锁,线程B持有b锁,此时线程A需要b锁,线程B需要a锁,也就是AB两个线程互相需要对方手中的锁的情况,两个线程都会发生阻塞,这就是死锁
6.如何避免死锁?
- 尽量使用tryLock方法,设置阻塞超时时间,超时后退出防止死锁
- 尽量降低锁的粒度,不要很多功能用同一把锁
- 减小同步块的范围
7.什么是ThreadLocal?
线程变量,即threadLocal中填充的变量属于当前线程,该变量对于其他线程而言是隔离的,所以不存在多线程间共享的问题。threadLocal为变量在每个线程中都创建了一个副本,每个线程都可以访问自己的副本,并且每个线程只能访问自己的副本
8.Synchronized的底层实现原理?
Synchronized是由一对monitorenter/monitorexit指令实现的。在jdk1.6之前,锁的实现完全是依靠互斥锁,意味着需要进行用户态和内核态的切换,所以同步操作是一个非常消耗性能的重量级操作。在1.6时,对锁机制进行了优化,引进了三种不同的锁实现,也就是偏向锁,轻量级锁和重量级锁,大大优化了性能。
9.synchronized和lock有什么区别?
Synchronized可以修饰类,方法,代码块,lock只能修饰代码块;synchronized可以自动获取和释放锁,在遇到异常时会自动释放锁,不会造成死锁,lock需要手动加锁和释放,如果忘记unlock()就会造成死锁;tryLock()可以知道是否成功获取锁,synchronized不行。
















 1003
1003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











