






Dispatcher(分布式查询分发器)是MPP数据库的核心组件,所有的查询任务都要经过其进行分发,起着沟通用户到协调者(Coordinator,即QD)和执行调度的关键作用。
在这次的直播中,我们为大家介绍了Dispatcher基本原理和实现机制,并结合实际用例进行了操作演示。以下内容根据直播文字整理而成。
Slice与Gang的基本概念与分类
传统MPP数据库采用无共享Shared-Nothing架构来存储数据,节点之间不共享存储和计算资源,需要使用其他节点的数据时通常利用网络重分发。

图1:Greenplum数据库查询示意图
(图片来自 Greenplum: A Hybrid Database for Transactional and Analytical Workloads,SIGMOD '21 ,序号和箭头系本文作者所加)
以Greenplum为例,如图1所示,当用户连接到Coordinator(协调者节点)进行查询操作时,会通过Dispatcher组件将查询任务分配到不同的Segment,各Segment之间通过Interconnect模块来传输数据。当各节点查询执行完成后,由QD节点对查询结果进行收集和整理,再回传给用户。
需要注意的是,在查询任务执行时,用户不会和QE产生任何的连接,所有消息都是通过QD 来中转传递,这也是MPP 数据库的重要特征。整个过程中,涉及到两个重要的概念:
Slice:为了在查询执行期间实现最大的并行度,Greenplum会将查询计划工作划分为Slices。Slice是查询计划中可以独立进行处理的部分。查询计划会为Motion生成Slice,Motion的每一侧都有一个Slice。正是由于Motion算子将查询计划分割为一个个Slice,上一层Slice对应的进程会读取下一层各个Slice进程广播或重分布操作生成的数据,然后进行计算。
Gang:属于同一个Slice但是运行在不同的Segment上的进程,称之为Gang。在Greenplum中,共有Unallocated、Reader Gang、Writer Gang、Entry Reader、Singleton Reader五种类型的Gang。其中:
Unallocated运行在QD,一般只在Gather Motion将各个QE回传的结果收取并集时才会用到。
Reader Gang和 Writer Gang会经常用到,而且相关的查询计划会很复杂。
● 只读的查询仅包含 Reader Gang,包含写操作的查询才会使用Writer Gang。
● 一些既读又写的查询(例如 Create table as、Update Returning等)可能同时包含这两类 Gang。
● 这两类 Gang 都只有 1-Gang 和 N-Gang 的情况(其中N为Segment数量),优化器不会进一步划分出更细致的构造。
Entry Reader和Singleton Reader不太常见,通常在处理子查询或者其它需要保证系统中只有一份值的情形下出现。
MPP数据库分布式的特点,使其存储容量和计算能力突破了单机的上限,而成为多个Segment的总和。MPP 数据库的存储和计算紧耦合,对某一部分数据的计算应尽量在这一部分数据的存储节点上直接完成,这也使得所有表在创建时都有指定的分布模式,对该表的存储和计算都应按照该模式在集群的参与者节点上分布开来,从而形成“分布式”。
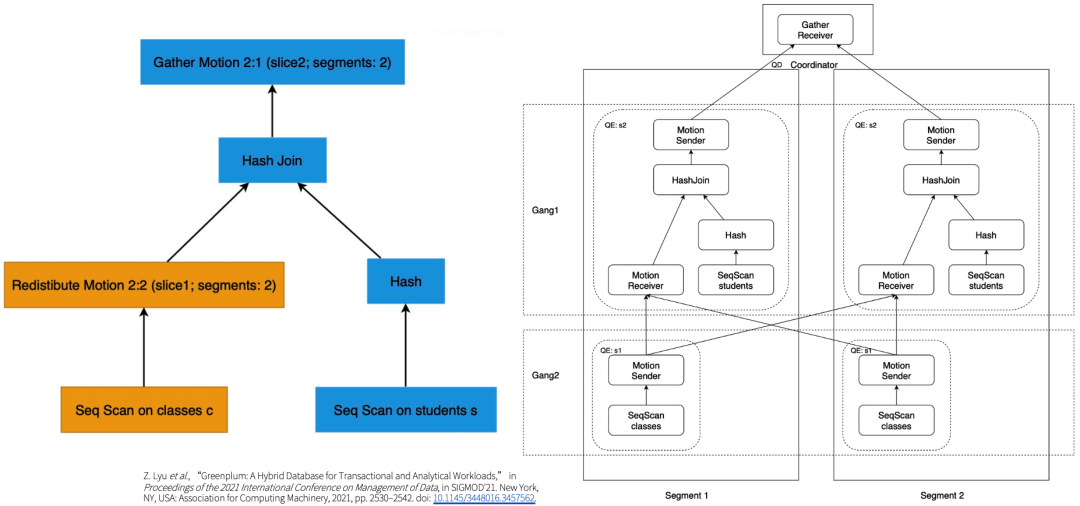
图2:Greenplum查询执行调度示意图
(来源同图1)
许多MPP数据库的初学者,经常会遇到一个问题,Slice和Gang是什么关系?
从二者的作用来看,Slice是对Plan的自然切割,Gang是对Slice的自然实现,两者之间是相互对应的。事实上,在内核代码中两者经常会交替使用。如果是优化器,会更多使用Slice;而在执行器、Dispatcher部分的代码就更多使用Gang。我们可以认为,Slice和Gang是完全对应的,前者侧重规划,后者侧重执行。
需要特别强调的是,Writer Gang ≠ Writer QE。事实上,QE并不关心自己是不是Writer Gang,它的行为只与QD连接时下发的 isWriter 参数相关,这个参数通过libpq协议握手时 Startup 消息中的 gpqeid 参数下发到QE上,QE会据此设置Gp_is_writer 全局变量,从而控制QE的行为。
在Greenplum中,任何查询都只有一个Writer QE,而只有写查询才会有Writer Gang。因此,我们时常听到的“任何查询都有一个 Writer Gang”的论断是不严谨的。
查询分发
查询分发通常分为以下四个阶段:
1.创建Gang并初始化链接;
2.分发查询计划并执行;
3.回收Gang;
4.会话断开时,关闭链接并销毁Gang。
在所有查询中,Plan类查询最为复杂,它涵盖了其余三类查询的共用方法。接下来,我们以Plan类查询为例,展开介绍查询分发的实现流程。
💡Plan是指Select、Insert 这种可由 explain 指令查看执行计划的查询。这里有一个特例,CTAS(create table as)不属于 Plan,而是属于Utility 类别。
Plan类查询分发的入口点是cdbdisp_dispatchX函数,它会调用 AssignGangs 方法,通过两次先序遍历查询计划树,创建所有的Writer Gang,然后再创建其余Gang:
bool AssignWriterGangFirst(ExecSlice *slice, ...) [if (slice->gangType == GANGTYPE_PRIMARY _WRITER) {slice->primaryGang = AllocateGang(...);return true;} else {ListCell *cell;foreach(cell, slice-›children) {if (AssignWriterGangFirst(cell->element, ...))return true;}}return false;}
AssignGangs 第一次遍历代码示例
bool InventorySliceTree(ExecSlice *slice, ...) {if (slice->gangType == GANGTYPE_UNALLOCATED) {slice->primaryGang = NULL;} else if (!slice->primaryGang) {slice->primaryGang = AllocateGang(...);}ListCell *cell;foreach(cell, slice->children) {InventorySliceTree(cell->element, ...);}}
AssignGangs 第二次遍历代码示例
注意: AssignWriterGangFirst有一个“提前终止”的特性,表明查询计划只能有一个Writer Gang。
我们看到这两段代码都是调用 AllocateGang 函数完成具体一个Gang的初始化,上方的代码只能调用一次,下方的代码可以调用多次。
创建并初始化Gang
这里引入了另一个概念:Segment Type, 因为AllocateGang函数并不直接基于Gang Type去工作,需要将 Gang Type 转化为 Segment Type。二者之间对应关系如下:

● Writer Gang一定要求一个Writer QE,即一个 isWriter 为 true 的Gang;
● extended query(libpq 规定的扩展查询协议,即游标 CURSOR)一定要求一个Reader QE,即isWriter 为false 的 Gang;
● 其他情况(包括 Reader Gang 在内),适用任何节点。
通过以上的对应关系能够提供更好的兼容性,并进一步提高Gang进程的复用率。
下一步会调用:
cdbgang_createGang_async
cdbcomponent_allocateIdleQE
这两个函数。从名字可以看出, Gang的创建是一个异步的过程,会一次创建一个Gang中的所有链接,然后通过轮询等待创建完成。在创建过程中,首先判断 freelist 中回收上来的QE的相容性,如果相容则直接使用;否则异步分配新的Gang。
异步的过程如下所示:
// cdbgang_createGang_asyncint size = list_length(segments);for (i = 0; i < size; i++) {segdbDesc = newGangDefinition->db_descriptors[i];cdbconn_doConnectStart(segdbDesc, ...); // -> PQconnectStartParams -> PQconnectPollconnStatusDone[i] = false;pollingStatus[i] = PGRES_POLLING_WRITING;}for (;;) {for (i = 0; i < size; i++) {segdbDesc = newGangDefinition->db_descriptors[i];if (connStatusDone[i]) continue;switch (pollingStatus[i]) {case PGRES_POLLING_OK:... // -> cdbconn_doConnectCompleteconnStatusDone[i] = true;continue;case PGRES_POLLING_READING:... // set poll to wait till ready to readbreak;case PGRES_POLLING_WRITING:... // set poll to wait till write won't get blockedbreak;case PGRES_POLLING_FAILED: ... // throw exception}}nready = poll(fds, nfds, poll_timeout);if (nready > 0) {for (i = 0; i < size; i++)segdbDesc = newGangDefinition->db_descriptors[i];pollingStatus[i] = PQconnectPoll(segdbDesc->conn);}}
分发查询计划并执行
在这一阶段,以Gang 为单位异步分发M类型消息(QD到QE的消息为M类型消息,调用 exec_mpp_query 入口方法,而用户收到QD的消息则为 Q 类型消息,调用 exec_simple_query 入口方法)到所有Gang,并再次通过轮询等待分发完成。
回收Gang
回收Gang时,对每个Gang中的所有QE调用 cdbcomponent_recycleIdleQE 方法,将回收的QE放到freelist中。在下次分配时,会尽量使用已经创建好的链接。这种方法保证了Writer QE永远在freelist的前部,同时因为Writer QE具有良好的相容性,就使得freelist具备“有序”的性质,在分配 Gang(allocateIdleQE)时就无需遍历整个freelist ,提升了Gang的分配效率。
销毁Gang
销毁Gang时,通过libpq对每个idle QE进行终止握手,并释放状态。
其它类型查询
● Plan:到所有QE;parsed statement
● Command:到Writer QE;raw SQL
● Utility Statement:到Writer QE;parsed statement
● Set Command:到所有QE;raw SQL
掌握了Plan类型查询分发机制之后,就能更好地理解其余的三类查询,它们是 {到所有 QE,到Writer QE} 和对 {parsed statement, raw SQL} 两两组合形成的四种结果。这里的parsed statement指经过查询解析和规划后的PlannedStmt。
SharedSnapshot
Postgres有本地快照机制,保证本地进程的一致性,而Greenplum作为一个分布式系统,必须通过分布式快照,来确保跨Segment的全局一致性。
本地快照保证进程本地一致性,分布式快照保证跨Segment一致性,但在MPP数据库中,一个Segment可能有多个进程,这就需要一个新的机制来保证跨进程的Segment本地一致性。
SharedSnapshot作为基于共享内存的快照同步,成为沟通本地快照和分布式快照的一个桥梁。Postgres中的 SnapshotData自带了进程本地一致性,在这基础之上通过SharedSnapshot实现跨进程的Segment本地一致性,最终通过分布式快照DistributedSnapshot ,实现跨Segment的系统全局一致性,从而向用户提供全局一致的视图。















 2394
2394











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









