







 文章详细介绍了R语言中自编函数的创建与应用,包括计算BMI、描述性统计分析、卡方检验以及相关性分析等。同时,讲解了apply函数族和aggregate函数在数据处理和分类汇总中的使用,强调了函数的灵活性和统计分析的重要性。
文章详细介绍了R语言中自编函数的创建与应用,包括计算BMI、描述性统计分析、卡方检验以及相关性分析等。同时,讲解了apply函数族和aggregate函数在数据处理和分类汇总中的使用,强调了函数的灵活性和统计分析的重要性。
目录
十一:R语言自编函数function
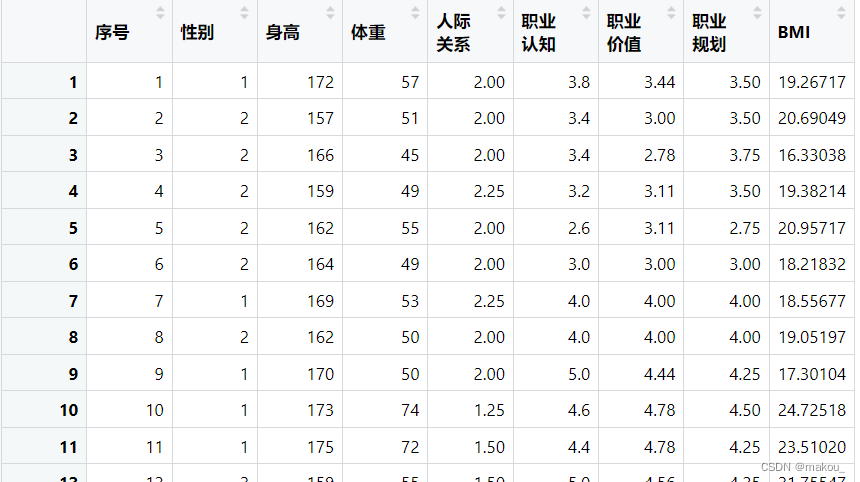
#1.针对单个向量编写函数
mean(a)#均值
var(a)#标准差
#2.针对多个向量编写函数
#以计算BMI为例,BMI=体重(公斤)/(身高_米*身高_米)
#自定义函数的目的是为了保存一种计算规则
BMIfunction <- function(x,y){
x/((y/100)^2)
#x表示体重,以公斤为单位,y表示身高,以厘米为单位
}
getwd()
mydata$BMI <- BMIfunction(mydata$体重,mydata$身高)h <- c(175,168,175,185,165,167,172,178,186,178)
w <- c(85,75,68,95,75,64,75,62,69,85)
BMI2 <- BMIfunction(w,h)
BMI2
#先在本地目录保存function为txt文件,然后通过source调用
source('BMIfunction2.txt')
BMI3 <- BMIfunction2(w,h)
#3.单个向量计算
均值标准差函数 <- function(x){
paste0(round(mean(x),2),'±',round(sd(x),2))
}
均值标准差函数(mydata$人际关系)
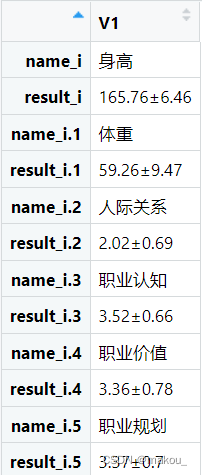
均值函数标准差(mydata$职业认知)mydata <- as.data.frame(mydata)
result <- NULL
for(i in 3:9){
name_i <- colnames(mydata)[i]
result_i <- 均值标准差函数(mydata[,i])
result <- rbind(result,name_i,result_i)
}
result
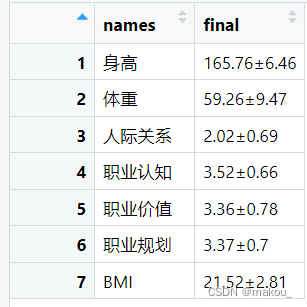
names <- colnames(mydata)[3:9]
names
seq(2,14,by=2)#提取偶数行
final <- result[seq(2,14,by=2),1]
final2 <- data.frame(names,final) #合并成数据框
write.csv(final2,'final2.csv')
十二:apply函数
#apply函数
> #对于某一些重复循环计算,既可以使用for循环,也可以使用apply函数族。
> #apply函数族包含apply、lapply、sapply、vapply、mapply等函数
>
> #apply函数的代码结构
> # apply(数据框,行/列,function)
>
> #实例演示apply函数的应用
> #由于tdl_df后期使用的时候容易报错,所以先将其转换成普通的df
>
> #求mydata2中最后四列变量的平均值
> #1、apply实现以上的需求
> apply(mydata2[,5:8], 2, mean)#1为行,2为列
人际关系 职业认知 职业价值 职业规划
2.0150 3.5240 3.3628 3.3700
>
> #2、for循环实现以上需求
> for(i in 5:8){
+ print(mean(mydata2[,i]))
+ }
[1] 2.015
[1] 3.524
[1] 3.3628
[1] 3.37
>
> apply(mydata2[,5:8], 2, sd)
人际关系 职业认知 职业价值 职业规划
0.6895910 0.6625738 0.7768357 0.6966392
> apply(mydata2[,5:8], 2, max)
人际关系 职业认知 职业价值 职业规划
4.00 5.00 4.89 4.50
> apply(mydata2[,5:8], 2, shapiro.test)
$人际关系
Shapiro-Wilk normality test
data: newX[, i]
W = 0.86919, p-value = 5.342e-05
$职业认知
Shapiro-Wilk normality test
data: newX[, i]
W = 0.97479, p-value = 0.3583
$职业价值
Shapiro-Wilk normality test
data: newX[, i]
W = 0.95311, p-value = 0.04586
$职业规划
Shapiro-Wilk normality test
data: newX[, i]
W = 0.94435, p-value = 0.0201
#apply(数据框,行/列,function)
#apply函数中的function既可以是R自带的函数,也可以是自编的函数
#无论是哪种函数,均要求这个函数必须是针对单一向量的#演示单一向量的自变量函数与apply函数的结合使用
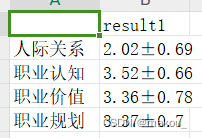
#求mydata2中最后4列变量的均值±标准差
#调用自编函数
source('均值标准差函数.txt')
result1 <- apply(mydata2[,5:8], 2, 均值标准差函数)
View(result1)res1 <- data.frame(result1)
write.csv(res1,'res1.csv')
#求mydata2中最后4列变量的均值、标准差、最大值、最小值
des <- function(x){
data.frame(min(x),max(x),mean(x),sd(x),var(x))
}res2 <- apply(mydata2[,5:8], 2, des)#list格式
#将res2从list转成def,转换的函数是do.call
res2 <- do.call(rbind,res2)#rbind为增加行转换
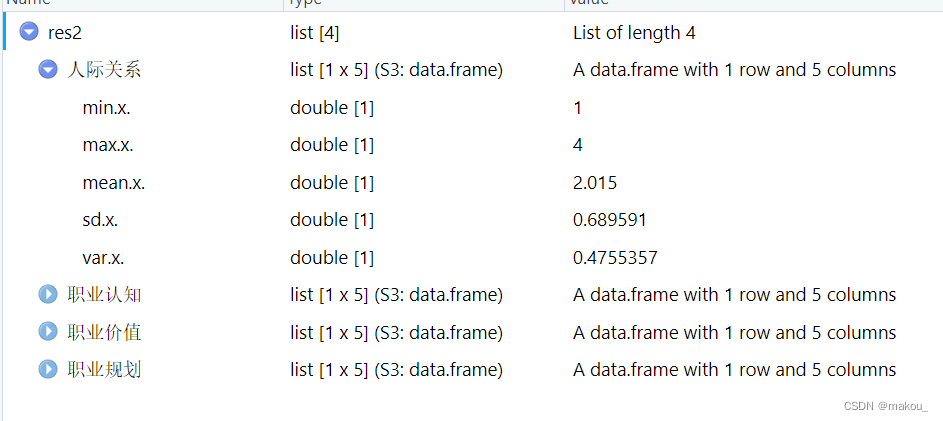
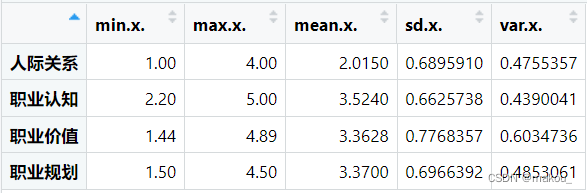
#以上均为apply函数按照列的应用案例
#以下则以apply函数按照行的案例应用
#以下案例使用的数据为量表数据
#量表数据操作的第一步一定是逆向处理
#逆向化处理也是apply函数的自编函数应用案例
#逆向化处理,本质就是变量的重新编码
#会用到car包中的recode函数
library(car)
re <- function(x){
recode(x,'1=5;2=4;3=3;4=2;5=1')
}
apply(mydata1[,c(7,9,13)],2,re)
res3 <- apply(mydata1[,c(7,9,13)],2,re)
colnames(res3) <- c('M6_n','M8_n','M12_n')
mydata1 <- data.frame(mydata1,res3)#在每行中选出M3,6,8,11,19,24计算平均值
mydata1$继续 <- (mydata1$M3+mydata1$M6_n
+mydata1$M8_n+mydata1$M11
+mydata1$M19+mydata1$M24)/6
#本质是计算每个样本的均值,所以是以行为单位
mydata1$继续承诺 <- apply(mydata1[,c(4,29:30,12,20,25)],1,mean)
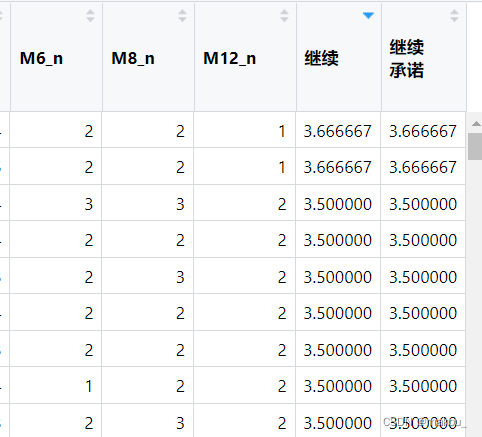
十三:分类汇总aggregate函数
###分类汇总###
#分类汇总:分组进行描述统计分析#将tbl_df转成普通的df
mydata <- data.frame(mydata)
mydata$性别 <- factor(mydata$性别, levels = c(1,2),
labels = c('男','女'))
mydata$代谢综合征 <- factor(mydata$代谢综合征, levels = c(0,1),
labels = c('无','有'))#如果不分组,针对全部的418个样本进行描述
#使用的函数是apply(数据框,行/列,函数)
apply(mydata[,c(2,4:14)],2,mean)#如果按照性别分组,分别对男性和女性都进行描述
#使用的函数是aggregate函数
#aggregare(数据框,分组(列),函数function)
#aggregare(x=list(数据框),by=list(分组(列)),Fun=自带函数function或自编函数)ss <- aggregate(x = list(mydata[,c(2,4:14)]),
by = list(mydata$性别),
FUN = mean)
#如果按照代谢综合征分组,分别对有和无都进行描述
aggregate(x = list(mydata[,c(2,4:14)]),
by = list(mydata$代谢综合征),
FUN = mean)
#多分组分类汇总
aggregate(x = list(mydata[,c(2,4:14)]),
by = list(mydata$代谢综合征,mydata$性别),
FUN = mean)
#自变函数的分类汇总
fun1 <- function(x){
paste0(round(mean(x),2),'±',round(sd(x),2))
}fun1(mydata$年龄)
res1 <- aggregate(x = list(mydata[,c(2,4:14)]),
by = list(mydata$代谢综合征,mydata$性别),
FUN = fun1)
write.csv(res1,'res1.csv')
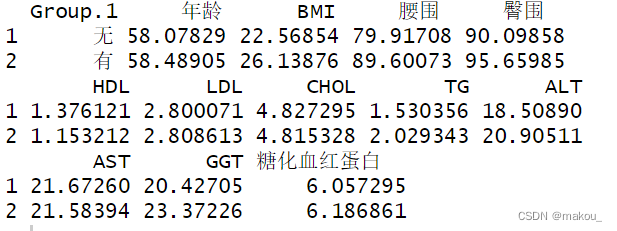
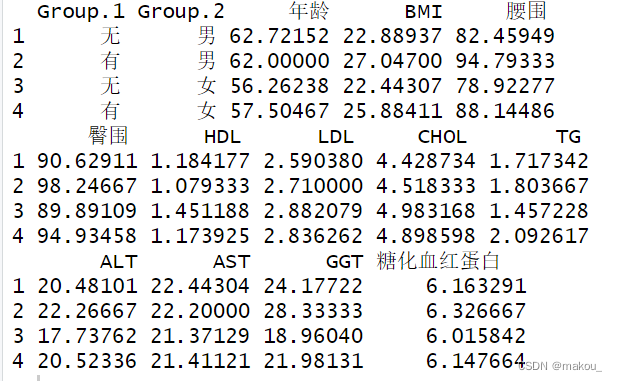
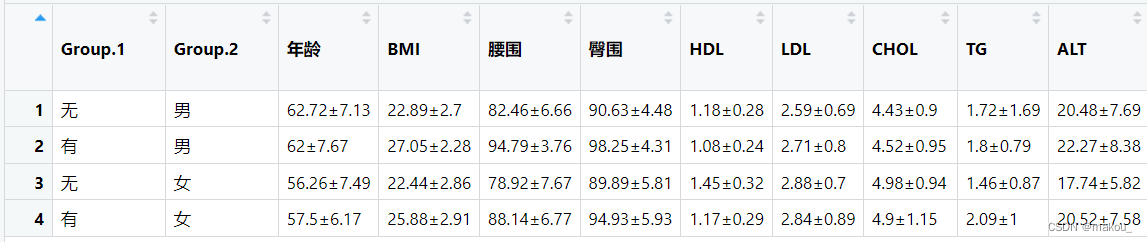
#服从正态分布的数据用均值±标准差
#非正态分布,一般用:中位数(下四分位数~上四分位数)#quantile(x,prob = 0.25)下四分位数
fun2 <- function(x){
paste0(round(median(x),2),'(',round(quantile(x,prob = 0.25),2),
'~',round(quantile(x,prob = 0.75),2),')')
}fun2(mydata$年龄)
res2 <- aggregate(x = list(mydata[,c(2,4:14)]),
by = list(mydata$代谢综合征,mydata$性别),
FUN = fun2)

十四:数据分析--描述性统计分析
连续数值型变量:
①服从正态分布:均值填补缺失值
②不服从正态分布:中位数填补缺失值
分类型变量:
①无序分类:众数填补缺失值
②有序分类:众数填补缺失值
####描述性统计分析####
#将mydata转换成普通的def
mydata <- as.data.frame(mydata)
mydata$性别 <- factor(mydata$性别, levels = c(1,2), labels = c('男','女'))
mydata$代谢综合征 <- factor(mydata$代谢综合征, levels = c(0,1), labels = c('有','无'))#对连续型变量的描述统计分析
summary(mydata[,c(2,4:14)])
res1 <- summary(mydata[,c(2,4:14)])
View(res1)
#使用summary函数进行描述统计分析的缺点:
#输出的结果制作成表格比较麻烦,会增加很多工作量
#推荐使用describe函数进行描述性统计分析
#describe函数不是R自带的函数
#describe()函数在'psych'程序包中
#1、下载安装psych程序包
#2、调用paych程序包
library(psych)
describe(mydata[,c(2,4:14)])
res2 <- describe(mydata[,c(2,4:14)])
write.csv(res2, 'res2.csv')
#增加上下四分位数的计算
describe(mydata[,c(2,4:14)],quant = c(.25,.75))
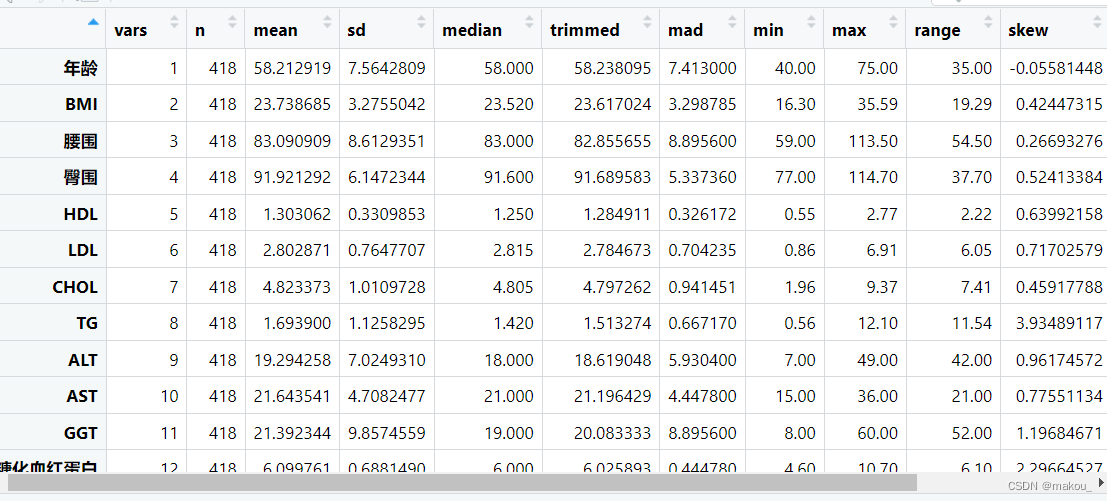

#正态性检验
#样本量<2000:shapiro.test() #P>0,05表示服从正态分布
#样本量>2000:ks.test(x,"pnorm") #P>0.05表示服从正态分布apply(mydata[,c(2,4:14)],2,shapiro.test)
#直方图的绘制
hist(mydata$年龄)
h <- c(1.1,2.2,2.2,3.3,3.2,3.6,4.3,4.6,4.5,5.8,5.6,6.7)
hist(h)#频数直方图
length(h)
fre <- c(1,2,3,3,2,1)
den <- fre/12
den
hist(h,freq = FALSE) #频率直方图,以频率为纵坐标
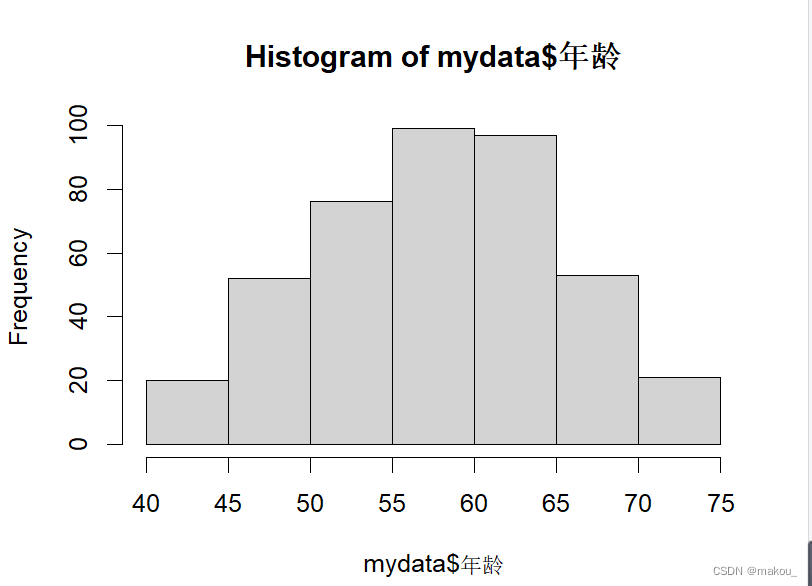
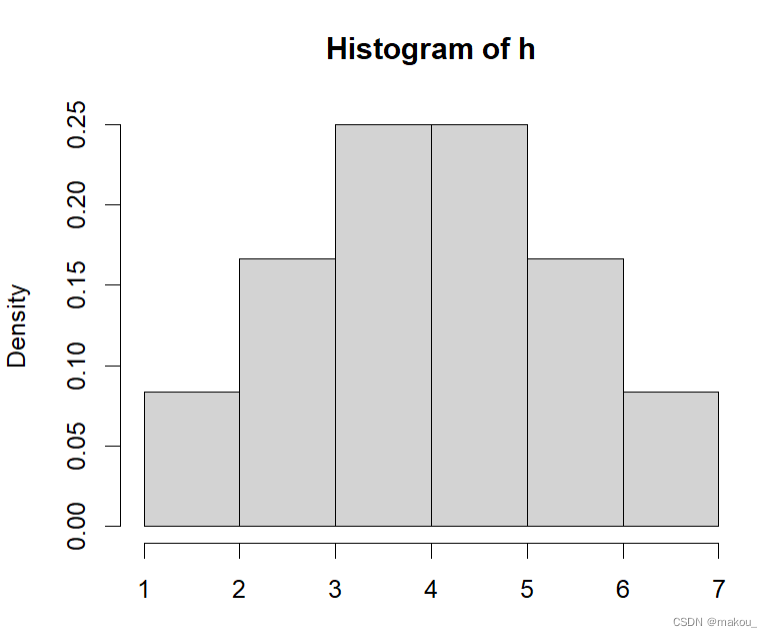
#如果我们需要在直方图中增加正态曲线,那么我们只能在频率直方图中增加正态曲线
#直方图中增加正态曲线 add = TRUE添加到直方图
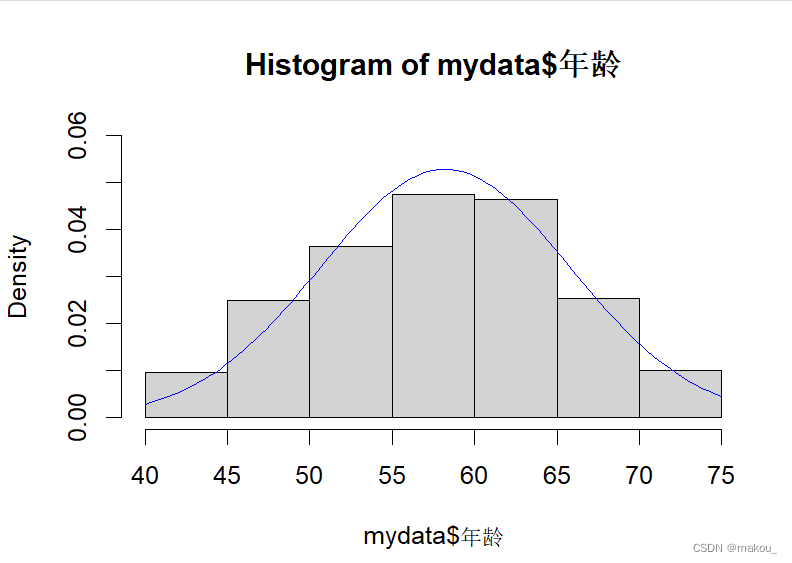
curve(dnorm(x,mean = mean(h),sd = sd(h)),add = TRUE,col = 'blue')#绘制年龄的直方图
hist(mydata$年龄,freq = FALSE,ylim = c(0,0.06))#在年龄直方图中添加正态分布曲线
curve(dnorm(x,mean = mean(mydata$年龄),sd = sd(mydata$年龄)),add = TRUE,col = 'blue')
freq = TRUE 表示纵坐标是频数-----频数直方图
freq = FALSE表示纵坐标是密度-----频率直方图
只有密度直方图才能添加正态曲线
###分类变量的描述性统计分析
table(mydata$性别)
男 女
109 309
> table(mydata$代谢综合征)
0 1
281 137
> for(i in c(3,15)){
+ print(table(mydata[,i]))
+ }
男 女
109 309
0 1
281 137
十五:卡方检验

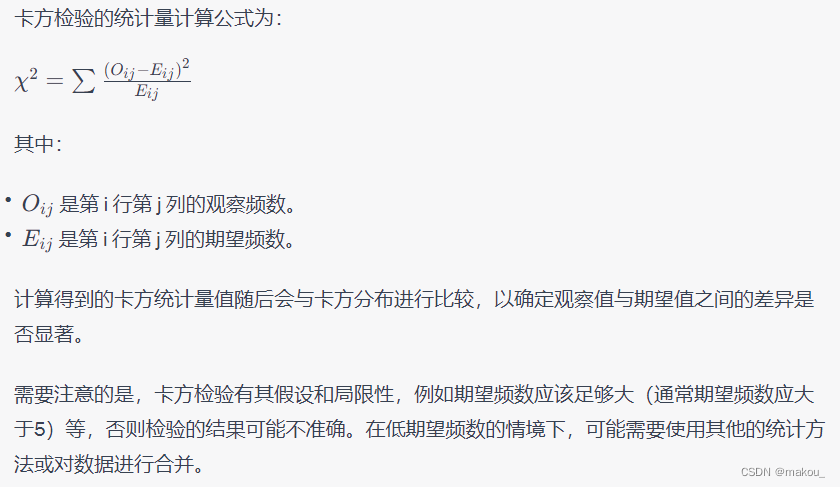
#####交叉表卡方检验##
#1、导入SPSS格式的数据
#选择Hmisc这个程序包中的spss.get函数导入数据
library(Hmisc)
mydata <- spss.get('NO.19 配套数据.sav',
use.value.labels = TRUE)
#2、交叉表卡方
#交叉表卡方检验使用的是gmodels程序包中的CrossTable函数
library(gmodels)
#性别、糖尿病史的交叉卡方
table(mydata$性别, mydata$糖尿病病史)
tab1 <- table(mydata$糖尿病病史, mydata$性别)
a1 <- CrossTable(tab1, chisq = TRUE,
expected = TRUE,
fisher = TRUE)
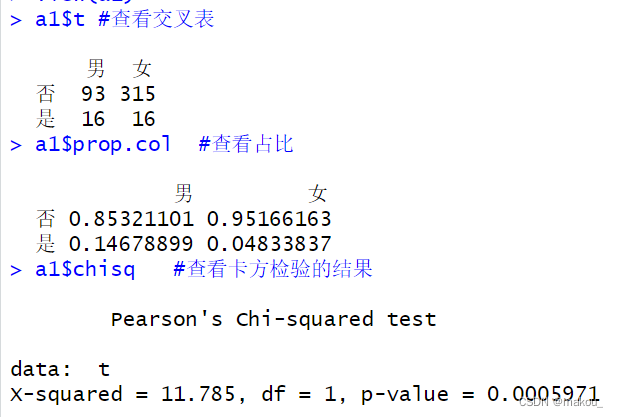
a1$t #查看交叉表
a1$prop.col #查看占比
a1$chisq #查看卡方检验的结果
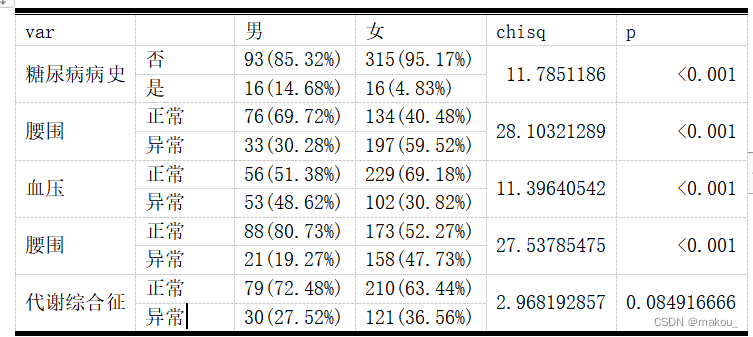
#以下代码均为标准论文表格的制作
res1 <- data.frame(matrix(paste0(a1$t, '(', round(a1$prop.col*100,2),'%)'), 2, 2))
colnames(res1) <- c('男', '女')
rownames(res1) <- c('否', '是')
res1$var <- c('糖尿病病史', 'NA')
list1 <- a1$chisq
list1 <- do.call('rbind',list1)
res1$chisq <- c(list1[1,1],'NA')
res1$p <- c(list1[3,1],'NA')
#性别、腰围的交叉表卡方
table(mydata$腰围,mydata$性别)
tab2 <- table(mydata$腰围,mydata$性别)
a2 <- CrossTable(tab2, chisq = TRUE,
expected = TRUE,
fisher = TRUE)
res2 <- data.frame(matrix(paste0(a2$t, '(', round(a2$prop.col*100,2),'%)'), 2, 2))
colnames(res2) <- c('男', '女')
rownames(res2) <- c('正常', '异常')
res2$var <- c('腰围', 'NA')
list2 <- a2$chisq
list2 <- do.call('rbind',list2)
res2$chisq <- c(list2[1,1],'NA')
res2$p <- c(list2[3,1],'NA')
#性别、血压的交叉表卡方
table(mydata$血压, mydata$性别)
tab3 <- table(mydata$血压, mydata$性别)
a3 <- CrossTable(tab3, chisq = TRUE,
expected = TRUE,
fisher = TRUE)
res3 <- data.frame(matrix(paste0(a3$t, '(', round(a3$prop.col*100,2),'%)'), 2, 2))
colnames(res3) <- c('男', '女')
rownames(res3) <- c('正常', '异常')
res3$var <- c('血压', 'NA')
list3 <- a3$chisq
list3 <- do.call('rbind',list3)
res3$chisq <- c(list3[1,1],'NA')
res3$p <- c(list3[3,1],'NA')#性别、HDL的交叉表卡方
table(mydata$HDL,mydata$性别)
tab4 <- table(mydata$HDL,mydata$性别)
a4 <- CrossTable(tab4, chisq = TRUE,
expected = TRUE,
fisher = TRUE)
res4 <- data.frame(matrix(paste0(a4$t, '(', round(a4$prop.col*100,2),'%)'), 2, 2))
colnames(res4) <- c('男', '女')
rownames(res4) <- c('正常', '异常')
res4$var <- c('腰围', 'NA')
list4 <- a4$chisq
list4 <- do.call('rbind',list4)
res4$chisq <- c(list4[1,1],'NA')
res4$p <- c(list4[3,1],'NA')#性别、代谢综合征的交叉表卡方
table(mydata$代谢综合征, mydata$性别)
tab5 <- table(mydata$代谢综合征, mydata$性别)
a5 <- CrossTable(tab5, chisq = TRUE,
expected = TRUE,
fisher = TRUE)
res5 <- data.frame(matrix(paste0(a5$t, '(', round(a5$prop.col*100,2),'%)'), 2, 2))
colnames(res5) <- c('男', '女')
rownames(res5) <- c('正常', '异常')
res5$var <- c('代谢综合征', 'NA')
list5 <- a5$chisq
list5 <- do.call('rbind',list5)
res5$chisq <- c(list5[1,1],'NA')
res5$p <- c(list5[3,1],'NA')#合并所有结果
final <-rbind(res1, res2,res3,res4,res5)
write.csv(final, 'final2.csv')
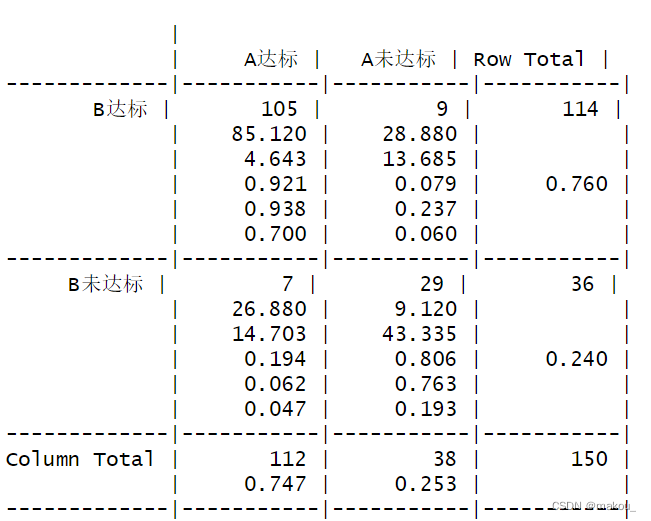
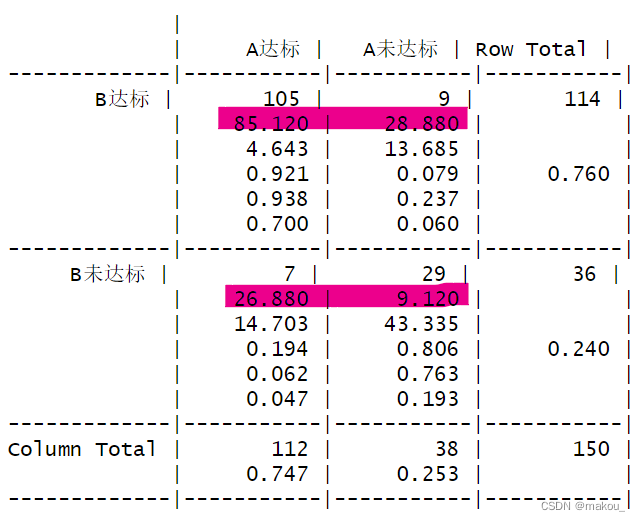
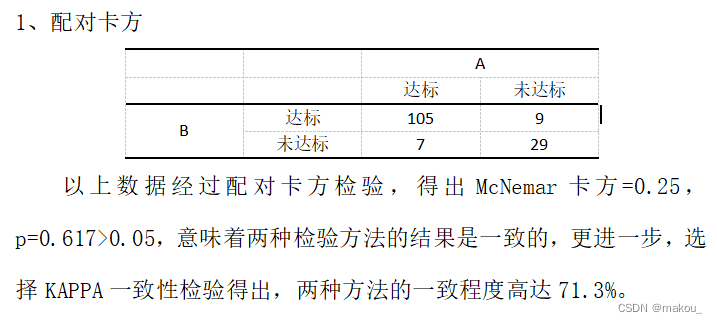
十六:配对、趋势卡方

#1、配对卡方
#对于频数表的数据,应该选择matrix的形式录进R
a <- c(105,7,9,29)
a <- matrix(a,2,2)
colnames(a) <- c('A达标','A未达标')
rownames(a) <- c('B达标','B未达标')
#配对卡方检验的函数是CrossTable
library(gmodels)
CrossTable(a,mcnemar = TRUE,expected = TRUE)#理论频数#理论频数有没有小于5,大于5用McNemar's Chi-squared test
#配对卡方 P>=0.05意味着两种方法的结果一致,不存在显著差异
#得出了A和B检验结果一致的结论后,还需要的继续进行KAPPA一致性检验,考察A和B一致程度
#KAPPA一致性检验需要用到fmsb程序包中的Kappa.test函数
library(fmsb)
Kappa.test(a)#一致程度71.3%
配对卡方:
用哪一个:看理论频数
Kappa检验:



#2、趋势卡方:分组变量是有序分类变量
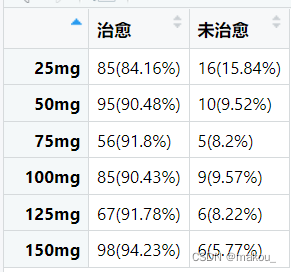
#那么探寻发生率是否随着分组的变化而存在趋势,则需要选择趋势卡方检验b <- c(85,95,56,85,67,98,16,10,5,9,6,6)
b <- matrix(b,6,2)
colnames(b) <- c('治愈','未治愈')
rownames(b) <- c('25mg','50mg','75mg','100mg','125mg','150mg')
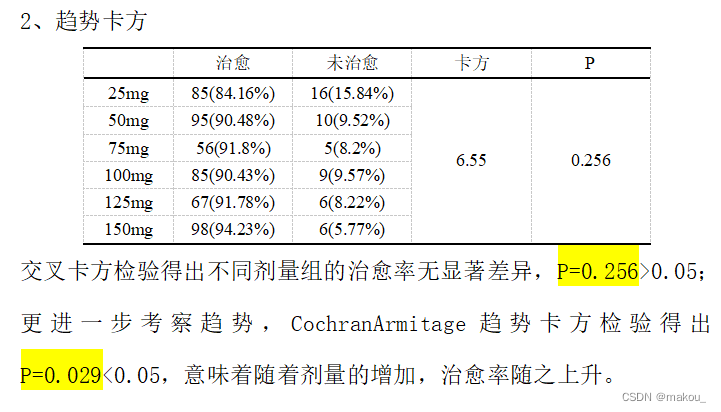
CrossTable(b,chisq = TRUE,expected = TRUE)
#以上交叉表卡方检验结果得出p=0.256>0.05,意味着不同剂量组之间的治愈率无显著差异
#组间率没有显著差异并不意味着不会随着组存在显著趋势
#接下,选择趋势卡方检验,考察治愈率对否会随着计量的上升而上升
#趋势卡方检验需要使用DescTools程序包中的CochraneArimitageTest
library(DescTools)
CochranArmitageTest(b)
#趋势卡方检验得出p=0.029<0.05,意味着趋势显著
#即治愈率会随着剂量的变化而变化
res <- CrossTable(b,chisq = TRUE,expected = TRUE)
n <- data.frame(matrix(paste0(res$t,'(',round(res$prop.row*100,2),'%)'),6,2))
colnames(n) <- c('治愈','未治愈')
rownames(n) <- c('25mg','50mg','75mg','100mg','125mg','150mg')
write.csv(n,'n.csv')

十七:相关性分析
相关性分析是统计学中的一种方法,用于评估两个或多个变量之间的线性关系的强度和方向。换句话说,当一个变量发生变化时,另一个变量是否也会发生相应的变化,以及这种变化的方向和强度是怎样的。
最常用的相关性指标是皮尔逊积矩相关系数(Pearson product-moment correlation coefficient),通常表示为 \( r \)。其值范围在 -1 到 1 之间:
- \( r = 1 \):完全正相关
- \( r = -1 \):完全负相关
- \( r = 0 \):不相关其他常用的相关性指标还包括:
斯皮尔曼等级相关系数(Spearman rank correlation coefficient):用于评估两个顺序变量(例如评级或排名)之间的关系。
肯德尔等级相关系数(Kendall tau rank correlation coefficient):与斯皮尔曼类似,但是计算方法略有不同,常用于小样本数据。相关性分析的注意事项:
1. 相关不意味着因果:即使两个变量之间存在很强的相关性,也不能直接推断其中一个变量是另一个变量的原因。
2. 潜在的混淆变量:可能存在第三个未观察到的变量,影响了正在研究的两个变量,导致它们之间产生相关性。
3. 线性关系:皮尔逊积矩相关系数主要评估的是线性关系。如果两个变量之间存在非线性关系,那么可能需要其他方法或指标来评估。
4. 异常值的影响:异常值可能会对相关性估计产生很大的影响,因此在进行相关性分析前,应该进行数据的探索性分析,以识别和处理异常值。总的来说,相关性分析是一种强大的工具,可以帮助我们了解数据中的变量如何相互关联,但使用时需要注意其局限性和潜在的误导。
######相关性分析
#学历和能力考核是等级变量
mydata$学历 <- factor(mydata$学历,levels = c(1,2,3,4),
labels = c('中专','大专','本科','硕士'),ordered = TRUE)mydata$能力考核 <- factor(mydata$能力考核,levels = c(1,2,3),
labels = c('差','中','优'),ordered = TRUE)mydata$组织领导 <- round(apply(mydata[,4:9],1,mean),2)
mydata$常规工作 <- round(apply(mydata[,10:14],1,mean),2)
mydata$病患处理 <- round(apply(mydata[,15:26],1,mean),2)
mydata$人际关系 <- round(apply(mydata[,27:30],1,mean),2)
mydata$护理认同 <- round(apply(mydata[,31:34],1,mean),2)
mydata$职业认知 <- round(apply(mydata[,35:39],1,mean),2)
mydata$职业价值 <- round(apply(mydata[,40:48],1,mean),2)
mydata$职业规划 <- round(apply(mydata[,49:52],1,mean),2)
#pearson相关,求相关系数的函数是cor()
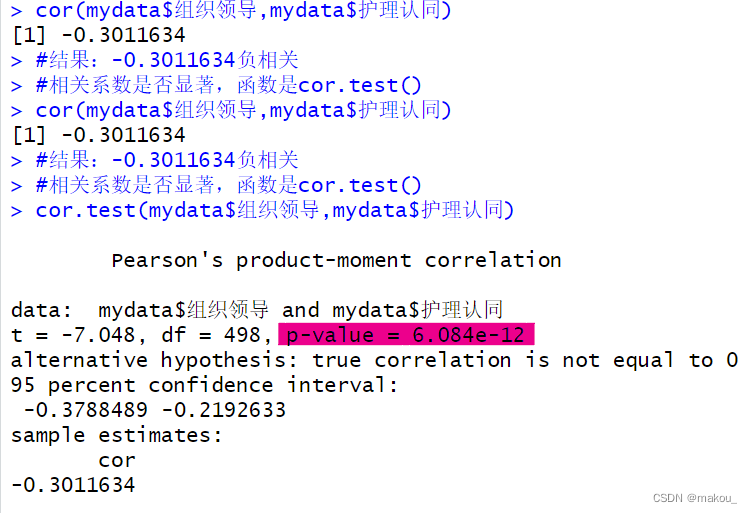
cor(mydata$组织领导,mydata$护理认同)
#结果:-0.3011634负相关
#相关系数是否显著,函数是cor.test()
cor.test(mydata$组织领导,mydata$护理认同,method = 'pearson')
##相关性分析的解析:
#1、P<0.05,意味着变量之间存在显著相关,才有资格继续分析相关系数
#如果p>0.05,意味着变量之间无显著相关,分析结束。#2、得出显著相关的结论之后,再分析相关系数
#2.1 如果相关系数>0,正相关
#2.2 如果相关系数<0,负相关#3、 得出了显著的正或者显著的负相关之后,还需考察强弱问题
#3.1 如果相关系数的绝对值<0.3,极弱相关
#3.2 如果相关系数的绝对值[0.3,0.5],弱相关
#3.3 如果相关系数的绝对值(0.5,0.7],中等相关
#3.4 如果相关系数的绝对值>0.7,强相关
res1 <- round(cor(mydata[,53:60]),2)
mydata <- data.frame(mydata)
cor.test(mydata[,53],mydata[,54])
#相关性分析结果的绘图
#相关性分分析用到的是corrgram程序包中的corrgram函数
library(corrgram)
corrgram(mydata[,53:60],upper.panel = panel.conf)#conf置信区间一正一负不相关
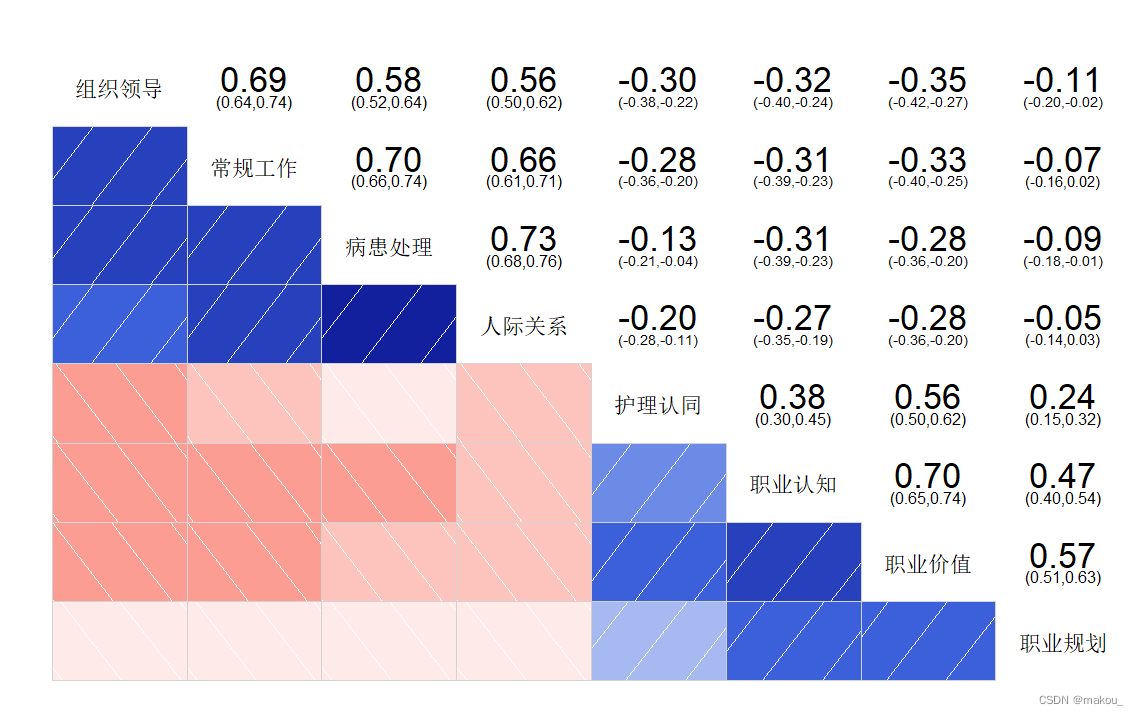
从以上的相关性分析结果清晰看到:
- 职业规划和人际关系之间不存在显著相关关系,P>0.05;
- 常规工作和组织领导之间存在着显著的相关关系,相关系数为0.69,P<0.05,意味着二者之间同升同降,即常规工作压力大也意味着组织领导压力也大。
#spearman相关
class(mydata$学历)#factor
library(do)
#把因子转成数值
mydata$学历 <- Replace(mydata$学历,from = '中专' , to = 1)
mydata$学历 <- Replace(mydata$学历,from = '大专' , to = 2)
mydata$学历 <- Replace(mydata$学历,from = '本科' , to = 3)
mydata$学历 <- Replace(mydata$学历,from = '硕士' , to = 4)class(mydata$学历)#"character"
mydata$学历 <- as.numeric(mydata$学历)
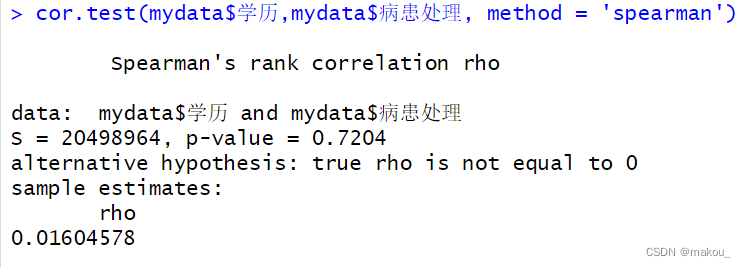
class(mydata$学历)#"numeric"cor.test(mydata$学历,mydata$病患处理, method = 'spearman')
#p-value = 0.7204,p>0.05,意味着变量之间无显著相关,分析结束。
十八:独立样本T检验



mydata$胃电图 <- factor(mydata$胃电图,levels = c(0,1),labels = c('正常','异常'))
###独立样本T检验
#1、考察SPS物质是否服从正态分布
#注意:分别对每一组都进行正态性检验
table(mydata$胃电图)
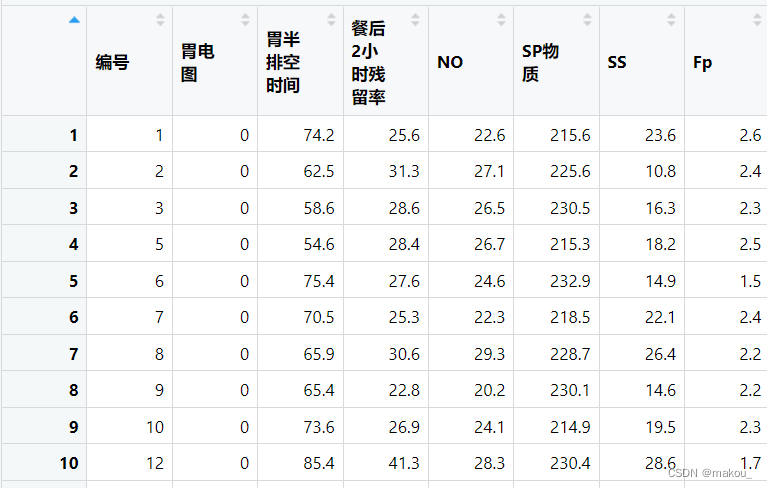
shapiro.test(mydata$SP物质)#针对全体样本
#我们需要的是针对每一组分别进行正态性检验
apply(mydata[,6],
2,
shapiro.test)#整体正态
mydata <- as.data.frame(mydata)#以下是报错代码
a <- aggregate(x = list(mydata[,6]),by = list(mydata[,2]),FUN = shapiro.test)
#aggregate中用到的函数必须是描述统计函数:mean、min、sd、max#分组进行正态性检验的函数是tapply
#tapply函数可以将运算应用到各个组中!
#tapply(向量,分组,函数)
tapply(mydata[,6], #被检验变量sp物质
mydata[,2],#分组变量
shapiro.test)#两组的p都大于0.05
#即可以使用独立样本t检验比较两组的sp物质的均值
#独立样本T检验分为两种情况:
#1、基于方差相等的独立样本T检验
#2、基于方差不相等的独立样本T检验#独立T检验的函数t.test的代码格式:
#t.test(被检验的变量~分组变量,var.equal = T/F)
#因此,在进行独立T之前,还需要考察方差齐性的问题
var.test(mydata[,6]~mydata[,2])
#F方差齐性检验的p值>0.05意味着方差齐,否则表示方差不齐
t.test(mydata[,6]~mydata[,2],var.equal = TRUE)#多个变量一起进行独立T检验
p <- NULL
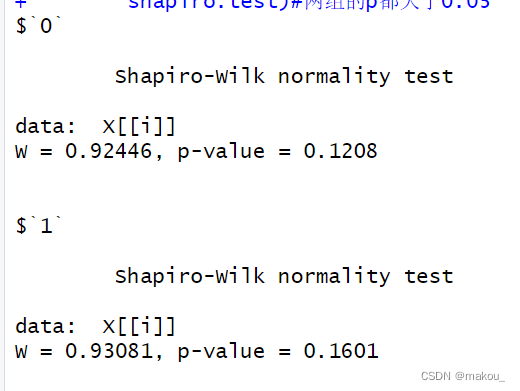
for(i in 3:8){
pi <- tapply(mydata[,i] ,
mydata[,2],
shapiro.test)
p <- rbind(p,pi)
}
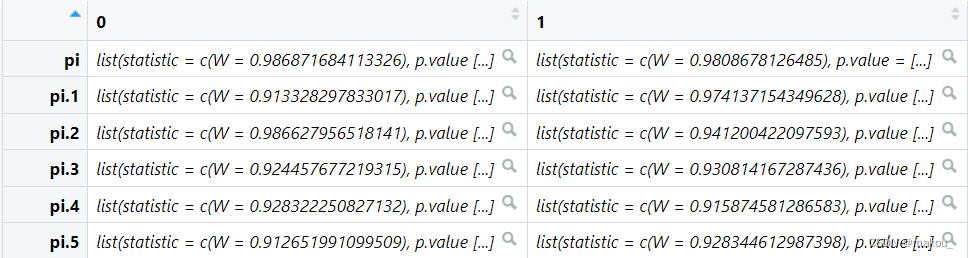
#提取正态性检验结果
p正常 <- do.call(rbind,p[,1])#转成矩阵
colnames(p正常)[2] <- 'p正态_正常'
p异常 <- do.call(rbind,p[,2])#转成矩阵
colnames(p异常)[2] <- 'p正态_异常'res_nor <- cbind(p正常[,2],p异常[,2])
res_nor <- as.data.frame(res_nor)
rownames(res_nor) <- colnames(mydata)[3:8]for(i in 1:6){
for(j in 1:2){
pp <- as.numeric(res_nor[i,j])
res_nor[i,j] <- round(pp,2)
}
}以上是SW正态性检验结果,可以清晰知道,两组在所有变量上均服从正态分布,P值全部大于0.05,意味着可以选择独立样本T检验比较组间的均值差异。

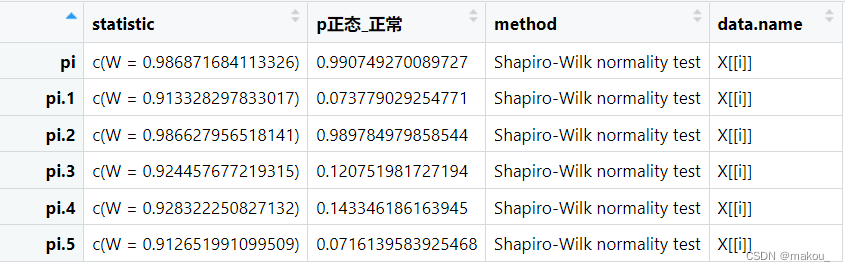
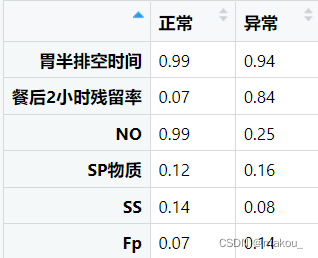
#计算均值和标准差
source('均值标准差函数.txt')
res_mean <- aggregate(x = list(mydata[,3:8]),
by = list(mydata[,2]),
FUN = 均值标准差函数)res_mean <- t(res_mean)#横纵坐标转换
res_mean <- res_mean[-1,]#删除第一行
colnames(res_mean) <- c('正常','异常')#方差齐性
for(i in 3:8){
print(var.test(mydata[,i]~mydata[,2]))
}
#所有变量全部方差齐#进行独立T检验
t <- NULL
for(i in 3:8){
ti <- t.test(mydata[,i]~mydata[,2],var.equal = TRUE)
t <- rbind(t,ti)
}
t_value <- t[,1]
t_value <- do.call(rbind,t[,1])
for(i in 1:6){
print(t[i,3])
t[i,3] <- round(as.numeric(t[i,3]),3)
}
res_final <- cbind(res_mean,round(t_value,3),t[,3])
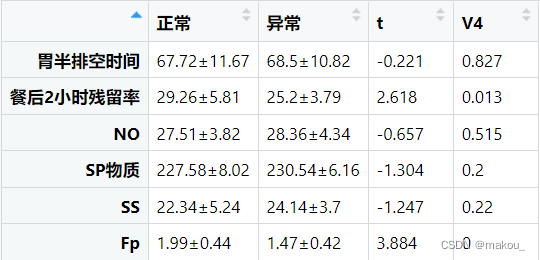
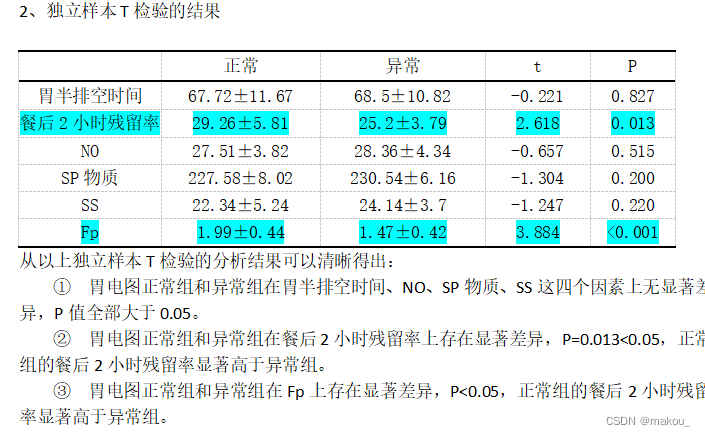

















 2284
2284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









