







目录
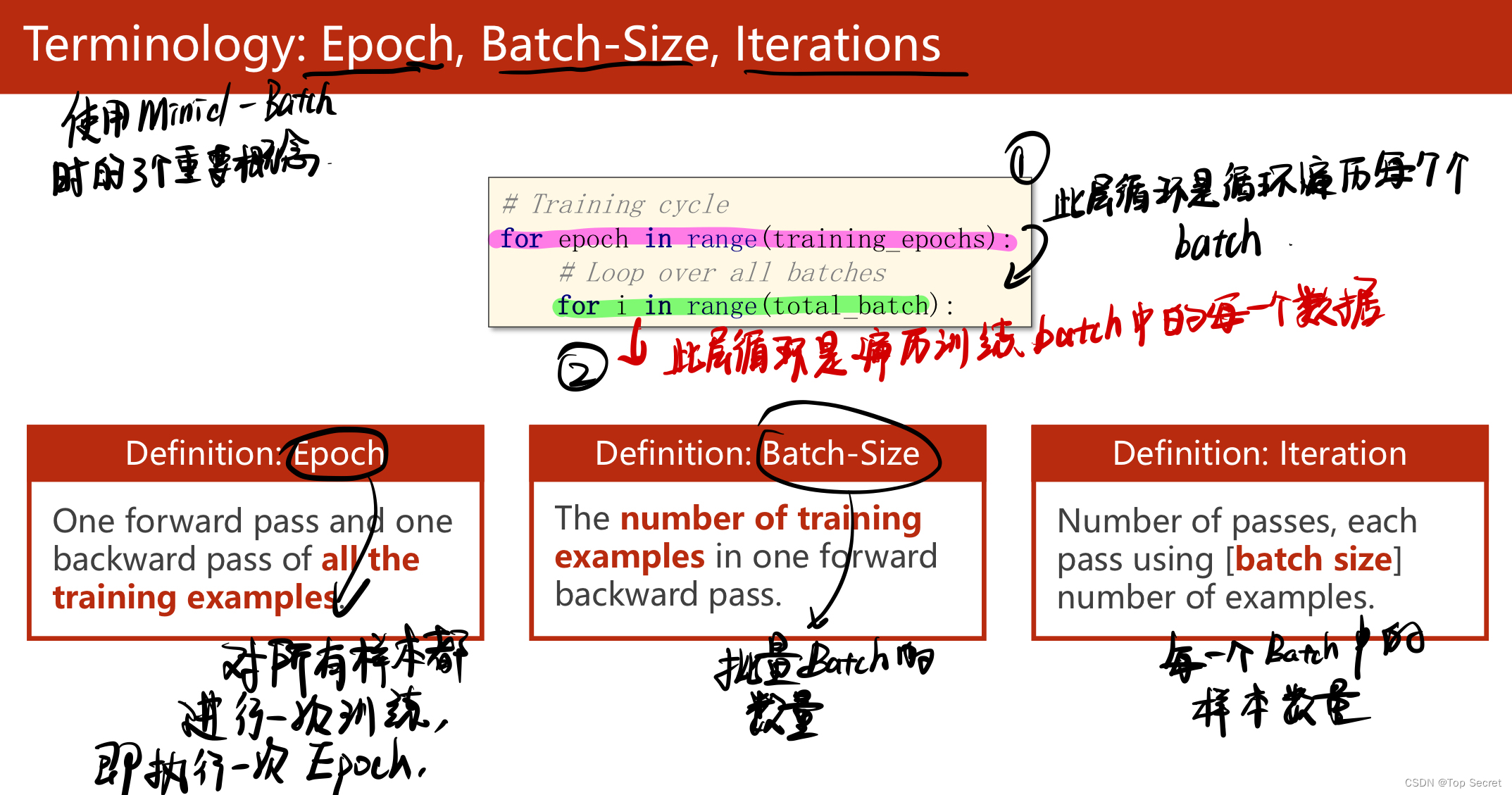
2.使用Minid-Batch,epoch,Batch-Size,lterations
3.1 from torch.utils.data import Dataset,DataLoader
3.1.1 torch.utils.data.Dataset
3.1.2 torch.utils.data.DataLoader
3.2.1 创建Dataset 对象:torch.utils.data.Dataset(构建数据集)
3.2.2 将构建的数据集载入:torch.utils.data.DataLoader
6.关于torchvision.datasets中的内置数据集
PyTorch 深度学习实践 第8讲_错错莫的博客-CSDN博客
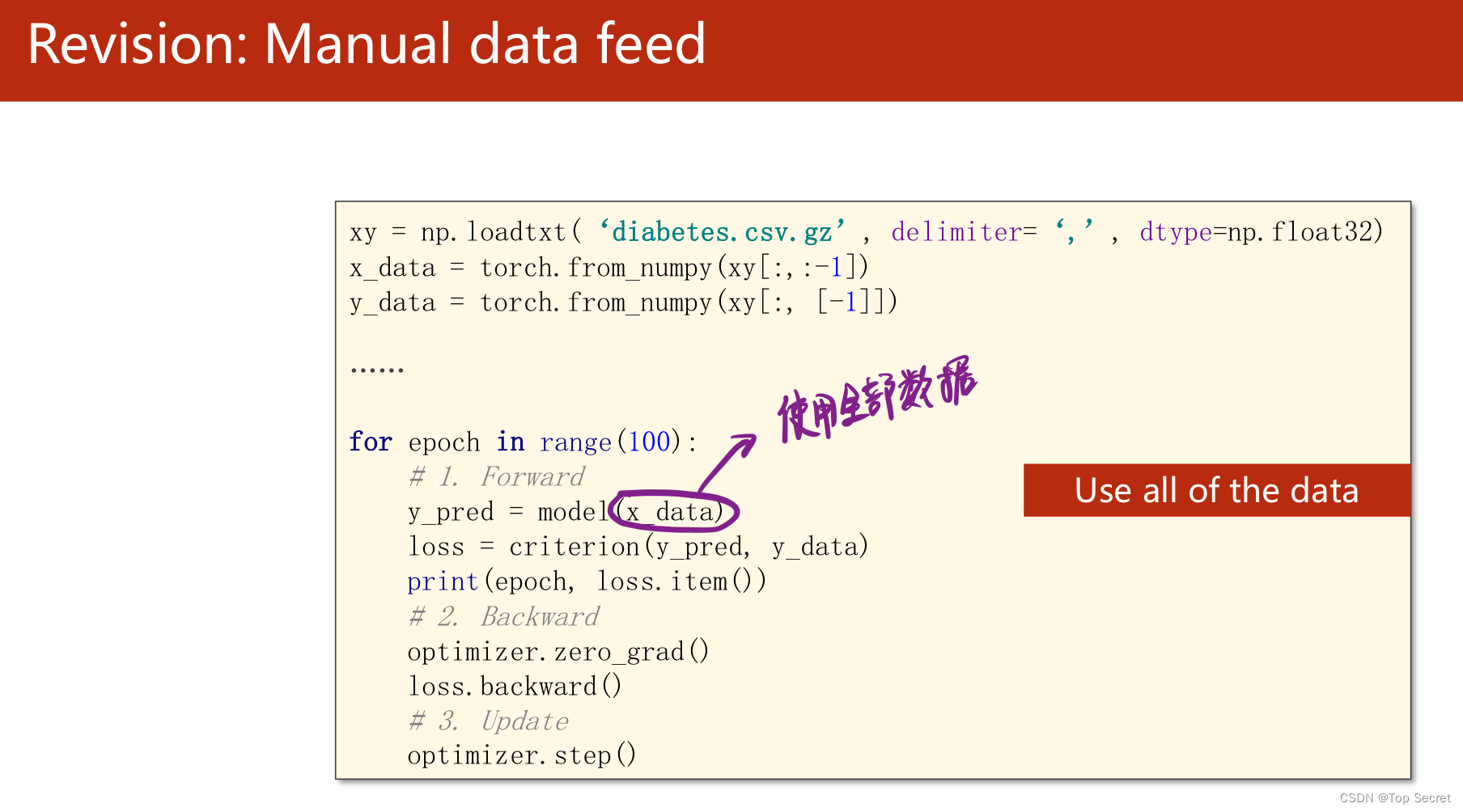
1. 直接加载全部数据集做运算
2.使用Minid-Batch,epoch,Batch-Size,lterations
3.对于数据集的的定义

3.1 from torch.utils.data import Dataset,DataLoader
简介:
在使用Pytorch构建和训练模型的过程中,经常需要把原始数据(图片、文本等)转换为张量的格式。对于小数据集,我们可以手动导入,但是在深度学习中,数据集往往是比较大的,这时pytorch的数据导入功能便发挥了作用,Pytorch导入数据主要依靠 torch.utils.data.DataLoader和 torch.utils.data.Dataset这两个类来完成。
......................................................................................................................................................
pytorch提供了一个数据读取的方法,使用了 torch.utils.data.Dataset 和 torch.utils.data.DataLoader。要自定义自己数据的方法,就要继承 torch.utils.data.Dataset,实现了数据读取以及数据处理方式,并得到相应的数据处理结果。然后将 Dataset封装到 DataLoader中,可以实现了单/多进程迭代输出数据。

3.1.1 torch.utils.data.Dataset

from torch.utils.data import DataLoader, Dataset
import torch
class MyDataset(Dataset):
# TensorDataset继承Dataset, 重载了__init__, __getitem__, __len__
# 能够通过index得到数据集的数据,能够通过len得到数据集大小
def __init__(self, data_tensor, target_tensor):
self.data_tensor = data_tensor
self.target_tensor = target_tensor
def __getitem__(self, index):
return self.data_tensor[index], self.target_tensor[index]
def __len__(self):
return self.data_tensor.size(0)
# 生成数据
data_T = torch.randn(4, 3) #数据
label_T = torch.rand(4) #标签
tensor_dataset = MyDataset(data_T, label_T) # 将数据封装成Dataset
print('tensor_data[0]: ', tensor_dataset[0])
print('len(tensor_data): ', len(tensor_dataset))

3.1.2 torch.utils.data.DataLoader

tensor_dataloader = DataLoader(tensor_dataset, # 封装的对象
batch_size=2, # 输出的batchsize
shuffle=True, # 随机输出
num_workers=0) # 只有1个进程
# 以for循环形式输出
for data, target in tensor_dataloader:
print(data, target)
print('one batch tensor data: ', iter(tensor_dataloader).next()) # 输出一个batch
print('len of batchtensor: ', len(list(iter(tensor_dataloader)))) # 输出batch数量

DataLoader 的参数简介:
from torch.utils.data import DataLoader
DataLoader(
dataset,
batch_size,
shuffle=False, #在每个 epoch 开始时,是否对数据进行打乱
sampler=None, #自定义从数据集中取样本的策略,如果指定这个参数,那么shuffle必须为False
batch_sample=None,
#与sampler类似,但是一次只返回一个batch的indices(索引),需要注意的是,
#一旦指定了这个参数,那么batch_size,shuffle,sampler,drop_last就不能再制定了
num_workers=0, #使用几个进程来获取并处理数据
collate_fn=None, #将一个list的sample组成一个mini-batch的函数
pin_memory=False, #如果设置为True,那么data loader将会在返回它们之前,将tensors拷贝到CUDA中的固定内存中。
# pin_memory可在cpu主存(内存)中分配不可交换到swap(缓存)的内存。
# 默认内存分配中的数据都可交换到swap中,那CUDA驱动会通过DRAM机制将数据从内存传到GPU显存时会复制2次
# (先复制到一临时不可见pinned固定内存,再往显存中复制),
# 因此pin_memory=True可提高约2倍cpu到gpu传输效率(.cuda()或 .to(device)的时候)
drop_last=False,
#为True:一个 epoch 的最后一组数据<batch 时,则被丢弃,不进行训练
#为False:继续正常执行,只是最后的batch_size会小一点。
timeout=0,
#如果是正数,表明等待从worker进程中收集一个batch等待的时间,若超出设定的时间还没有收集到,
#那就不收集这个内容了。这个数值应总是大于等于0。默认为
worker_init_fn=None
#每个worker初始化函数 。一般并不进行设置
)
3.2 pytorch 的数据加载到模型的操作顺序

dataset = MyDataset()
dataloader = DataLoader(dataset)
num_epoches = 100
for epoch in range(num_epoches):
for img, label in dataloader:
....
3.2.1 创建Dataset 对象:torch.utils.data.Dataset(构建数据集)
torch.utils.data.Dataset可通过两种方式生成,一种是通过内置的下载功能,另一种便是自己实现。下载功能需要借助一些其他的包,比如torchvision,下载CIFAR10数据格式大致如下:
(1)通过内置的下载功能:
import torch
import torchvision
cf10_data = torchvision.datasets.CIFAR10('dataset/cifar/', download=True)
(2)自定义数据集:
任何自定义的数据集都要继承自torch.utils.data.Dataset
import torch
from torch.utils.data import Dataset
class myDataset(Dataset):
def __init__(self):
#创建5*2的数据集
self.data = torch.tensor([[1,2],[3,4],[2,1],[3,4],[4,5]])
#5个数据的标签
self.label = torch.tensor([0,1,0,1,2])
#根据索引获取data和label
def __getitem__(self,index):
return self.data[index], self.label[index] #以元组的形式返回
#获取数据集的大小
def __len__(self):
return len(self.data)
data = myDataset()
print(f'data size is : {len(data)}')
print(data[1]) #获取索引为1的data和label
3.2.2 将构建的数据集载入:torch.utils.data.DataLoader
torch.utils.data.Dataset通过__getitem__获取单个数据,如果希望获取批量数据、shuffle或者其它的一些操作,那么就要由torch.utils.data.DataLoader来实现了,它的实现形式如下:
data.DataLoader(
dataset,
batch_size = 50,
shuffle = False,
sampler=None,
batch_sampler = None,
num_workers = 0,
collate_fn =
pin_memory = False,
drop_last = False,
timeout = 0,
worker_init_fn = None,
)

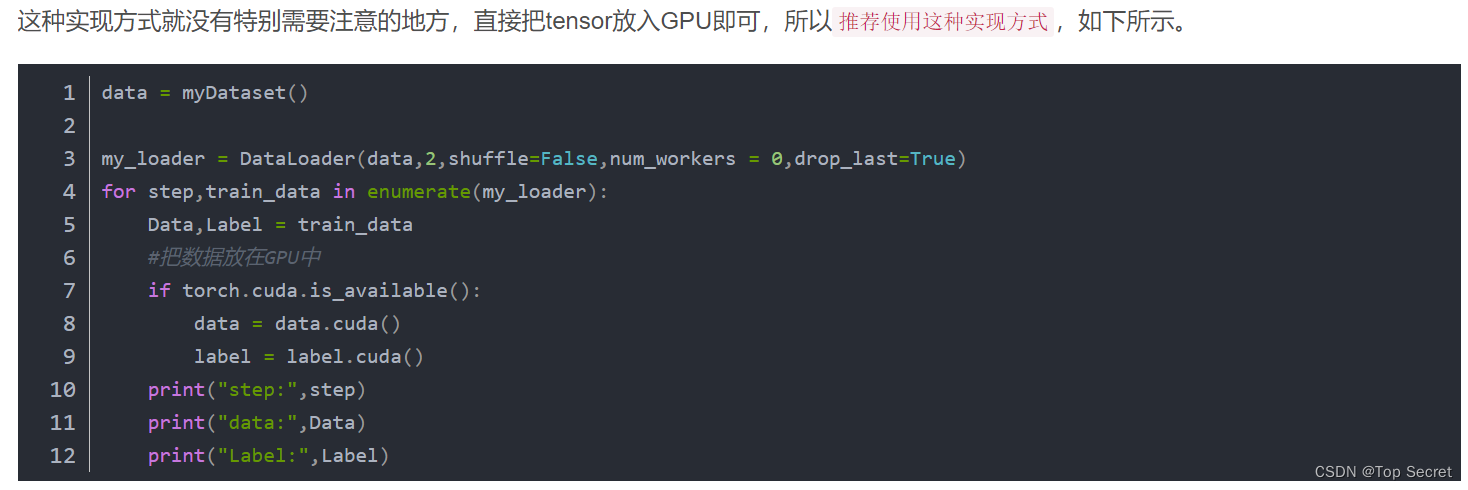
按照上面的Dataset,使用DataLoader加载数据示例如下,因为设置了drop_last = True,所以最后一个batch会被丢弃。
from torch.utils.data import DataLoader
data = myDataset()
my_loader = DataLoader(data,batch_size=2,shuffle=False,num_workers = 0,drop_last=True)
for step,train_data in enumerate(my_loader):
Data,Label = train_data
print("step:",step)
print("data:",Data)
print("Label:",Label)

3.2.3 把数据放入GPU中
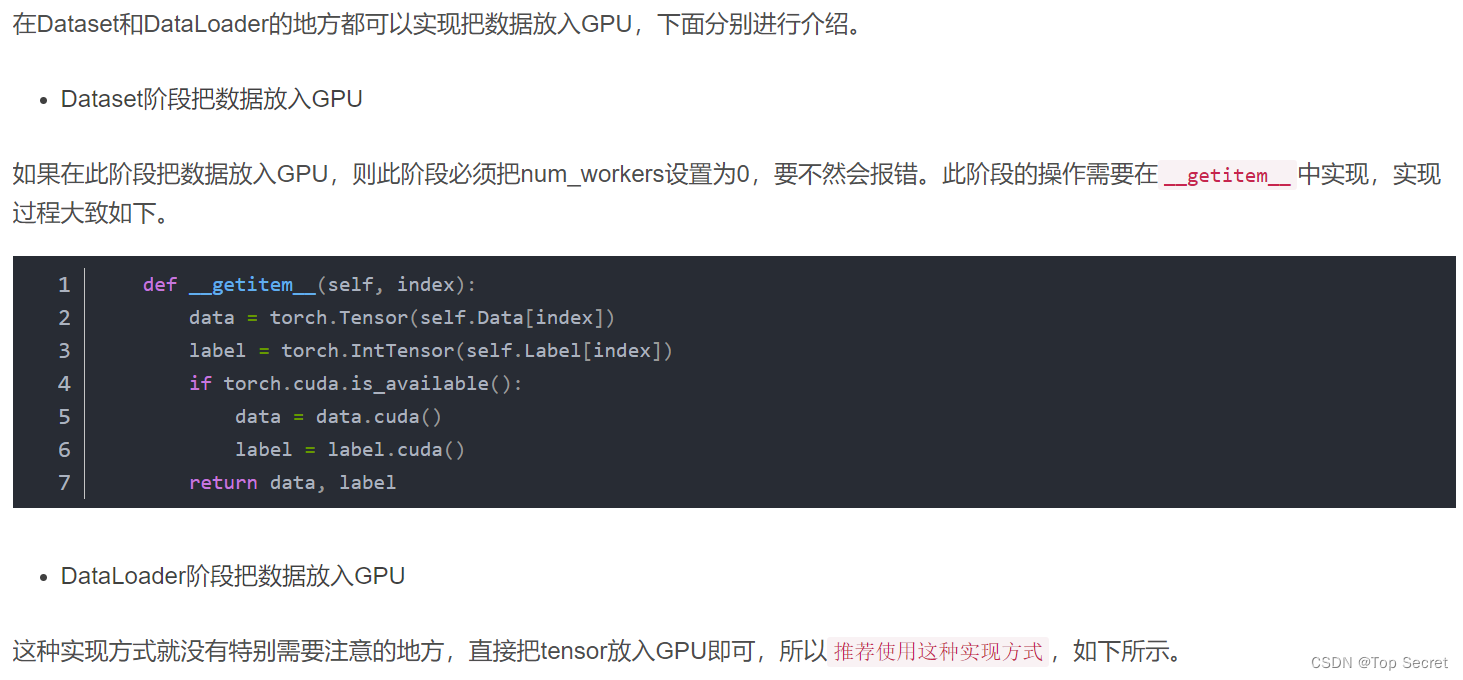
 注意:如上部分参考如下文章,侵删
注意:如上部分参考如下文章,侵删
pytorch中的数据导入之DataLoader和Dataset的使用介绍_非晚非晚的博客-CSDN博客_python导入dataset
3.3 自定义糖尿病数据集


4.训练数据

5.划分糖尿病患者的完整代码

5.1 勘误代码
import torch
import numpy as np
from torch.utils.data import Dataset,DataLoader
#step1:自定义构建糖尿病数据集,继承torch.utils.data.Dataset类
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath,delimiter=',',dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:,:-1])
self.y_data = torch.from_numpy(xy[:,[-1]]) #取每行的最后一个元素作为lable
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
#实例化糖尿病数据集
dataset = DiabetesDataset('diabetes.csv.gz')
#载入数据集
train_loader = DataLoader(dataset=dataset,
batch_size=32,
shuffle=True,
num_workers=2
) # num_workers 多线程
#step2:构建训练数据的神经网络模型,继承torch.nn.Module
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
self.sigmoid = torch.nn.Sigmoid()
#计算
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
#step3:计算损失函数和选择优化器
criterion = torch.nn.BCELoss(size_average=True) #分类问题:用交叉熵
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
#step4:训练
for epoch in range(100):
for i,data in enumerate(train_loader,0):
#准备数据
inputs,labels = data
#Forward
y_pred = model(inputs)
loss = criterion(y_pred,labels)
print("当前执行的epoch:",epoch,i,"loss:",loss.items())
#backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
运行代码会报如下错误: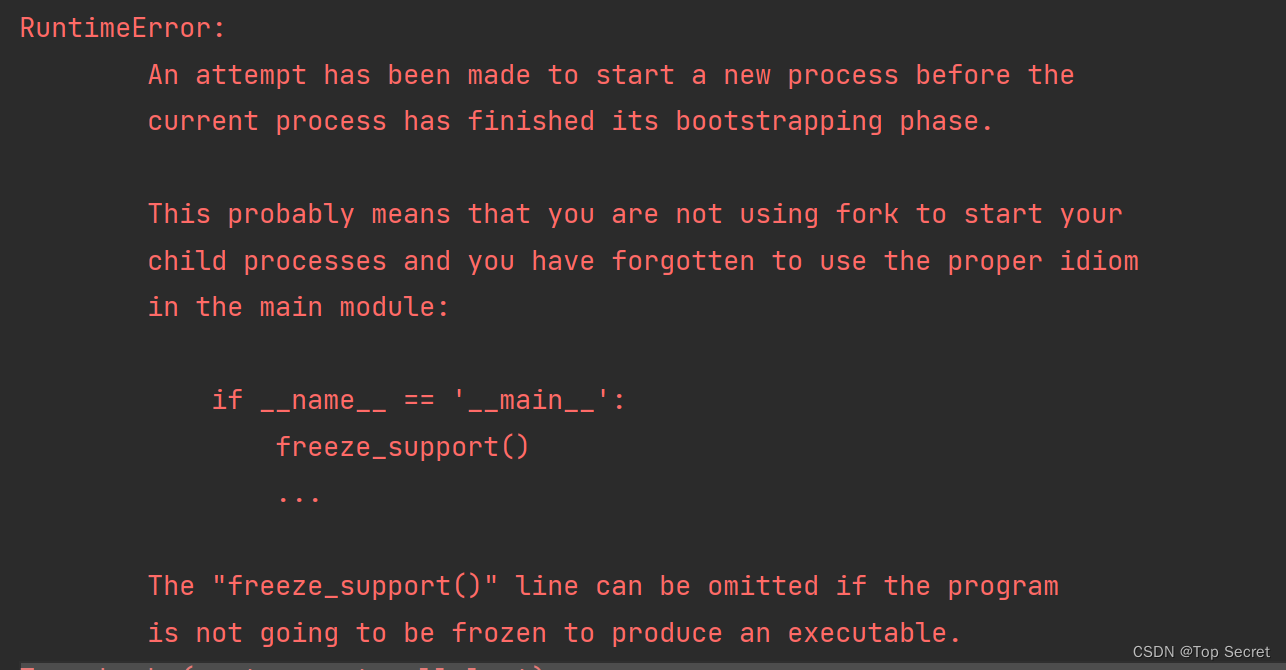 分析是对于多线程代码,需要把训练语句写在main函数中:
分析是对于多线程代码,需要把训练语句写在main函数中:
将:
#step4:训练
for epoch in range(100):
for i,data in enumerate(train_loader,0):
#准备数据
inputs,labels = data
#Forward
y_pred = model(inputs)
loss = criterion(y_pred,labels)
print("当前执行的epoch:",epoch,i,"loss:",loss.items())
#backward
optimizer.zero_grad()
loss.backward()
optimizer.step()改为:
if __name__ == '__main__':
# step4:训练
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
# 准备数据
inputs, labels = data
# Forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
#print(epoch, i, loss.item())
print("当前执行的epoch:", epoch, i, "loss:", loss.item())
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()5.2 完整代码1
import torch
import numpy as np
from torch.utils.data import Dataset,DataLoader
#step1:自定义构建糖尿病数据集,继承torch.utils.data.Dataset类
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath,delimiter=',',dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:,:-1])
self.y_data = torch.from_numpy(xy[:,[-1]]) #取每行的最后一个元素作为lable
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
#实例化糖尿病数据集
dataset = DiabetesDataset('diabetes.csv.gz')
#载入数据集
train_loader = DataLoader(dataset=dataset,
batch_size=32,
shuffle=True,
num_workers=2
) # num_workers 多线程
#step2:构建训练数据的神经网络模型,继承torch.nn.Module
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
self.sigmoid = torch.nn.Sigmoid()
#计算
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
#step3:计算损失函数和选择优化器
criterion = torch.nn.BCELoss(reduction='mean') #分类问题:用交叉熵
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
if __name__ == '__main__':
# step4:训练
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
# 准备数据
inputs, labels = data
# Forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
#print(epoch, i, loss.item())
print("当前执行的epoch:", epoch, i, "loss:", loss.item())
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
结果:
5.2 参考代码2
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
'''
Dataset是一个抽象函数,不能直接实例化,所以我们要创建一个自己类,继承Dataset
继承Dataset后我们必须实现三个函数:
__init__()是初始化函数,之后我们可以提供数据集路径进行数据的加载
__getitem__()帮助我们通过索引找到某个样本
__len__()帮助我们返回数据集大小
'''
class DiabetesDataset(Dataset):
def __init__(self,filepath):
xy = np.loadtxt(filepath,delimiter=',',dtype=np.float32)
#shape本身是一个二元组(x,y)对应数据集的行数和列数,这里[0]我们取行数,即样本数
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index],self.y_data[index]
def __len__(self):
return self.len
#定义好DiabetesDataset后我们就可以实例化他了
dataset = DiabetesDataset('./data/Diabetes_class.csv.gz')
#我们用DataLoader为数据进行分组,batch_size是一个组中有多少个样本,shuffle表示要不要对样本进行随机排列
#一般来说,训练集我们随机排列,测试集不。num_workers表示我们可以用多少进程并行的运算
train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)
class Model(torch.nn.Module):
def __init__(self):#构造函数
super(Model,self).__init__()
self.linear1 = torch.nn.Linear(8,6)#8维到6维
self.linear2 = torch.nn.Linear(6, 4)#6维到4维
self.linear3 = torch.nn.Linear(4, 1)#4维到1维
self.sigmoid = torch.nn.Sigmoid()#因为他里边也没有权重需要更新,所以要一个就行了,单纯的算个数
def forward(self, x):#构建一个计算图,就像上面图片画的那样
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()#实例化模型
criterion = torch.nn.BCELoss(size_average=False)
#model.parameters()会扫描module中的所有成员,如果成员中有相应权重,那么都会将结果加到要训练的参数集合上
optimizer = torch.optim.SGD(model.parameters(),lr=0.1)#lr为学习率
if __name__=='__main__':#if这条语句在windows系统下一定要加,否则会报错
for epoch in range(1000):
for i,data in enumerate(train_loader,0):#取出一个bath
# repare data
inputs,labels = data#将输入的数据赋给inputs,结果赋给labels
#Forward
y_pred = model(inputs)
loss = criterion(y_pred,labels)
print(epoch,loss.item())
#Backward
optimizer.zero_grad()
loss.backward()
#update
optimizer.step()
6.关于torchvision.datasets中的内置数据集

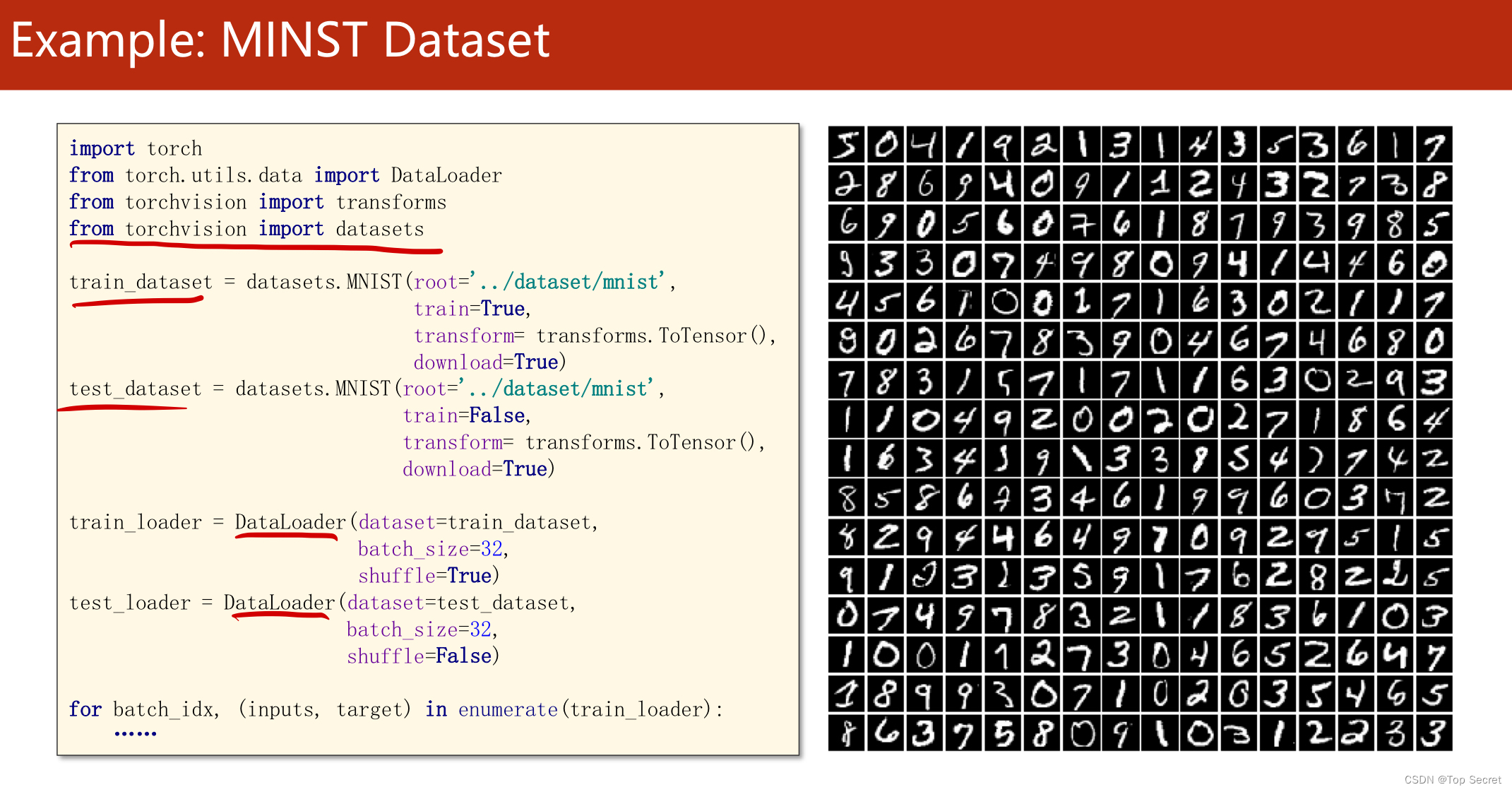
深度学习08-加载数据集复盘总结:
(其实就是,对于自定义的一些数据集,就需要我们自己去编写一些数据加载方面的代码)
(1)直接加载全部数据集做运算
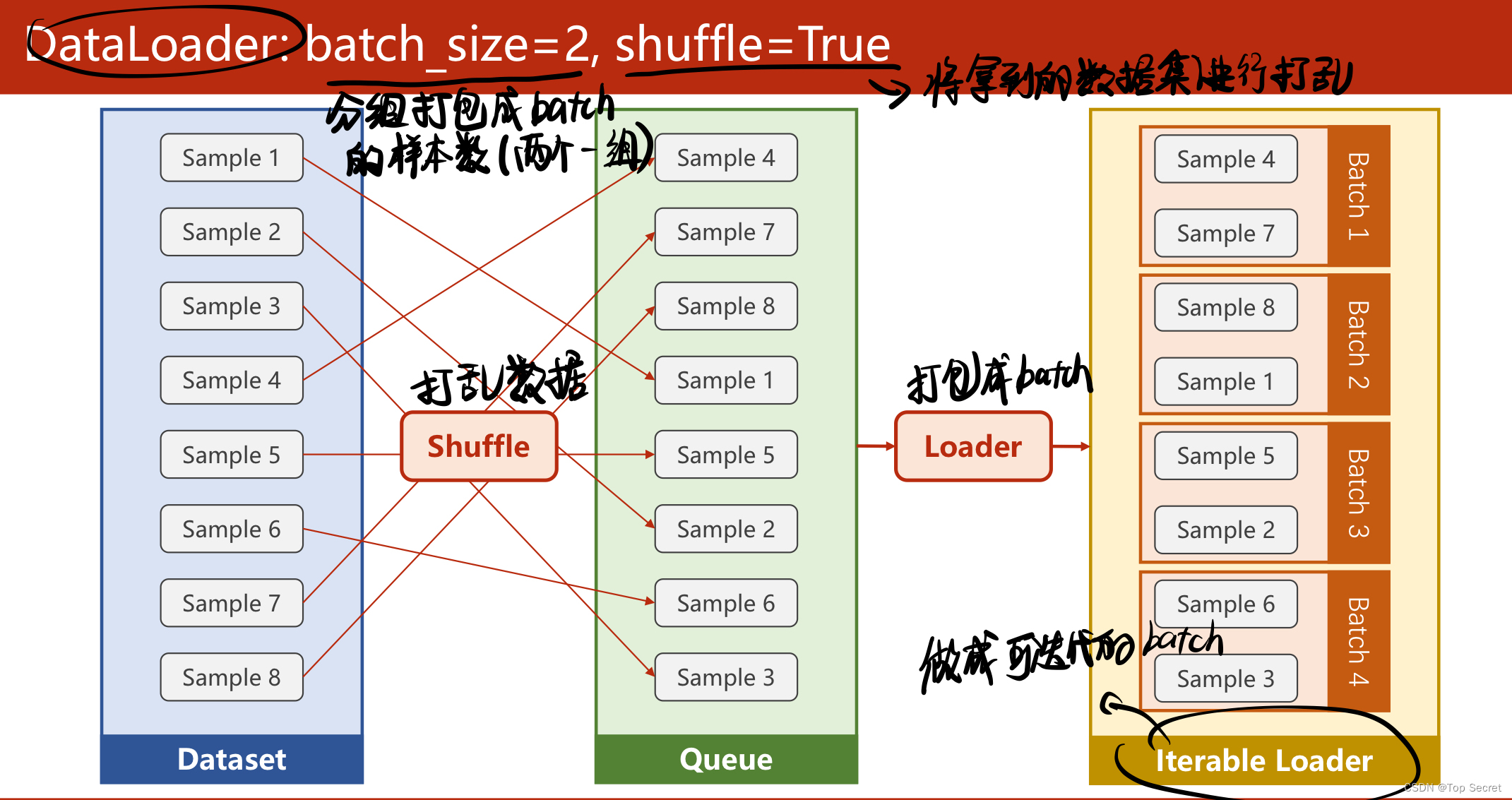
(2)(批量处理)将数据分为若干个batch,然后从每个batch中去依次遍历每一个数据;
(3)(批量处理)中,batch_size设置一个batch中的样本数量,shuffle将数据打乱;
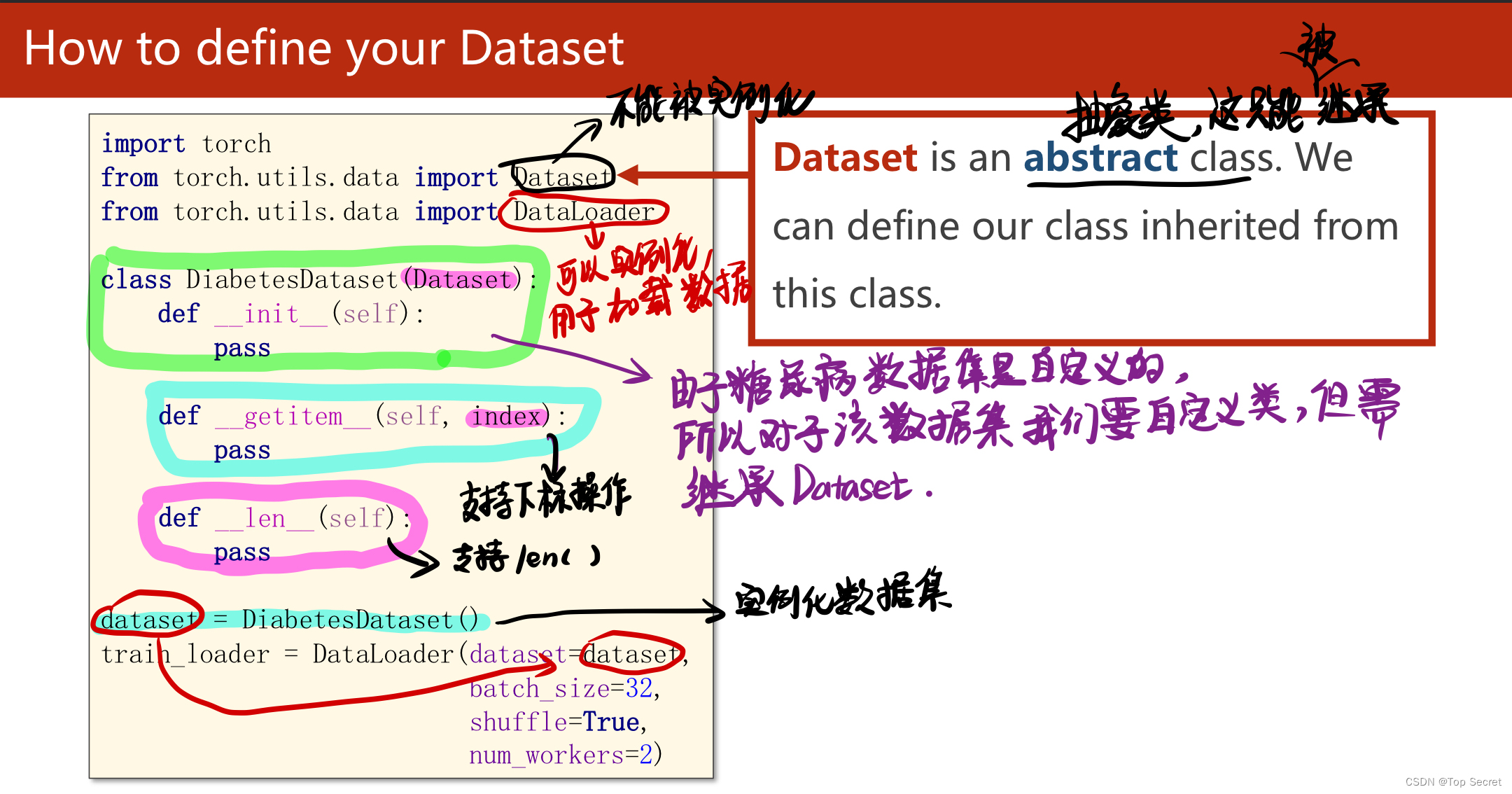
(4)在导入类时,Dataset是不能被实例化的,但DataLoader可以被实例化,用于加载数据;
(5)对于自定义的糖尿病数据集,在定义class时要继承Dataset类。在其构造函数_init_()中加载导入数 据
(6)from torch.utils.data import Dataset,DataLoader
(7)对于多线程代码,需要把训练语句写在main函数中
(6)关于torchvision.datasets中的内置数据集
pytorch 的数据加载到模型的操作顺序:
step1:创建Dataset 对象:torch.utils.data.Dataset(构建数据集)。torch.utils.data.Dataset可通过两种方式生成,一种是通过内置的下载功能,另一种便是自己实现。
step2: 将构建的数据集载入:torch.utils.data.DataLoader 。 torch.utils.data.Dataset通过__getitem__获取单个数据,如果希望获取批量数据、shuffle或者其它的一些操作,那么就要由torch.utils.data.DataLoader来实现了。
step3:把数据放入GPU中

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











