







小说目录链接
这次要爬的网站是主站链接: com
小说目录链接: /69528/
另外注意,爬虫对小说网站的页面布局要求是定制化的,可能不同网站的布局不一样,爬虫也要做相应的调整。
小说目录网站图
如果你看的时候,这个网站还在……
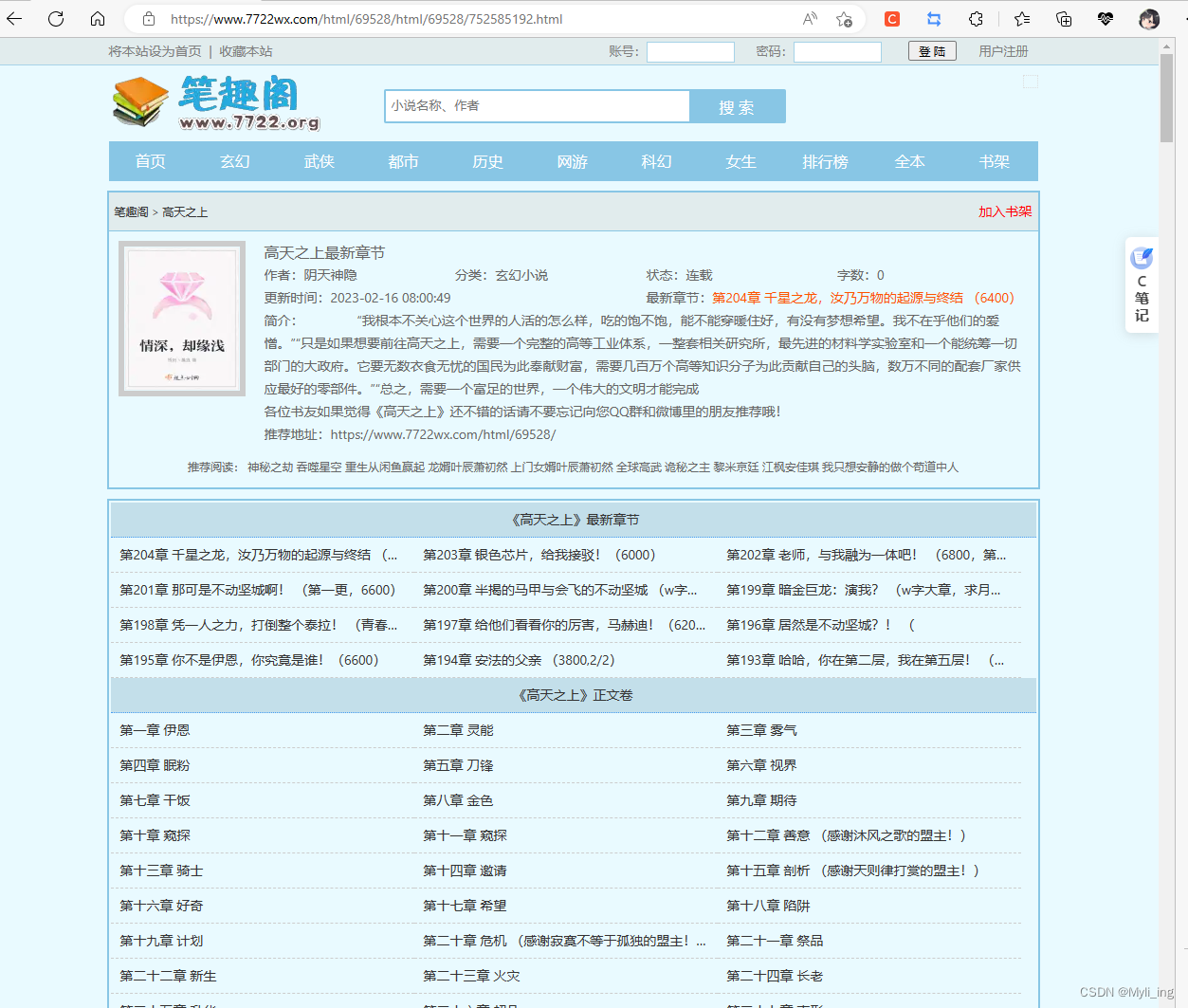
f12点开,查看列表在哪里。
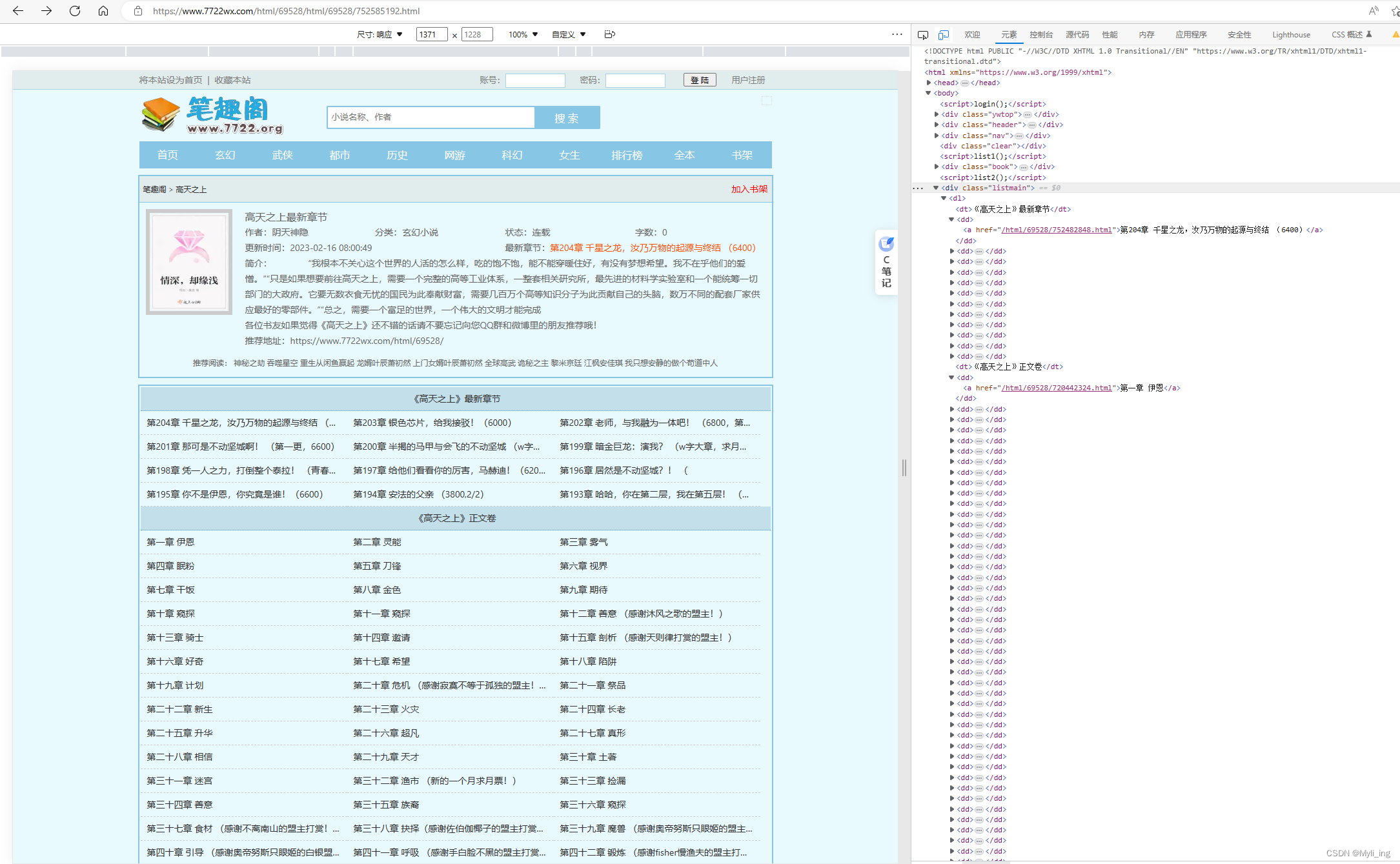
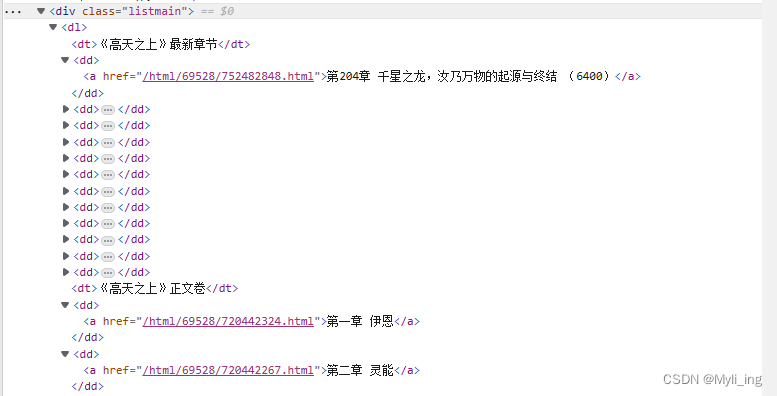
代码
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
import java.util.ArrayList;
/**
* @author Myli
* @create 2023-02-15 23:23
*/
public class te {
//规定要爬取的网页
static String url = "https://www.7722wx.com";
static String url0 = "https://www.7722wx.com/html/69528/";
public static void main(String[] args) throws IOException {
//设置下载文件存放磁盘的位置
File path = new File("C:\\Users\\Sterman\\Desktop\\高天之上");
//判断文件夹是否存在,不存在就创建
if (!path.exists()) {
path.mkdirs();
}
Connection conn = Jsoup.connect(url0);
//伪装成为浏览器,有的网站爬取数据会阻止访问,伪装成浏览器可以访问,这里我伪装成Google浏览器
Document doc = conn.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36").get();
System.out.println("开始连接网站……");
//寻找名叫panel-body的div,接着再在里面寻找叫list-group.list-charts的ul,再在里面寻找li,再在li里寻找a //"div.panel-body ul.list-group.list-charts li a"
Elements as = doc.select(".listmain").select("dd");
if (as.isEmpty()) {
System.out.println("未查到任何内容,请检查标签是否正确!");
} else {
ArrayList<Element> elements = new ArrayList<>();
for(int a=0;a<=11;a++) {
elements.add(a,as.get(0));
as.remove(0);
}
for (Element a : as) {
//对于每一个元素取出拿到href和小说名字
// String href = a.attr("href");
String href = a.getElementsByAttribute("href").attr("href");
String title = a.text().replace(" ", "");
//path:表示存放文件的位置
//href:表示要读取内容的页面
//title:表示存放文件名称
if (path.exists() || !href.isEmpty() || !title.isEmpty()) {
save(path, href, title);
} else {
System.out.println("!!!!!!!!!!!!!!");
}
}
}
}
private static void save(File path, String href, String title) {
Writer out = null;
String url2 = "";
Connection conn = null;
Document doc = null;
String content = "";
String path1="";
int n = 0;
File f=null;
//在file目录下创建每一个章命名的txt文件
path1 = path + "\\" + title + ".txt";
f = new File(path1);
try {
//构建输出流对象,因为小说的内容是字符类型的数据
if (!path.exists()) {
// 判断路径是否存在
if (!path.exists()) {
// 如果不存在则创建目录
path.mkdir();
f.createNewFile();
}
}
} catch (IOException e) {
e.printStackTrace();
}
try {
out = new FileWriter(f);
//构建读取页面的url2
url2 = url + href;
//正确的地址为https://www.7722wx.com/html/69528/752585192.html
conn = Jsoup.connect(url2);
//伪装成为浏览器
doc = conn.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36").get();
//获取小说的正文
content = doc.select("div[class=showtxt]div[id=content]").html();
//处理特殊数据
content = content.replace("请记住本书首发域名:www.7722wx.com。笔趣阁手机版阅读网址:m.7722wx.com", "");
content = content.replace("正在手打中,请稍等片刻,内容更新后,请重新刷新页面,即可获取最新更新", "");
content = content.replace("<script>app2();</script>", "");
content = content.replace("<script>chaptererror();</script>", "");
content = content.replace("<br>", "");
content = content.replace(" ", "");
content = content.replace(" ", "\r\n ");
out.write(title + "\r\n" + content);
out.close();
} catch (IOException e) {
e.printStackTrace();
}
if (f.exists()) {
System.out.println(title + "创建成功!");
} else {
System.out.println(title + "!!!!!!!!!");
}
//需要使用休眠,为了防止网站检测为蓄意攻击,停止我们的IP访问
n = (int) (Math.random() * 1000 + 100);
try {
Thread.sleep(n);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
不足
1.代码是晚上写的,其中使用 String href = a.getElementsByAttribute(“href”).attr(“href”);前,是使用a.attr(“href”),但这样写怎么也获取不到元素。
2.如果你详细看这个网站的排序,就会发现,他把最新章节放在的了最前面,所以我先把最新章节单独读取出来,还是因为太晚了,可以在后边再次读取一下,再使用save方法。
``


















 2155
2155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









