







目录
1.2.1 np.genfromtxt()函数:带缺失数据文件读取
1.处理数据文件
1.1 文本文件
以ASCII码方式存储的文件。常见的有txt,doc,docx,pdf,csv等。
(1) 将数组保存到文本文件:
numpy.savetxt(fname, X, fmt='%.18e', delimiter=' ', newline='\n', header='', footer='', comments='# ', encoding=None)[source]fname:表示要保存文件的地址,可以自己建文件名,如‘test.txt’
X:表示要保存的文件
delimiter :分隔符,默认空格,也可以用逗号等
newline:表示换行的时候用什么,默认\n,表示换一行,也可以用\t,则表示空四格
header:表示头文件,如“test_data"
footer: 文件下的脚注
comment:注释,默认是#,因为python的注释是#,也可以用其它符号

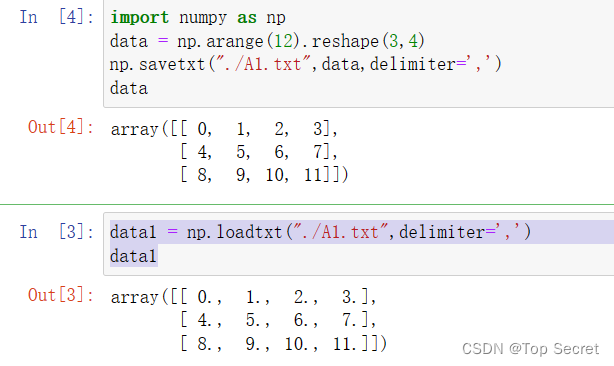
(2) 从文本加载数据:
numpy.loadtxt(fname, dtype=, comments=’#’, delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0)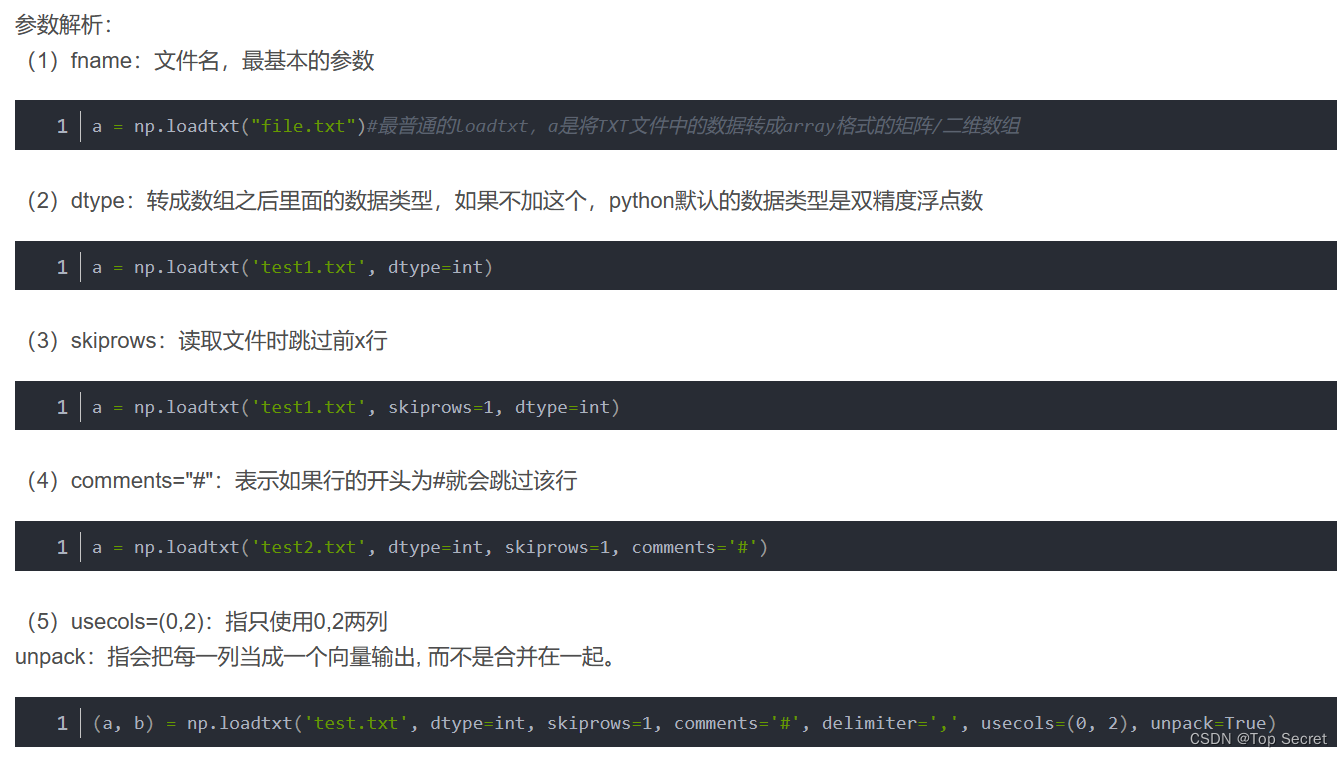
1.2 例子:如何将数据导入和导出csv文件
1.2.1 np.genfromtxt()函数:带缺失数据文件读取
导入数据的标准方法是使用np.genfromtxt函数,它可以从web URLs导入数据,处理缺失值,多种分隔符,处理不规则的列数等功能。一个不太通用的版本是用np.loadtxt函数导入数据,它假设数据集无缺失值。
# 关闭数字的科学表示方法np.set_printoptions(suppress=True)
# 从url的csv文件导入数据path = 'https://raw.githubusercontent.com/selva86/datasets/master/Auto.csv'
# delimiter:分隔符
# skip_header:从多少行开始读数据,以0开始
# filling_values:缺失值表示
# dtype:数据类型
# data = np.genfromtxt(path, delimiter=',', skip_header=1, filling_values=-999, dtype='float')
# data[:3] # 显示前3行数据
import numpy as np
path = 'https://raw.githubusercontent.com/selva86/datasets/master/Auto.csv'
data = np.genfromtxt(path,delimiter=',',skip_header=1,filling_values=-999,dtype='float')
print(data[:3])
若设置参数dtype为'object'或'None',np.genfromtxt在未设置占位符的前提下能同时处理具有数字和文本列的数据集.
1.2.2 np.savetxt()函数
最后,'np.savetxt'将数据保存为csv文件:
# 保存数据为csv文件np.savetxt("out.csv", data, delimiter=",")
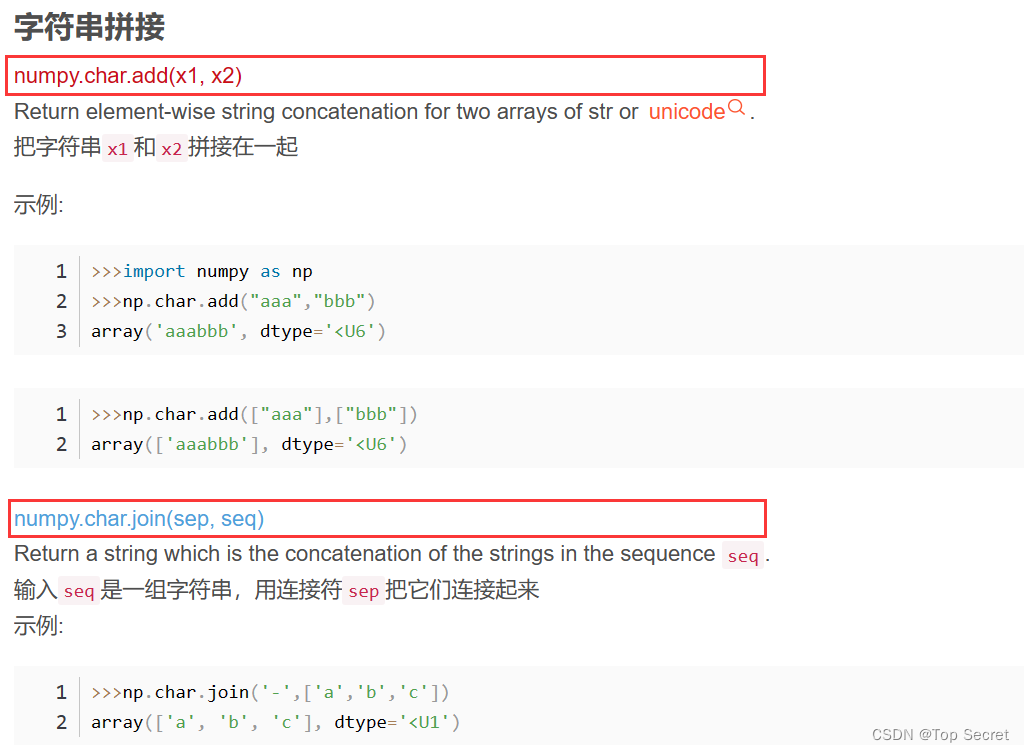
2.字符串处理
2.1 字符串操作方法
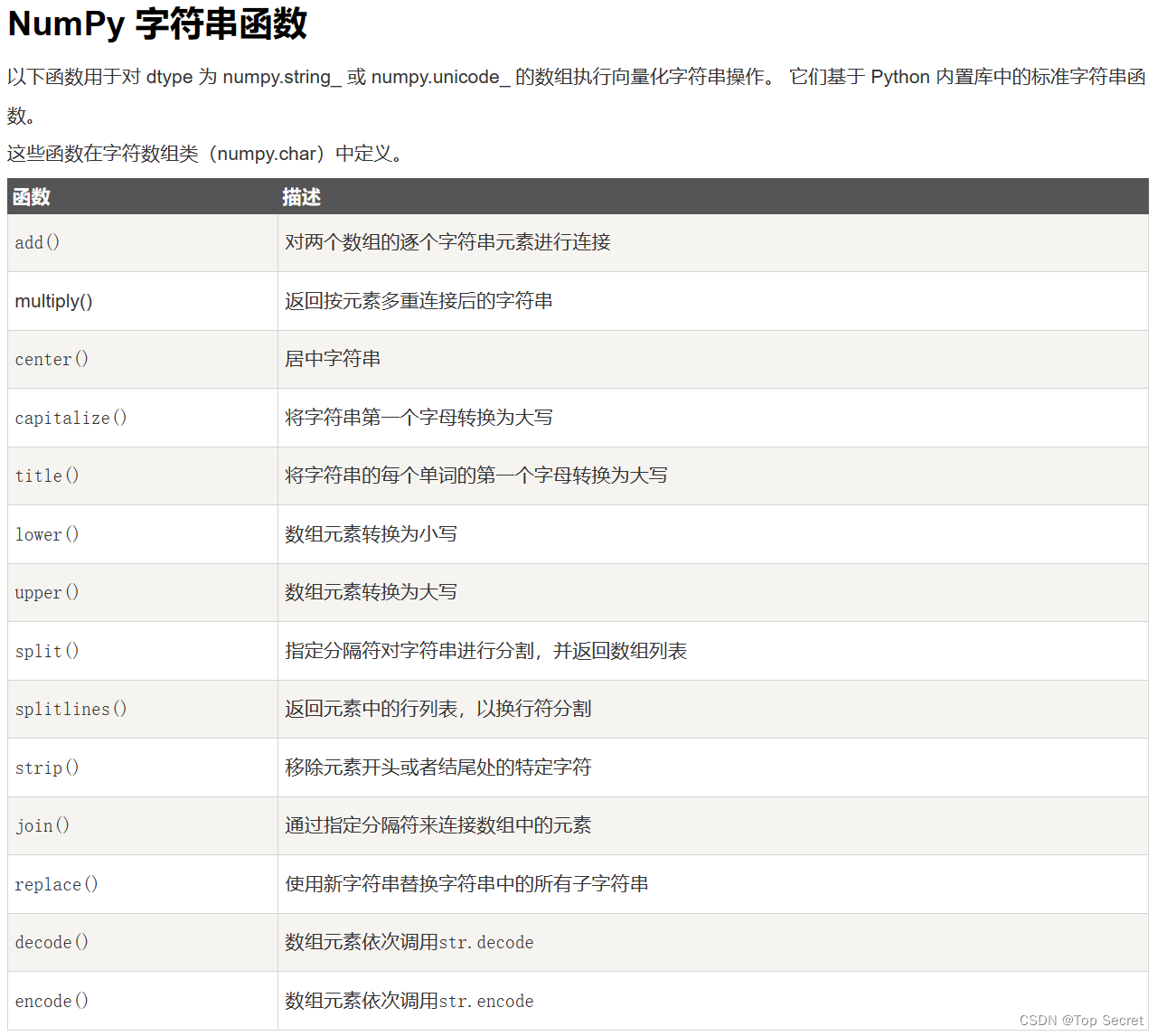
2.2 字符串拼接
3.导读
(16条消息) numpy字符串处理_numpy 字符串_patrickpdx的博客-CSDN博客
NumPy 字符串函数 | 菜鸟教程 (runoob.com)

















 1088
1088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











