







前言
TAL(Temporal Action Localization)任务是一种计算机视觉任务,旨在从视频中准确定位和识别动作的时间段。与传统的动作识别任务不同,TAL任务不仅需要识别视频中的动作类别,还需要确定每个动作在视频时间轴上的起始时间和结束时间,TAL任务通常包括以下两个关键步骤:
动作检测(Action Detection):这一步骤的目标是在视频中检测出存在的动作,并确定它们的时间段。通常使用滑动窗口或候选区域的方法来生成候选动作片段,然后通过分类器或回归器来判断每个候选片段是否包含特定的动作类别,并预测其起始和结束时间。
动作分类(Action Classification):在动作检测的基础上,这一步骤的目标是对每个检测到的动作片段进行分类,即确定该片段属于哪个动作类别。通常使用分类器来对每个动作片段进行分类,可以是基于传统的机器学习方法,也可以是基于深度学习的方法。
一、PGCN论文摘录
1、研究动机
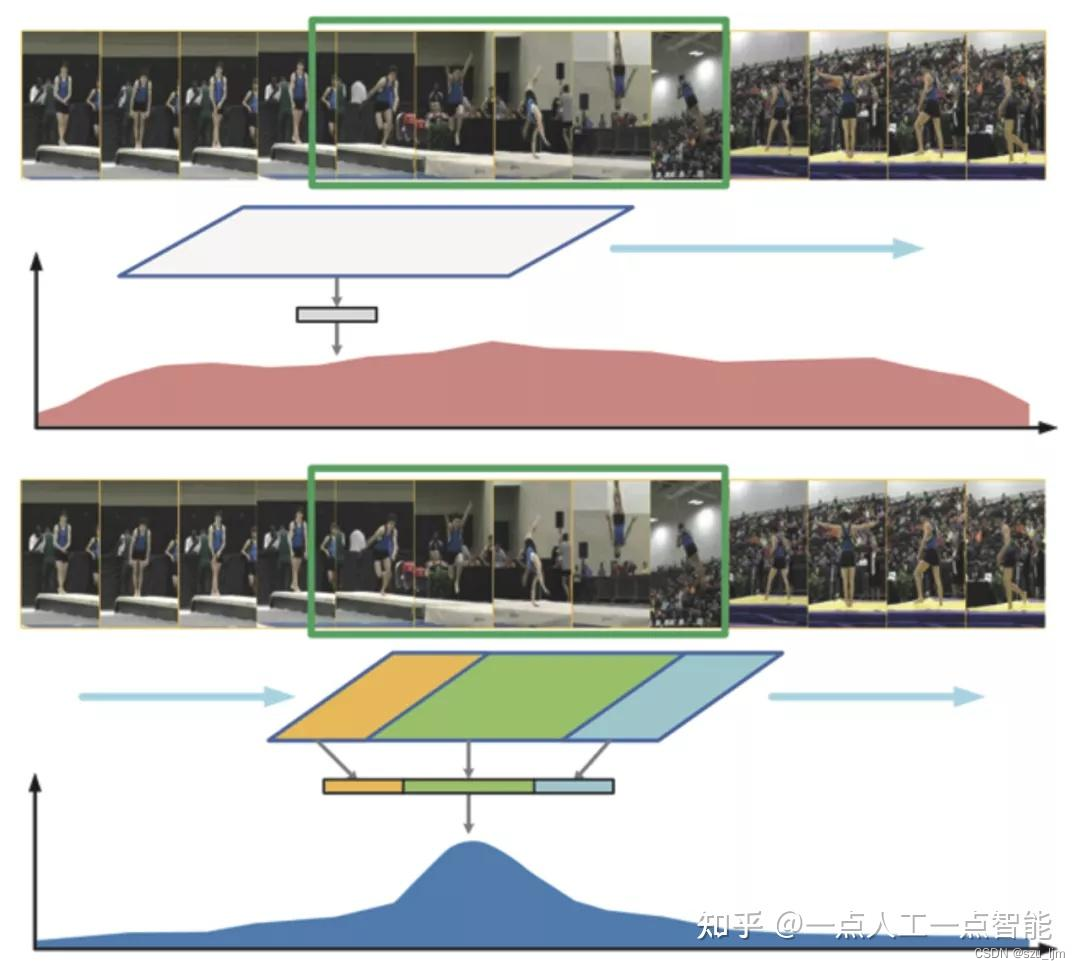
目前大多数最前沿的时序动作定位模型会单独处理每个动作proposals,而不会在学习过程中明确利用不同proposals之间的关系。大多数Two-Stage的TAL模型首先生成一组一维时空proposals,然后对每个proposals单独进行动作分类和动作边界回归,然而,在预测阶段单独处理每个proposals,势必会忽略提议之间的语义关系。
以下图来举例proposals之间的相互作用,一方面, p1、p2 和 p3 重叠描述了同一动作实例的不同部分(即开始时间段、主体和结束时间段)。传统方法仅利用 p1 的特征对其进行预测,研究者认为这不足以为动作检测提供完整的知识。如果我们额外考虑 p2 和 p3 的特征,就能获得更多围绕 p1 的上下文信息,这对 p1 的时间边界回归尤其有利。另一方面,p4 描述的是背景(即运动场),其内容也有助于识别 p1 的动作标签,因为运动场上发生的很可能是运动动作(如 “投掷铁饼”),而不是其他地方发生的动作(如 “接吻”)。换句话说,p1 的分类可以部分地受 p4 内容的指导,即使它们在时间上是脱节的。
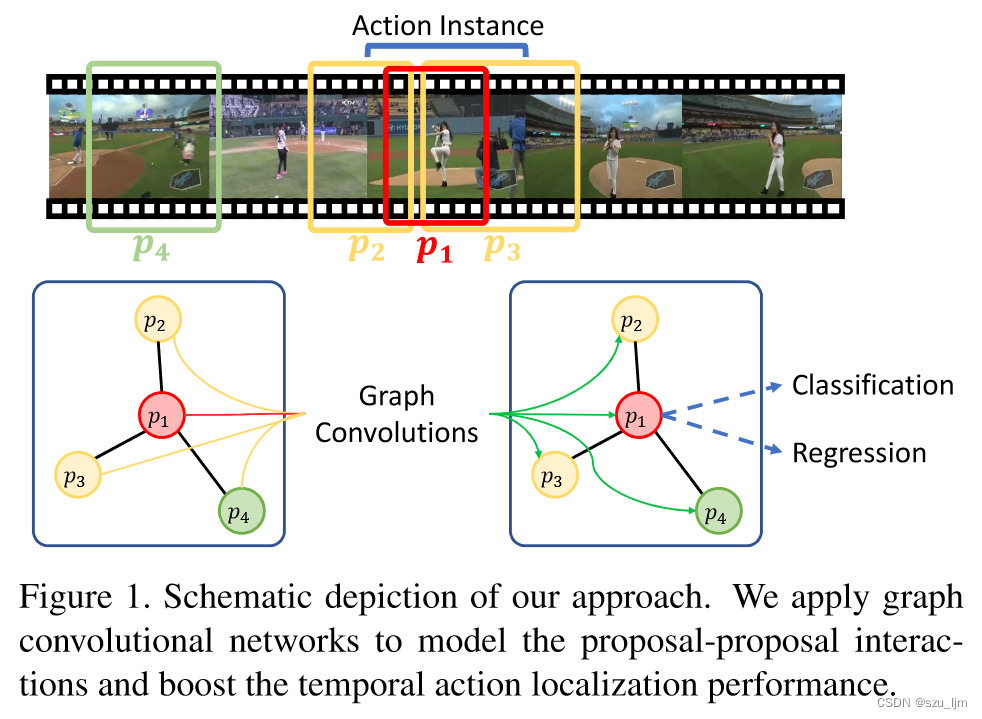
要建模proposal-proposal之间的相互关系,可以采用自注意力机制,不过,这种方法的计算成本很高,因为查询所有proposals对的复杂度是proposals数量的二次方。而应用 GCN 可以让我们只汇总每个proposal的本地邻域信息,从而有助于显著降低计算复杂度。
2、改进方法分析
PGCN模型主要分类两个支路,一条支路对原始视频提取相应的proposal,处理后获取特征送入GCN网络,输出动作的分类;另一条对原始视频提取相应的proposal,并前后延伸包含更多的上下文语境信息,处理后获取特征送入GCN网络,输出动作的边界信息
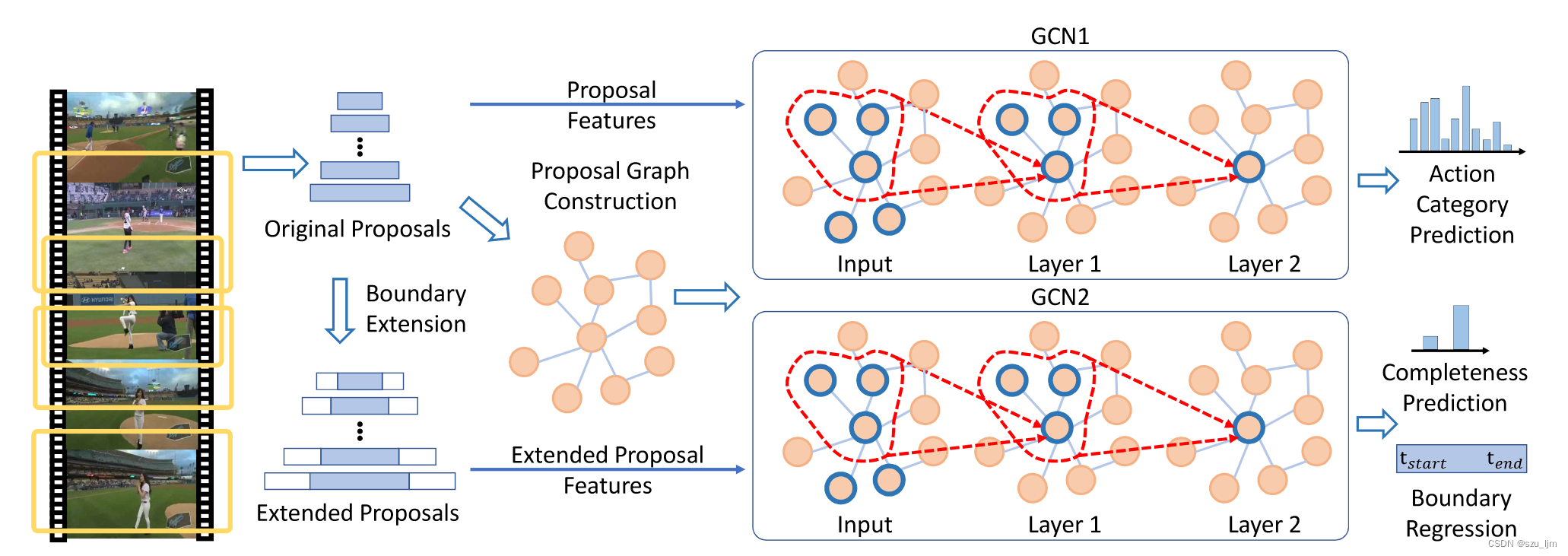
研究者使用 G ( p , ε ) G(p, \varepsilon) G(p,ε) 来表示proposal-proposal之间的关系(其中node为图示的四种proposal,edge分为contextual edge和surrounding edge两种来表示节点间的联系),通过设计新的构图方式并使用GCN将临近proposal的关系聚合到学习到更好的proposal-level特征。
对于第一种contextual edge来说,判断条件为 r ( p i , p j ) > θ c t x r(p_i, p_j) > θ_{ctx} r(pi,pj)>θctx,我们就在 p i p_i pi 和 p j p_j pj 之间建立一条边,其中 θ c t x θ_{ctx} θct
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1940
1940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











