






Apriori
说明:
- main方法中的变量data表示数据,每个数据之间使用逗号分隔,每行数据结尾使用\n表换行
- 以下两个方式都是可以的,如果不想固定数据,改为按提示从控制台录入即可
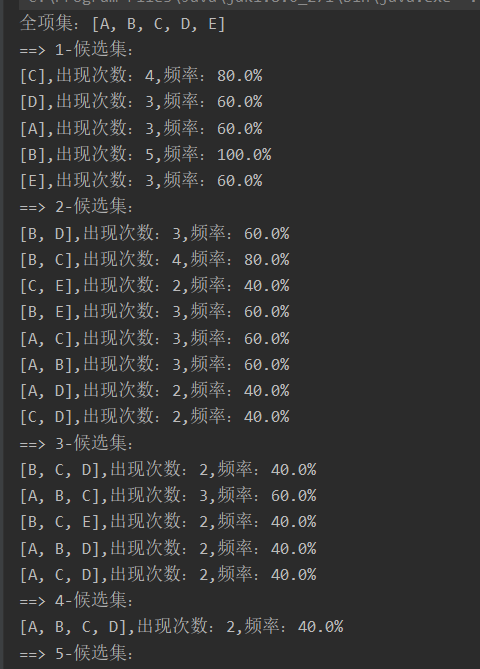
- 本例运行结果:
import java.util.*;
public class Apriori {
List<Set<String>> dataSet = new ArrayList<>();//数据集
List<String> type = new ArrayList<>();//所有的类型
public static final double LOW = 0.4; // 过滤阈值
public static void main(String[] args) {
List<String[]> list = new ArrayList<>();
/*
Scanner sc = new Scanner(System.in);
System.out.println("输入数据项个数(有多少组数据)");
int count = sc.nextInt();
sc.nextLine();
for (int i = 0; i < count; i++) {
System.out.println("输入第" + (i + 1) + "数据,以空格分割:");
String input = sc.nextLine();
input=input.trim();
list.add(input.split(" "));
}
*/
String data = "A,B,C,D\n" +
"B,C,E\n" +
"A,B,C,E\n" +
"B,D,E\n" +
"A,B,C,D\n";
String[] split = data.split("\n");
for (String s1 : split) {
list.add(s1.split(","));
}
new Apriori().build(list);
}
public void build(List<String[]> input) {
//找全项集,并将每一行的数据放入Set集合
Set<String> type = new HashSet<>();
for (String[] arr : input) {
Set<String> set = new HashSet<>();
for (String s : arr) {
set.add(s);//每一行的数据加入Set
type.add(s);
}
dataSet.add(set);
}
System.out.println("全项集:" + type);
this.type = new ArrayList<>(type);
int col = type.size();
for (int i = 1; i <= col; i++) {
System.out.println("==> " + i + "-候选集:");
// n个类型的所有搭配
List<String[]> res = getN(i);
// 每个搭配出现的次数
Map<String[], Integer> map = new HashMap<>();
for (String[] r : res) {
// 获取包含该数组中所有类型的行的数目
int count = getCount(r);
// 过滤低于阈值的
if (count * 1.0 / dataSet.size() >= LOW) {
map.put(r, count);
}
}
// 如果当前类型个数没结果,比当前个数大的自然没结果
if (map.size() == 0) {
break;
}
print(map);
}
}
private void print(Map<String[], Integer> map) {
Set<String[]> set = map.keySet();
for (String[] k : set) {
int count = map.get(k);
System.out.print(Arrays.toString(k) + ",出现次数:" + count);
System.out.println(",频率:" + count * 1.0 / dataSet.size() * 100 + "%");
}
}
// 获取个数为n个的所有搭配
private List<String[]> getN(int n) {
List<String[]> ans = new ArrayList<>();
getN(ans, 0, 0, new String[n]);
return ans;
}
// ans-结果集,index-起始索引,count-当前已经添加了多少个,arr-要添加到结果集的数据
private void getN(List<String[]> ans, int index, int count, String[] arr) {
if (count == arr.length) {
String[] clone = clone(arr);
ans.add(clone);
return;
}
// 添加元素
for (int i = index; i < type.size(); i++) {
arr[count] = type.get(i);
getN(ans, i + 1, count + 1, arr);
}
}
// 克隆数组
private String[] clone(String[] arr) {
String[] res = new String[arr.length];
System.arraycopy(arr, 0, res, 0, arr.length);
return res;
}
// 统计每一组字符串出现次数
private int getCount(String[] strs) {
int count = 0;
for (Set<String> set : dataSet) {
boolean b = true;
for (String s : strs) {
if (!set.contains(s)) {
b = false;
break;
}
}
if (b) {
count++;
}
}
return count;
}
}
FPTree算法
- 代码写的很烂
- 如果想改用自己的数据,修改main方法中s的值即可;每个数据使用逗号分开,每组数据使用分号隔开
- 输出结果树是横向打印的
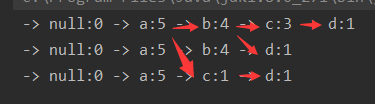
- 本例运行结果:
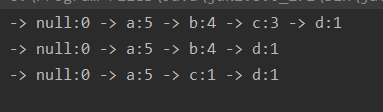
大概是这么一棵树:(看红色箭头,null是根节点,冒号前面的字母是节点名,后面的数字表示出现了几次)
import java.util.*;
public class FPTreeMain {
public static void main(String[] args) {
String s = "a,b,c,e;a,b,c,d,f;a,c,d,s;a,b,d,g;a,b,c,h;";
Data build = new FPTree().build(s);
//横向打印
printTree(build);
}
//横向打印
private static void printTree(Data build) {
List<List<Data>> tree = new ArrayList<>();
dfs(build, new LinkedList<>(), tree);
tree.forEach(line -> {
line.forEach(col -> System.out.print(" -> " + col.val + ":" + (col.right == null ? 0 : col.right.size())));
System.out.println();
});
}
//先序遍历
private static void dfs(Data data, LinkedList<Data> list, List<List<Data>> res) {
//添加当前节点
list.add(data);
//处理孩子节点
Set<Data> child = data.child;
if (child != null) {
for (Data c : child) {
dfs(c, list, res);
//遍历完
list.removeLast();
}
} else {
//添加到结果中
res.add(new ArrayList<>(list));
}
}
//纵向打印
private static List<Data> printTree(List<Data> data) {
List<Data> res = new ArrayList<>();
StringBuilder up = new StringBuilder();//该节点上方划线
StringBuilder val = new StringBuilder();//输出节点信息
StringBuilder down = new StringBuilder();//该节点下方划线
for (Data d : data) {
//输出节点信息
int count = d.right == null ? 0 : d.right.size();
val.append(d.val).append(":").append(count).append(" ");
//在该节点的上方划线
int upLength = up.length();
int valLength = val.length();
int mid = upLength + (valLength - upLength) / 2;
for (int i = upLength; i < valLength; i++) {
if (i == mid) {
up.append("|");
} else {
up.append(" ");
}
}
//是否有孩子
Set<Data> child = d.child;
StringBuilder sb = new StringBuilder();
if (child != null) {
res.addAll(child);
sb.append("|");
for (int i = 0; i < child.size() - 1; i++) {
sb.append("\\");
}
}
//在该节点的下面中间划线
int free = valLength - upLength - sb.length();//剩余空间的一半
for (int i = upLength; i < valLength; i++) {
if (i == upLength + free / 2) {
down.append(sb).append(" ");//本来下一行应该是i += sb.length(),但为了避免sb为空串,导致死循环,此处多加一个空格
i += sb.length();
} else {
down.append(" ");
}
}
}
System.out.println(up.append("\n").append(val).append("\n").append(down).toString());
return res;
}
}
class FPTree {
int filterValue = -1;
//构建FP树
public Data build(String dataSet) {
// 提供数据
List<List<Data>> data = getData(dataSet);
// 找出每个项的集合
Map<String, List<Data>> count = getCount(data);
// 获取个数大于一定值的键值对
count = filter(count);
// 剔除count中不包含的项
delete(data, count.keySet());
// 根据count对data的每一行排序
sort(data, count);
//print(data);
// 对每一行构建树
Data build = build(data);
return build;
}
//构建树,作为返回结果
Data build(List<List<Data>> data) {
Data root = new Data();
for (List<Data> row : data) {
build(row, 0, root);
}
return root;
}
//把data中的第index个加入到parent的孩子中
void build(List<Data> data, int index, Data parent) {
//结束条件
if (index >= data.size()) {
return;
}
Data getByIndex = data.get(index);
//纵向连接
Set<Data> child = parent.child;
if (child == null) {
child = new HashSet<>();
parent.child = child;
}
Data key = null;
if (child.contains(getByIndex)) {
for (Data c : child) {
if (c.equals(getByIndex)) {
key = c;
}
}
child.remove(getByIndex);
} else {
key = new Data(getByIndex.val);
}
parent.child.add(key);//父 -> 子
key.parent = parent;//子 -> 父
//横向连接
getByIndex.left = key;//右 -> 左
List<Data> right = key.right;
if (right == null) {
right = new ArrayList<>();
key.right = right;
}
right.add(getByIndex);//左 -> 右
build(data, index + 1, key);
}
// 根据count对data的每一行排序
void sort(List<List<Data>> data, Map<String, List<Data>> map) {
for (List<Data> row : data) {
row.sort((a, b) ->
map.get(b.val).size() - map.get(a.val).size());
}
}
// 剔除set中不包含的项
void delete(List<List<Data>> data, Set<String> set) {
for (List<Data> row : data) {
row.removeIf(col -> !set.contains(col.val));
}
}
// 获取个数大于一定值的键值对
Map<String, List<Data>> filter(Map<String, List<Data>> map) {
Map<String, List<Data>> res = new HashMap<>();
map.forEach((k, v) -> {
if (v.size() >= filterValue) {
res.put(k, v);
}
});
return res;
}
// String类型数据转为二维数组链表
List<List<Data>> getData(String s) {
if (!s.contains(";")) {
s = s.replaceAll("\n", ";");
}
List<List<Data>> res = new ArrayList<>();
String[] row = s.split(";");
for (String r : row) {
List<Data> rowList = new ArrayList<>();
for (String col : r.split(",")) {
rowList.add(new Data(col));
}
res.add(rowList);
}
// 设置阈值
if (filterValue == -1) {
filterValue = row.length / 2 + 1;
}
return res;
}
// 找出每个项的集合
Map<String, List<Data>> getCount(List<List<Data>> data) {
Map<String, List<Data>> map = new HashMap<>();
for (List<Data> row : data) {
for (Data col : row) {
List<Data> value = map.getOrDefault(col.val, new ArrayList<>());
value.add(col);
map.put(col.val, value);
}
}
return map;
}
}
class Data {
//父节点
Data parent;
//孩子节点
Set<Data> child;
List<Data> right;
Data left;
String val;
public Data() {
}
public Data(String val) {
this.val = val;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Data data = (Data) o;
return Objects.equals(val, data.val);
}
@Override
public int hashCode() {
return Objects.hash(val);
}
@Override
public String toString() {
StringBuffer sb = new StringBuffer("{val=").append(val)
.append(",count=").append(right == null ? 0 : right.size());
if (child != null) {
for (Data data : child) {
sb.append("; ");
sb.append(data.toString());
}
}
sb.append("}");
return sb.toString();
}
}
ID3算法
- 想改数据改s的值即可
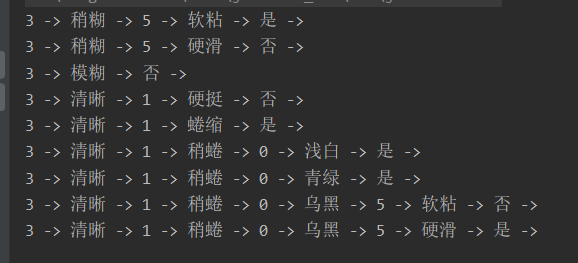
- 运行结果如图:(数字表示原数据中第几列的属性)
import java.util.*;
import java.util.stream.Collectors;
/**
* @author: liangjiayy
**/
public class ID3Main {
public static void main(String[] args) {
String s =
"青绿,蜷缩,浊响,清晰,凹陷,硬滑,是\n" +
"乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,是\n" +
"乌黑,蜷缩,浊响,清晰,凹陷,硬滑,是\n" +
"青绿,蜷缩,沉闷,清晰,凹陷,硬滑,是\n" +
"浅白,蜷缩,浊响,清晰,凹陷,硬滑,是\n" +
"青绿,稍蜷,浊响,清晰,稍凹,软粘,是\n" +
"乌黑,稍蜷,浊响,稍糊,稍凹,软粘,是\n" +
"乌黑,稍蜷,浊响,清晰,稍凹,硬滑,是\n" +
"乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑,否\n" +
"青绿,硬挺,清脆,清晰,平坦,软粘,否\n" +
"浅白,硬挺,清脆,模糊,平坦,硬滑,否\n" +
"浅白,蜷缩,浊响,模糊,平坦,软粘,否\n" +
"青绿,稍蜷,浊响,稍糊,凹陷,硬滑,否\n" +
"浅白,稍蜷,沉闷,稍糊,凹陷,硬滑,否\n" +
"乌黑,稍蜷,浊响,清晰,稍凹,软粘,否\n" +
"浅白,蜷缩,浊响,模糊,平坦,硬滑,否\n" +
"青绿,蜷缩,沉闷,稍糊,稍凹,硬滑,否";
Node build = new ID3().build(s);
print(build);
}
private static void print(Node build) {
List<List<String>> tree = new ArrayList<>();
dfs(build, new LinkedList<>(), tree);
for (List<String> line : tree) {
line.forEach(l -> {
System.out.print(l + " -> ");
});
System.out.println();
}
}
private static void dfs(Node build, LinkedList<String> linkedList, List<List<String>> tree) {
if (build == null) {
tree.add(new ArrayList<>(linkedList));
return;
}
linkedList.add(build.val);
List<Node> next = build.next;
if (next != null) {
for (Node node : next) {
dfs(node, linkedList, tree);
}
} else {
tree.add(new ArrayList<>(linkedList));
}
linkedList.removeLast();
}
}
class ID3 {
List<List<String>> data;//数据集
Map<Integer, List<String>> colValues;//每一列可能的值的集合
public Node build(String input) {
//解析数据
init(input);
//不使用的列
LinkedList<Integer> unUsedCol = new LinkedList<>();
//构建树
return buildTree(data, unUsedCol);
}
//转换数据
private void init(String input) {
//解析数据
data = getString(input);
//解析属性
colValues = getColValues(data);
}
//找到某列值是某值的所有数据进行
private Node buildTree(List<List<String>> data, LinkedList<Integer> unUsedCol, int col, String val) {
List<List<String>> collect = data.stream().filter(line -> val.equals(line.get(col))).collect(Collectors.toList());
//没有该分支,标记为最后一列最多的一种
if (collect.size() == 0) {
Map<String, Integer> map = new HashMap<>();
data.forEach(d -> {
String endStr = d.get(d.size() - 1);
Integer orDefault = map.getOrDefault(endStr, 0);
map.put(endStr, orDefault + 1);
});
//获取key,降序排列
List<String> keys = new ArrayList<>(map.keySet());
keys.sort((a, b) -> map.get(b) - map.get(a));
//返回出现多的
Node node = new Node();
node.val = keys.get(0);
return node;
}
//如果只有一种可能的结果,则直接返回
Set<String> set = new HashSet<>();
collect.forEach(c -> set.add(c.get(c.size() - 1)));
if (set.size() == 1) {
Node node = new Node();
node.val = set.toArray(new String[0])[0];
return node;
}
return buildTree(collect, unUsedCol);
}
private Node buildTree(List<List<String>> data, LinkedList<Integer> unUsedCol) {
//是否还有可用列
if (unUsedCol.size() >= getColCount() - 1) {
return null;
}
//找下一个决策属性是第几列
int nextDecisionAttrCol = findNextDecisionAttrCol(data, unUsedCol);
//不使用的列增加当前列
unUsedCol.add(nextDecisionAttrCol);
//以当前节点分类
Node res = new Node();
res.val = nextDecisionAttrCol + "";
res.isAttr = true;
List<Node> next = new ArrayList<>();
//当前列可能的属性值
List<String> values = colValues.get(nextDecisionAttrCol);
//添加属性值节点
for (String value : values) {
Node node = new Node();
node.val = value;
//当前属性值下的分类节点
// System.out.println(value);
Node build = buildTree(data, unUsedCol, nextDecisionAttrCol, value);//挑选指定列等于指定值的作为判断依据
node.next = new ArrayList<Node>() {{
add(build);
}};
next.add(node);
}
res.next = next;
//当前列在其他分支可用
unUsedCol.removeLast();
return res;
}
/**
* 找下一个决策属性是第几列
*
* @param data 数据
* @param unUsedCol 不使用的列
* @return 决策属性是第几列
*/
private int findNextDecisionAttrCol(List<List<String>> data, List<Integer> unUsedCol) {
int res = -1;
double val = 0;
//计算每一列的熵
for (int i = 0; i < getColCount() - 1; i++) {
if (!unUsedCol.contains(i)) {
double gain = getGain(data, i);
// System.out.println("gain:" + i + ":" + gain);
//如果未赋值
if (res == -1) {
res = i;
val = gain;
} else if (gain > val) {
res = i;
val = gain;
}
}
}
// System.out.println();
if (res == -1) {
throw new RuntimeException("没有可用的列");
}
return res;
}
private double getGain(List<List<String>> data, int col) {
//计算该分类属性的熵
Map<String, Integer> valueCount = getValueCount(data, getColCount() - 1);
List<Integer> list = new ArrayList<>();
valueCount.forEach((k, v) -> list.add(v));
double ent = getEnt(list);
//以第col列属性值分开,并计算熵
Map<String, Map<String, Integer>> map = new HashMap<>();
//记录col列每个属性值对应每个决策属性的个数
data.forEach(d -> {
String colStr = d.get(col);
String endStr = d.get(d.size() - 1);
Map<String, Integer> orDefault = map.getOrDefault(colStr, new HashMap<>());
orDefault.put(endStr, orDefault.get(endStr) == null ? 1 : orDefault.get(endStr) + 1);
map.put(colStr, orDefault);
});
//计算每一个属性值的信息熵,并求和
double[] sum = {0};
map.forEach((k, v) -> {
List<Integer> counts = new ArrayList<>(v.values());
//看当前属性占了多少个
int count = 0;
for (Integer c : counts) {
count += c;
}
//System.out.println(count+"/"+data.size());
sum[0] += 1.0 * count / data.size() * getEnt(counts);
});
//计算信息增益
return ent - sum[0];
}
//计算信息熵
private double getEnt(List<Integer> attrCount) {
int sum = 0;
for (Integer a : attrCount) {
sum += a;
}
double res = 0;
for (Integer a : attrCount) {
double scale = 1.0 * a / sum;
res += -scale * Math.log(scale) / Math.log(2);
}
return res;
}
//获取第col列的每个值有多少个
private Map<String, Integer> getValueCount(List<List<String>> data, int col) {
Map<String, Integer> map = new HashMap<>();
data.forEach(d -> {
String colStr = d.get(col);
Integer orDefault = map.getOrDefault(colStr, 0);
map.put(colStr, orDefault + 1);
});
return map;
}
//获取每一列可能的取值
private Map<Integer, List<String>> getColValues(List<List<String>> data) {
Map<Integer, List<String>> res = new HashMap<>();
//获取每一列的值,放入Set中去重
List<Set<String>> list = new ArrayList<>();
for (int i = 0; i < getColCount(); i++) {
Set<String> set = new HashSet<>();
list.add(set);
}
for (int i = 0; i < getRowCount(); i++) {
List<String> dataI = data.get(i);
for (int j = 0; j < dataI.size(); j++) {
list.get(j).add(dataI.get(j));
}
}
//转map
for (int i = 0; i < list.size(); i++) {
res.put(i, new ArrayList<>(list.get(i)));
}
return res;
}
// String类型数据转为二维数组链表
private List<List<String>> getString(String s) {
if (!s.contains(";")) {
s = s.replaceAll("\n", ";");
}
List<List<String>> res = new ArrayList<>();
String[] row = s.split(";");
for (String r : row) {
List<String> rowList = new ArrayList<>(Arrays.asList(r.split(",")));
res.add(rowList);
}
return res;
}
//数据集有多少行
public int getRowCount() {
return data.size();
}
//数据集有多少列
public int getColCount() {
return data.get(0).size();
}
}
class Node {
String val;//如果是属性,则是一个数字,表示第几列的属性;否则表示具体的属性值
boolean isAttr;//是属性,而不是属性值
List<Node> next;
@Override
public String toString() {
return "{" + val + ", " + next + "}";
}
}
贝叶斯算法
- x表示要预测的数据
- data表示数据集
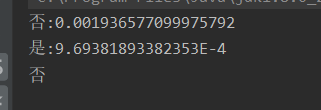
- 本例运行结果:(最终否对应的值大,所以预测结果为否)
import java.util.*;
import java.util.stream.Collectors;
/**
* @author: liangjiayy
**/
public class BayeMain {
public static void main(String[] args) {
String x = "青绿,蜷缩,沉闷,稍糊,稍凹,硬滑";
String data =
"青绿,蜷缩,浊响,清晰,凹陷,硬滑,是\n" +
"乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,是\n" +
"乌黑,蜷缩,浊响,清晰,凹陷,硬滑,是\n" +
"青绿,蜷缩,沉闷,清晰,凹陷,硬滑,是\n" +
"浅白,蜷缩,浊响,清晰,凹陷,硬滑,是\n" +
"青绿,稍蜷,浊响,清晰,稍凹,软粘,是\n" +
"乌黑,稍蜷,浊响,稍糊,稍凹,软粘,是\n" +
"乌黑,稍蜷,浊响,清晰,稍凹,硬滑,是\n" +
"乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑,否\n" +
"青绿,硬挺,清脆,清晰,平坦,软粘,否\n" +
"浅白,硬挺,清脆,模糊,平坦,硬滑,否\n" +
"浅白,蜷缩,浊响,模糊,平坦,软粘,否\n" +
"青绿,稍蜷,浊响,稍糊,凹陷,硬滑,否\n" +
"浅白,稍蜷,沉闷,稍糊,凹陷,硬滑,否\n" +
"乌黑,稍蜷,浊响,清晰,稍凹,软粘,否\n" +
"浅白,蜷缩,浊响,模糊,平坦,硬滑,否\n" +
"青绿,蜷缩,沉闷,稍糊,稍凹,硬滑,否";
System.out.println(new Bayes().main(data, x));
}
}
class Bayes {
public String main(String dataInput, String xInput) {
List<List<String>> data = getData(dataInput);
List<String> x = getData(xInput).get(0);
int rowNum = data.size();
int colNum = data.get(0).size();
//获取最后一列可能的属性以及个数
Map<String, Integer> values = getValuesAndCount(data, colNum - 1);
//求结果,并比大小
Set<String> keys = values.keySet();
double[] p = new double[keys.size()];
List<String> keyList = new ArrayList<>(keys);
int maxIndex = 0;
double maxValue = -1;
//对于最后一行的每一个可能的值遍历
for (int i = 0; i < keyList.size(); i++) {
String key = keyList.get(i);
Integer count = values.get(key);
p[i] = 1.0 * count / rowNum;
for (int j = 0; j < x.size(); j++) {
List<List<String>> filter = filter(data, colNum - 1, key, j, x.get(j));
p[i] *= filter.size() * 1.0 / count;
}
//找最大的那一列
if (p[i] > maxValue) {
maxIndex = i;
maxValue = p[i];
}
System.out.println(key + ":" + p[i]);
}
return keyList.get(maxIndex);
}
private List<List<String>> filter(List<List<String>> data, int col1, String colValue1, int col2, String colValue2) {
return data.stream()
.filter(d -> colValue1.equals(d.get(col1)) && colValue2.equals(d.get(col2)))
.collect(Collectors.toList());
}
private Map<String, Integer> getValuesAndCount(List<List<String>> data, int index) {
Map<String, Integer> map = new HashMap<>();
data.forEach(d -> {
String colStr = d.get(index);
Integer orDefault = map.getOrDefault(colStr, 0);
map.put(colStr, orDefault + 1);
});
return map;
}
List<List<String>> getData(String s) {
if (!s.contains(";")) {
s = s.replaceAll("\n", ";");
}
List<List<String>> res = new ArrayList<>();
String[] row = s.split(";");
for (String r : row) {
List<String> rowList = new ArrayList<>();
for (String col : r.split(",")) {
rowList.add(col);
}
res.add(rowList);
}
return res;
}
}
k-means算法
- 输入数据data是二维数组,其中每一行表示一个数据,列数表示维数。例如,本例使用的数据是二维的九个数据,支持其他维数。
- 需要设置k的值,表示最终聚成几类
- 为了防止存在误差永远无法结束,设置了最大计算次数:1000000,可通过maxFindCount 进行修改
- 注意:运行是有可能会报错的,当聚类中心选的不好的时候,去遍历就会出现数组越界异常,多运行几次即可。
- 最终的结果我展示的是原来的数据点,书上展示的是x1、x2、x3…我觉得不影响
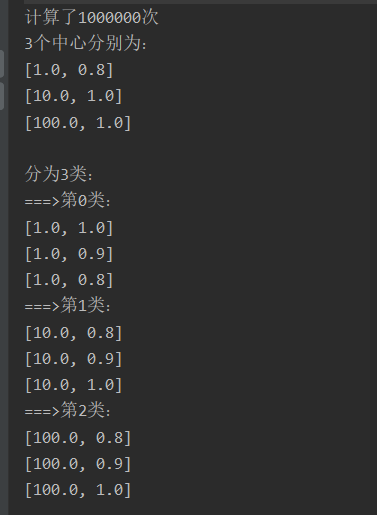
- 运行结果:
import java.util.*;
import java.util.stream.Collectors;
/**
* @author: liangjiayy
**/
public class KMeans {
public static void main(String[] args) {
//n个m维的数据
int k = 3;
//最大寻找聚类中心的次数
int maxFindCount = 1000000;
// double[][] data = new double[n][m];
double[][] data = new double[][]{
{1,1},
{1,0.9},
{1,0.8},
{10,0.8},
{10,0.9},
{10,1},
{100,0.8},
{100,0.9},
{100,1},
};
//随机产生k个初始点
List<double[]> kMeans = randKMeans(data, k);
//k个分类,每个分类下的数据
List<List<double[]>> classifications;
//计数迭代次数
int count = 0;
while (true) {
//把每一个点分到最近的中心
classifications = calculate(data, kMeans);
//计算每一个的中心
List<double[]> tmp = calculateMeans(classifications);
//当和上次的中心相同时,停止计算
if (isSame(kMeans, tmp)) {
break;
}
//防止永远达不到
if (++count >= maxFindCount) {
break;
}
}
//展示结果
System.out.println("计算了"+count+"次");
System.out.println(k+"个中心分别为:");
for (double[] kMean : kMeans) {
System.out.println(Arrays.toString(kMean));
}
System.out.println();
System.out.println("分为"+k+"类:");
for (int i = 0; i < classifications.size(); i++) {
System.out.println("===>第"+i+"类:");
for (double[] doubles : classifications.get(i)) {
System.out.println(Arrays.toString(doubles));
}
}
}
/**
* 比较两个中心是否相同
* @param list1
* @param list2
* @return
*/
private static boolean isSame(List<double[]> list1, List<double[]> list2) {
sortDoubleArray(list1);
sortDoubleArray(list2);
for (int i = 0; i < list1.size(); i++) {
double[] doublesArr1 = list1.get(i);
double[] doublesArr2 = list2.get(i);
for (int j = 0; j < doublesArr1.length; j++) {
if (doublesArr1[j] != doublesArr2[j]) {
return false;
}
}
}
return true;
}
/**
* 按每一维升序排序
*
* @param list
*/
private static void sortDoubleArray(List<double[]> list) {
list.sort((a, b) -> {
for (int i = 0; i < a.length; i++) {
if (a[i] != b[i]) {
return (int) (a[i] - b[i]);
}
}
//每一位都相同
return 0;
});
}
/**
* 计算每一组数据的中心
*
* @param data
* @return
*/
private static List<double[]> calculateMeans(List<List<double[]>> data) {
int count = data.get(0).size();
//计算每一个的中心
List<double[]> collect = data.stream().map(doublesList -> {
double[] res = new double[doublesList.get(0).length];
Arrays.fill(res, 0);
//加上每一个数据
doublesList.forEach(doubles -> {
for (int i = 0; i < doubles.length; i++) {
res[i] += doubles[i];
}
});
//求均值
for (int i = 0; i < res.length; i++) {
res[i] /= count;
}
return res;
}).collect(Collectors.toList());
return collect;
}
/**
* 根据中心把每一个数据分到对应的类中
*
* @param data
* @param kMeans
* @return
*/
private static List<List<double[]>> calculate(double[][] data, List<double[]> kMeans) {
Map<Integer, List<double[]>> map = new HashMap<>(kMeans.size());
for (int i = 0; i < kMeans.size(); i++) {
map.put(i, new ArrayList<>());
}
int index;
for (int i = 0; i < data.length; i++) {
//获取最近的一个中心的索引
index = getMinMeansIndex(data[i], kMeans);
map.get(index).add(data[i]);
}
List<List<double[]>> res = new ArrayList<>(map.values());
return res;
}
/**
* 获取最近的一个中心的索引
*/
private static int getMinMeansIndex(double[] x, List<double[]> kMeans) {
//计算到每个中心的距离
double[] distant = new double[kMeans.size()];
for (int i = 0; i < kMeans.size(); i++) {
distant[i]=calculateDistant(kMeans.get(i), x);
}
int index=0;
double val=distant[0];
for (int i = 1; i < distant.length; i++) {
if (distant[i]<val){
index=i;
}
}
return index;
}
/**
* 计算两个点之间的距离
* @param x1
* @param x2
* @return
*/
private static double calculateDistant(double[] x1, double[] x2) {
double res = 0;
for (int i = 0; i < x1.length; i++) {
res += Math.pow(x1[i]-x2[i], 2);
}
return Math.pow(res, 0.5);
}
/**
* 随机选k个中心
* @param data
* @param k
* @return
*/
private static List<double[]> randKMeans(double[][] data, int k) {
List<double[]> collect = Arrays.stream(data).collect(Collectors.toList());
Collections.shuffle(collect);
List<double[]> res = new ArrayList<>();
for (int i = 0; i < k; i++) {
res.add(collect.get(i));
}
return res;
}
}
AGNES (凝聚的层次聚类算法)
- 设置k的值,表示最终聚成几类
- data是二维数据,每一行是一个数据,列数表示维数,可以是任意维数,但必须所有数据维数一致
- 运行结果:
将1和2合并成一个簇 合成后的结果为: ===>第1类: [2.0, 1.0] ===>第2类: [2.0, 2.0] ===>第3类: [3.0, 4.0] ===>第4类: [3.0, 5.0] ===>第5类: [4.0, 4.0] ===>第6类: [4.0, 5.0] ===>第7类: [1.0, 1.0] [1.0, 2.0] 将1和2合并成一个簇 合成后的结果为: ===>第1类: [3.0, 4.0] ===>第2类: [3.0, 5.0] ===>第3类: [4.0, 4.0] ===>第4类: [4.0, 5.0] ===>第5类: [1.0, 1.0] [1.0, 2.0] ===>第6类: [2.0, 1.0] [2.0, 2.0] 将1和2合并成一个簇 合成后的结果为: ===>第1类: [4.0, 4.0] ===>第2类: [4.0, 5.0] ===>第3类: [1.0, 1.0] [1.0, 2.0] ===>第4类: [2.0, 1.0] [2.0, 2.0] ===>第5类: [3.0, 4.0] [3.0, 5.0] 将1和2合并成一个簇 合成后的结果为: ===>第1类: [1.0, 1.0] [1.0, 2.0] ===>第2类: [2.0, 1.0] [2.0, 2.0] ===>第3类: [3.0, 4.0] [3.0, 5.0] ===>第4类: [4.0, 4.0] [4.0, 5.0] 将1和2合并成一个簇 合成后的结果为: ===>第1类: [3.0, 4.0] [3.0, 5.0] ===>第2类: [4.0, 4.0] [4.0, 5.0] ===>第3类: [1.0, 1.0] [1.0, 2.0] [2.0, 1.0] [2.0, 2.0] 将1和2合并成一个簇 合成后的结果为: ===>第1类: [1.0, 1.0] [1.0, 2.0] [2.0, 1.0] [2.0, 2.0] ===>第2类: [3.0, 4.0] [3.0, 5.0] [4.0, 4.0] [4.0, 5.0]
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* @author: liangjiayy
**/
public class AGNES {
public static void main(String[] args) {
//最终聚成几类
int k = 2;
//任意维数,任意个数的数据
double[][] data = new double[][]{
{1, 1},
{1, 2},
{2, 1},
{2, 2},
{3, 4},
{3, 5},
{4, 4},
{4, 5},
};
//初始化数据,每一个外层list是一个类
List<List<double[]>> dataList = init(data);
while (dataList.size() > k) {
//计算距离
double[][] distants = calculateDistant(dataList);
//找最小的距离对应下标
int[] min = findMin(distants);
System.out.println("将" + (1 + min[0]) + "和" + (1 + min[1]) + "合并成一个簇");
//将该类聚成新类
dataList = aggNewClass(dataList, min);
System.out.println("合成后的结果为:");
for (int i = 0; i < dataList.size(); i++) {
System.out.println("===>第" + (i + 1) + "类:");
for (double[] doubles : dataList.get(i)) {
System.out.println(Arrays.toString(doubles));
}
}
System.out.println();
}
}
/**
* 根据最近的距离的两个类的下标和数据进行聚类操作
*
* @param dataList
* @param min
* @return
*/
private static List<List<double[]>> aggNewClass(List<List<double[]>> dataList, int[] min) {
//取出要聚类的两个类
List<double[]> list1 = dataList.get(min[0]);
List<double[]> list2 = dataList.get(min[1]);
//不破坏原数据结构,获得新类
ArrayList<double[]> newClass = new ArrayList<>(list1);
newClass.addAll(new ArrayList<>(list2));
//构造一个和原数据一样的数据
List<List<double[]>> res = new ArrayList<>(dataList);
//删除对应索引的数据
Arrays.sort(min);
res.remove(min[1]);
res.remove(min[0]);
//添加新类
res.add(newClass);
return res;
}
/**
* 初始化数据为List<List<double[]>>,方便后面给每个类添加数据
*
* @param data
* @return
*/
private static List<List<double[]>> init(double[][] data) {
List<List<double[]>> res = new ArrayList<>();
for (double[] row : data) {
ArrayList<double[]> rowList = new ArrayList<double[]>() {{
add(row);
}};
res.add(rowList);
}
return res;
}
/**
* 找最小距离对应的下标
*
* @param distants
* @return
*/
private static int[] findMin(double[][] distants) {
int[] res = new int[2];
double min = -1;
for (int i = 0; i < distants.length; i++) {
for (int j = i + 1; j < distants.length; j++) {
if (min == -1 || min > distants[i][j]) {
min = distants[i][j];
res[0] = i;
res[1] = j;
}
}
}
return res;
}
/**
* 计算每两个数据之间的距离
*
* @param data
* @return
*/
private static double[][] calculateDistant(List<List<double[]>> data) {
double[][] res = new double[data.size()][data.size()];
for (int i = 0; i < data.size(); i++) {
Arrays.fill(res[i], 0);
for (int j = i + 1; j < data.size(); j++) {
double distant = calculateMinDistant(data.get(i), data.get(j));
res[i][j] = distant;
res[j][i] = distant;
}
}
return res;
}
/**
* 计算两组数据之间的最小距离
*
* @param x1
* @param x2
* @return
*/
private static double calculateMinDistant(List<double[]> x1, List<double[]> x2) {
double min = -1;
for (double[] x : x1) {
for (double[] y : x2) {
double distant = calculateDistant(x, y);
if (min == -1) {
min = distant;
} else {
min = Math.min(distant, min);
}
}
}
return min;
}
/**
* 计算两个点之间的距离
*
* @param x1
* @param x2
* @return
*/
private static double calculateDistant(double[] x1, double[] x2) {
double res = 0;
for (int i = 0; i < x1.length; i++) {
res += Math.pow(x1[i] - x2[i], 2);
}
return Math.pow(res, 0.5);
}
}















 187
187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









