







文章目录
一、使用docker创建环境
参考博客在docker中构建深度学习环境
1.1 创建容器
拉取合适的cuda版本镜像创建容器,这里拉取cuda11的镜像
docker run --gpus all --name bevformer --net=host -v /home/kemove/Downloads/data:/workspace/data -it nvidia/cuda:11.1.1-cudnn8-devel-ubuntu20.04 bash
1.2 在容器中安装常用的包
# 获取最新软件包
apt-get update
# 安装vim
apt-get install vim
# 安装ping命令
apt-get install iputils-ping
# 安装wget
apt-get install wget
# 安装ps
apt-get install procps
# 安装git
apt-get install git
一条命令安装
apt-get update &&
apt-get install vim iputils-ping wget procps git
1.3 安装miniconda
进入miniconda官网,选择命令行下载,获取命令行下载的指令。
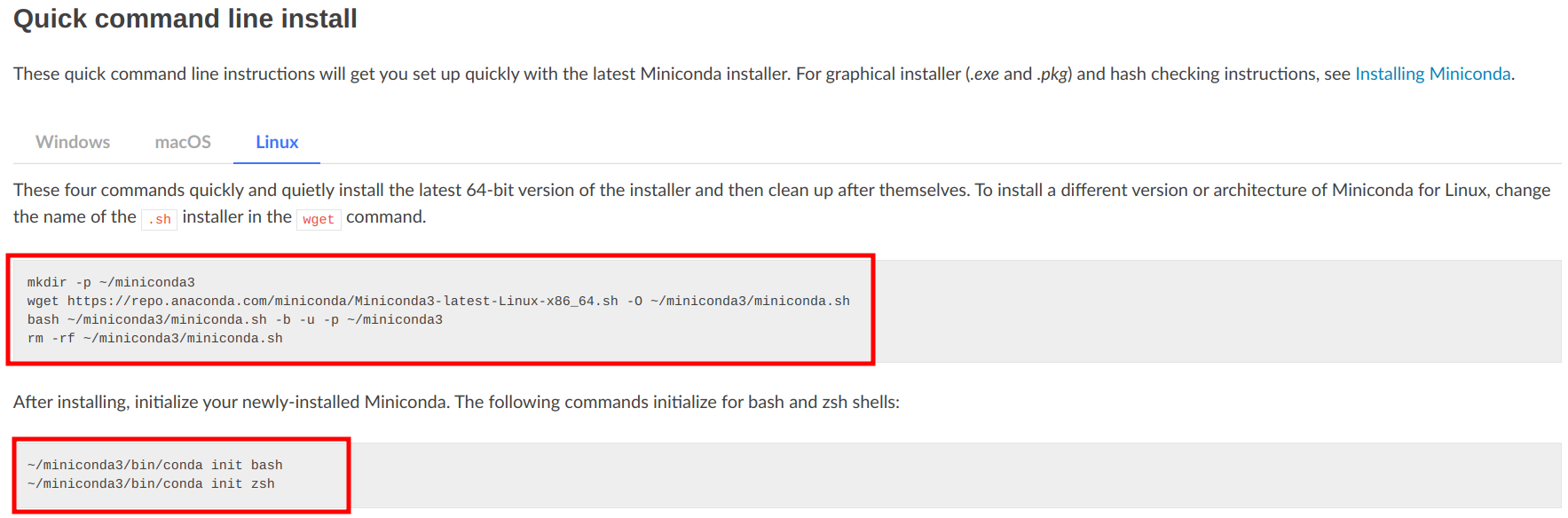
新建终端输入如下指令。
mkdir -p /home/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O /home/miniconda3/miniconda.sh
bash /home/miniconda3/miniconda.sh -b -u -p /home/miniconda3/
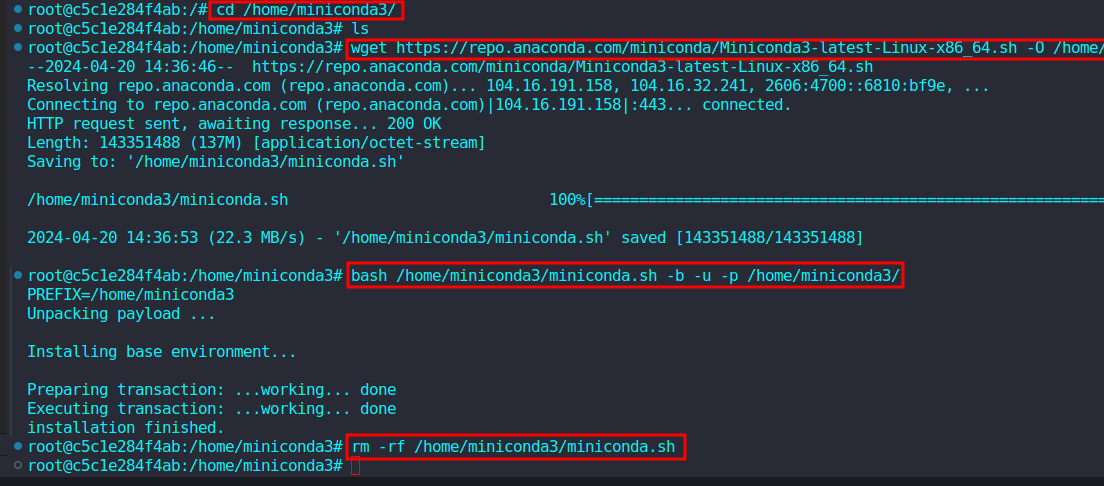
安装完成后,初始化miniconda和shell
/home/miniconda3/bin/conda init bash
/home/miniconda3/bin/conda init zsh
(可选)取消每次启动自动激活miniconda的基础环境base
conda config --set auto_activate_base false
1.4 安装Pytorch
a. 创建虚拟环境并激活,这里选择Python3.8,大于等于Python3.8均可。
conda create -n open-mmlab python=3.8 -y
conda activate open-mmlab
b. 根据官网指导安装PyTorch和torchvision
pip install torch==1.9.1+cu111 torchvision==0.10.1+cu111 torchaudio==0.9.1 -f https://download.pytorch.org/whl/torch_stable.html
# Recommended torch>=1.9
二、环境配置
2.1 下载源码
git clone https://github.com/fundamentalvision/BEVFormer.git /workspace/bevformer
在coda环境中安装gcc>=5(可选)
conda install -c omgarcia gcc-6 # gcc-6.2
2.2 安装mmcv-full
pip install mmcv-full==1.4.0
# pip install mmcv-full==1.4.0 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.9.0/index.html
2.3 安装mmdet和mmseg
pip install mmdet==2.14.0
pip install mmsegmentation==0.14.1
这里重新安装一下opencv
Install opencv-python-headless instead of opencv-python. Server (headless) environments do not have GUI packages installed which is why you are seeing the error. opencv-python depends on Qt which in turn depends on X11 related libraries.
pip uninstall opencv-python
pip install opencv-python-headless
Other alternative is to run sudo apt-get install -y libgl1-mesa-dev which will provide the missing libGL.so.1 if you want to use opencv-python. The libgl1-mesa-dev package might be named differently depending on your GNU/Linux distribution.
总结:在docker中没有GUI页面,所以使用opencv会报错,因此需要安装opencv-python-headless,或者安装缺少的libgl1
2.4 从源码安装mmdet3d
git clone https://github.com/open-mmlab/mmdetection3d.git
cd mmdetection3d
git checkout v0.17.1 # Other versions may not be compatible.
python setup.py install
安装完成后,报错信息如下:
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
yapf 0.40.2 requires importlib-metadata>=6.6.0, but you have importlib-metadata 4.2.0 which is incompatible.

解决方案:
pip install yapf==0.33.0
对于这种版本依赖产生的问题,比如说一个包需要另一个包的版本大于等于多少,一般都是前者版本太新了,通过降低前者的版本来解决依赖问题。
安装完yapf之后,重新执行命令安装
pip setup.py install
使用命令查看安装的版本
pip list | grep mm
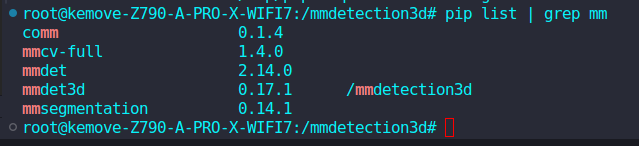
2.5 安装Detectron2和Timm
pip install einops fvcore seaborn iopath==0.1.9 timm==0.6.13 typing-extensions==4.5.0 pylint ipython==8.12 numpy==1.19.5 matplotlib==3.5.2 numba==0.48.0 pandas==1.4.4 scikit-image==0.19.3 setuptools==59.5.0
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
2.6 下载预训练模型
cd /workspace/BEVFormer
mkdir ckpts
cd ckpts
wget https://github.com/zhiqi-li/storage/releases/download/v1.0/r101_dcn_fcos3d_pretrain.pth
三、数据准备
3.1 下载数据集
nuScenes数据集可以前往官网下载,地址为https://www.nuscenes.org/nuscenes
需要注意:
- nuScenes数据集有完整版和mini版两种,完整版有400多G,各位可以按照自己的硬盘空间决定
- 使用完整版数据集训练时候,会报错误issue,下面的回答说换小一些的数据集就不会报错,尝试使用mini数据集确实不会报错,目前我还没有找到解决方案,可能需要算力更高的服务器或者更大的内存空间?因此推荐使用mini数据集测试。
除了官网下载之外,可以在百度网盘下载我整理好的数据集,完整版和mini版均有。
链接: https://pan.baidu.com/s/1as03f6dn5_5ZB7y37iBMBA 提取码: 398k
3.2 建立文件夹的软连接
ln -s /workspace/data/ /workspace/bevformer/
3.3 生成特定的标注文件
python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes --version v1.0-mini --canbus ./data
生成成功后,文件结构如下所示:
bevformer
├── projects/
├── tools/
├── configs/
├── ckpts/
│ ├── r101_dcn_fcos3d_pretrain.pth
├── data/
│ ├── can_bus/
│ ├── nuscenes/
│ │ ├── maps/
│ │ ├── samples/
│ │ ├── sweeps/
│ │ ├── v1.0-test/
| | ├── v1.0-trainval/
| | ├── nuscenes_infos_temporal_train.pkl
| | ├── nuscenes_infos_temporal_val.pkl
四、训练与测试
4.1 训练
我这里使用的单卡4090,训练bevformer_base显示显存不够,这里训练bevformer_small,需要注意的是,不管是base还是small,都需要将workers_per_gpu=4改为workers_per_gpu=0,否则会报错
./tools/dist_train.sh ./projects/configs/bevformer/bevformer_small.py 1
出现以下页面,说明模型已经愉快的开始训练啦
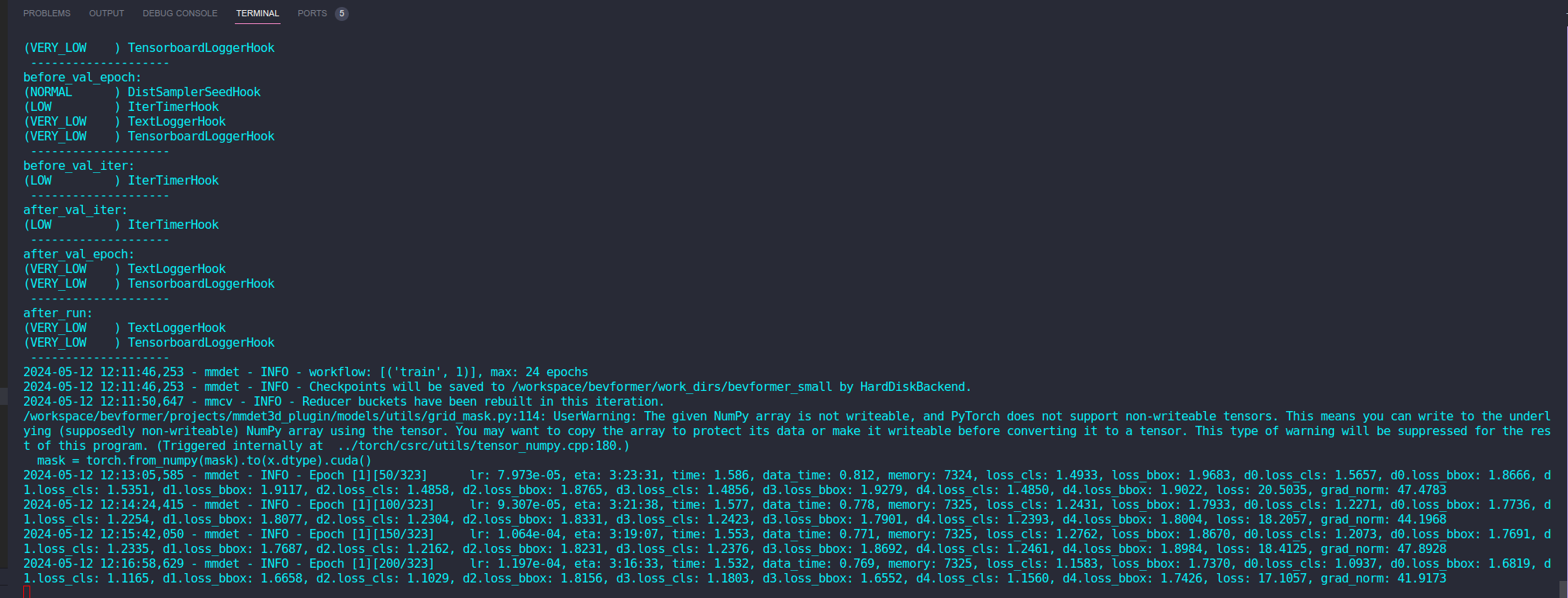
4.2 测试
./tools/dist_test.sh ./projects/configs/bevformer/bevformer_small.py ./work_dirs/bevformer_small/latest.pth 1
4.3 可视化
对4.2测试完成的结果进行可视化需要修改配置文件./tools/analsis_tools/visual.py
# 1. 引用库
# 28行
import os
# 2. 注释部分代码,不需要可视化界面,直接保存图片
# 468-469行
# if verbose:
# plt.show()
# 3. 修改main函数,472-484行
if __name__ == '__main__':
# 数据集路径,mini数据集为v1.0-mini,full数据集为v1.0-trainval
nusc = NuScenes(version='v1.0-mini', dataroot='./data/nuscenes', verbose=True)
# render_annotation('7603b030b42a4b1caa8c443ccc1a7d52')
# result_nusc.json路径
bevformer_results = mmcv.load('test/bevformer_small/Sun_May_12_23_12_20_2024/pts_bbox/results_nusc.json')
# 添加result目录
save_dir="result"
if not os.path.exists(save_dir):
os.mkdir(save_dir)
sample_token_list = list(bevformer_results['results'].keys())
for id in range(0, 10):
render_sample_data(sample_token_list[id],
pred_data=bevformer_results,out_path=os.path.join(save_dir,sample_token_list[id]))
修改完成后执行
python tools/analysis_tools/visual.py
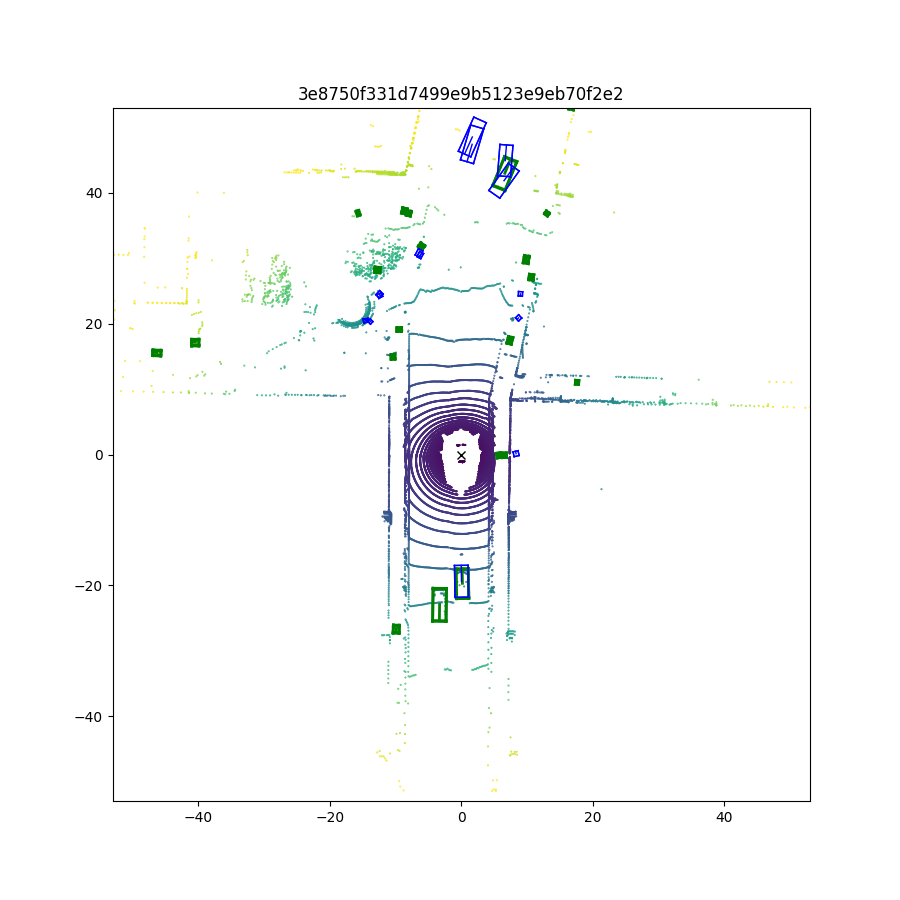
执行完成后在result文件夹下会保存可视化的结果,如图所示

打开图片可以看到可视化结果,绿色为真值标签,蓝色为预测结果

五、docker镜像
如果不想经历上述配的环境过程,我已经将配置好的docker镜像上传,拉取镜像构建容器之后,只需要配置数据集和预训练模型即可运行。
拉取镜像命令:
docker pull aitotra/bevformer:v1.0-mini
六、报错汇总
报错1 ImportError: libGL.so.1: cannot open shared object file: No such file or directory
修改:安装libsm6 libxext6 libgl1-mesa-glx
apt-get install libsm6 libxext6 libgl1-mesa-glx
报错2 ImportError: libgthread-2.0.so.0: cannot open shared object file: No such file or directory
修改:安装libglib2.0-dev
apt-get install libglib2.0-dev
报错3 ModuleNotFoundError: No module named 'tools'
修改:添加python环境变量
export PYTHONPATH="./"
报错4
from data_converter import indoor_converter as indoor
File "/home/lin/Documents/BEVFormer/tools/data_converter/indoor_converter.py", line 6, in <module>
from tools.data_converter.s3dis_data_utils import S3DISData, S3DISSegData
ModuleNotFoundError: No module named 'tools.data_converter'
修改:./tools/data_converter/indoor_converter.py的6-8行位置左右
将from tools.data_converter.s3dis_data_utils import S3DISData, S3DISSegData改成由from data_converter.s3dis_data_utils import ...
也就是tools.data_converter换成data_converter
错误5 TypeError: FormatCode() got an unexpected keyword argument 'verify'
修改:更新yapf版本为0.40.1
pip install yapf==0.40.1
错误6 显存爆炸
修改:samples_per_gpu=1, 甚至samples_per_gpu=0
或者选择训练bevformer_small
对于以下这种报错
对于没有安装的包,直接使用pip安装即可,对于前者需要后者更新版本的包,对前者降低版本处理。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











