






最近需要完成数据课程的作业,因此实践了一下如何安装并配置好spark
1、版本要求
由于我想要将hadoop和spark一起使用,因此必须确定好spark的版本
Spark和Hadoop版本对应关系如下:
| Spark版本 | Hadoop版本 |
| 2.4.x | 2.7.x |
| 3.0.x | 3.2.x |
可进入终端查看Hadoop版本
hadoop version我这里的版本是2.7.1,因此选择下载2.4版本的spark

Spark历史版本下载地址:Index of /dist/spark
找到适合自己的版本进行下载,这里我选择带有Hadoop scala的版本进行下载

2、Spark安装
Spark部署模式主要有四种:Local模式(单机模式)、Standalone模式(使用Spark自带的简单集群管理器)、YARN模式(使用YARN作为集群管理器)和Mesos模式(使用Mesos作为集群管理器)。这里介绍Local模式(单机模式)的 Spark安装
(1)文件解压到指定位置
sudo tar -zxf ~/下载/spark-2.4.7-bin-hadoop2.7.tgz -C /usr/local/
为了方便,还可以将文件夹重命名为spark,并更改文件所有者,下述的hadoop为用户名,更改为自己的用户名
sudo mv ./spark-2.4.7-bin-hadoop2.7/ ./spark
sudo chown -R hadoop:hadoop ./spark(2)修改配置文件spark-env.sh
将临时文件复制,并修改
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
vim ./conf/spark-env.sh在该文件首行添加
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)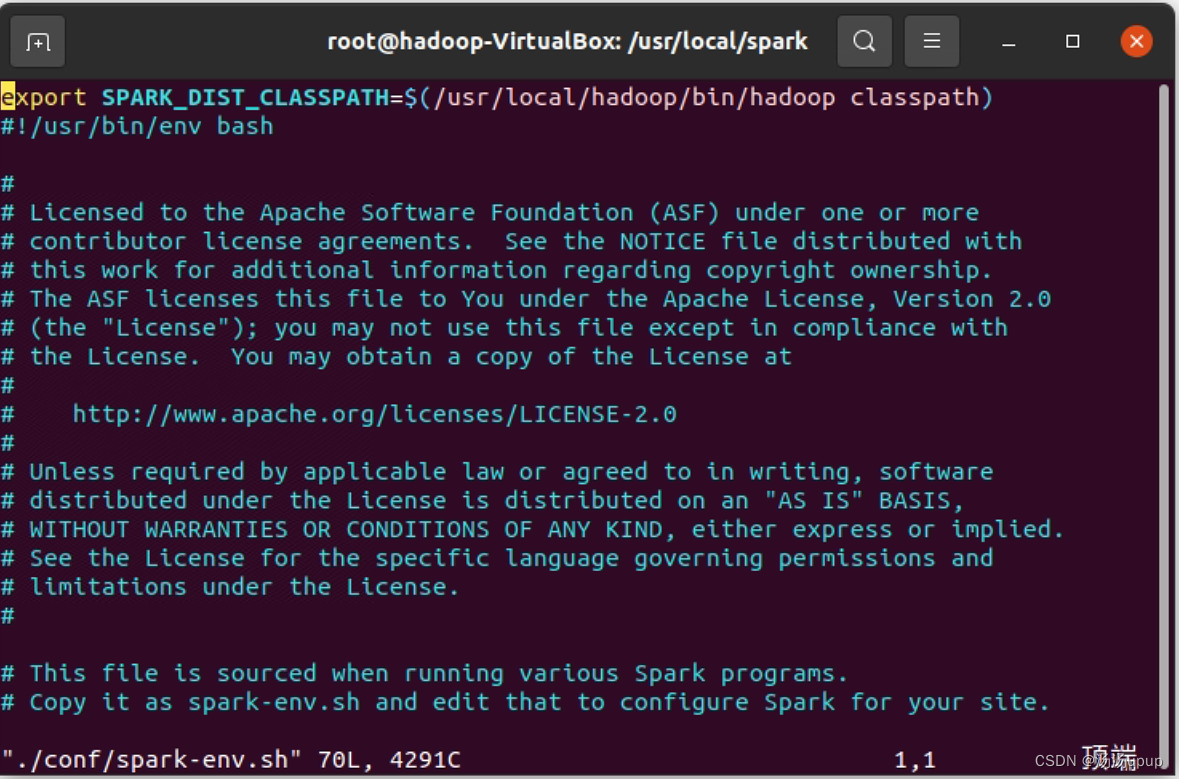
这样配置过后,spark能将数据存储到hadoop的HDFS中,同样也能从HDFS中读取数据,建立起Hadoop和Spark的连接。
(3)修改环境变量
vim ~/.bashrc在文件中添加spark的地址,以便能够快速访问
export SPARK_HOME=/usr/local/spark
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.7-src.zip:$PYTHONPATH
export PYSPARK_PYTHON=python3
export PATH=$HADOOP_HOME/bin:$SPARK_HOME/bin:$PATH不同的环境变量之间用":"隔开,田间PYTHONPATH主要是为了在python3中引入pyspark库

然后输入命令让环境变量生效
source ~/.bashrc3、Spark的验证
进入spark安装目录,并输入一段代码进行例子验证
bin/run-example SparkPi 2>&1 | grep "Pi is"能够计算出Pi的值,说明spark已经安装成功啦!

接下来进行pyspark的使用,进入spark的安装目录,并输入命令
cd /usr/local/spark
bin/pyspark然后你会看到一些error,出现报错
return types.CodeType(
TypeError: an integer is required (got type bytes)
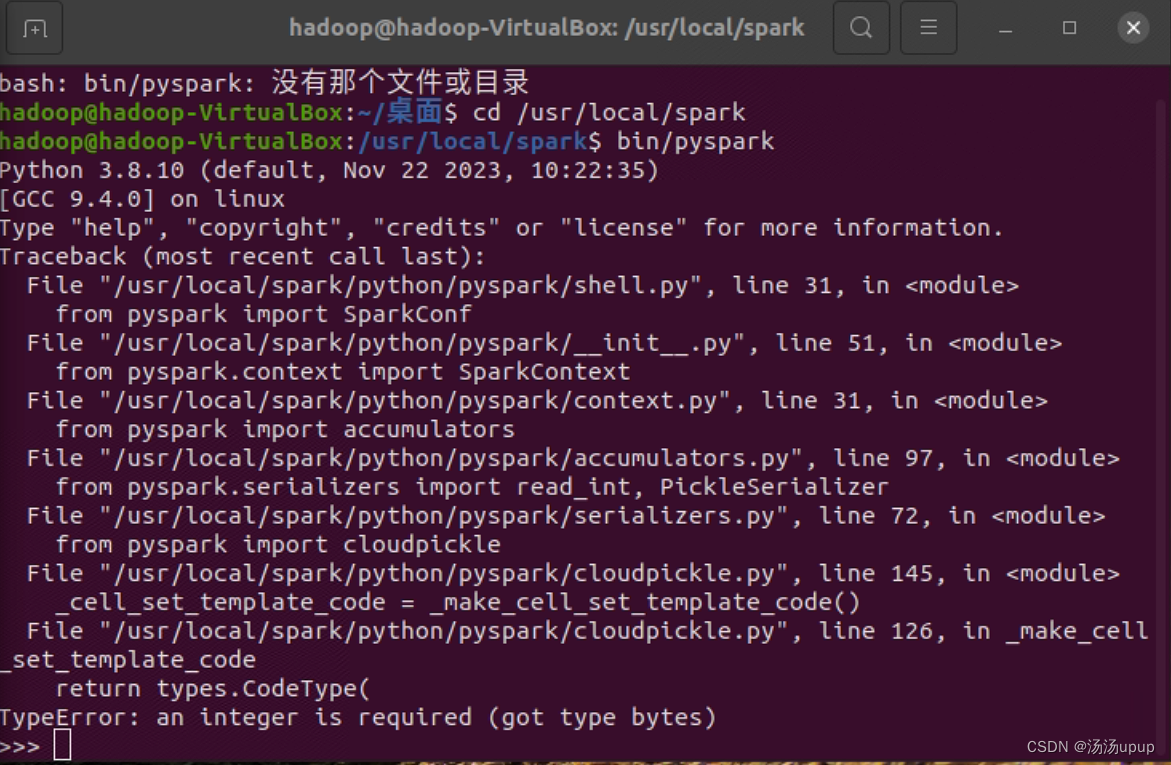
这是由于pyspark对于高版本的python不兼容,建议python版本在3.6,我这里激活了一下anaconda安装下的虚拟环境,虚拟环境中,python版本为3.6
然后运行成功啦!
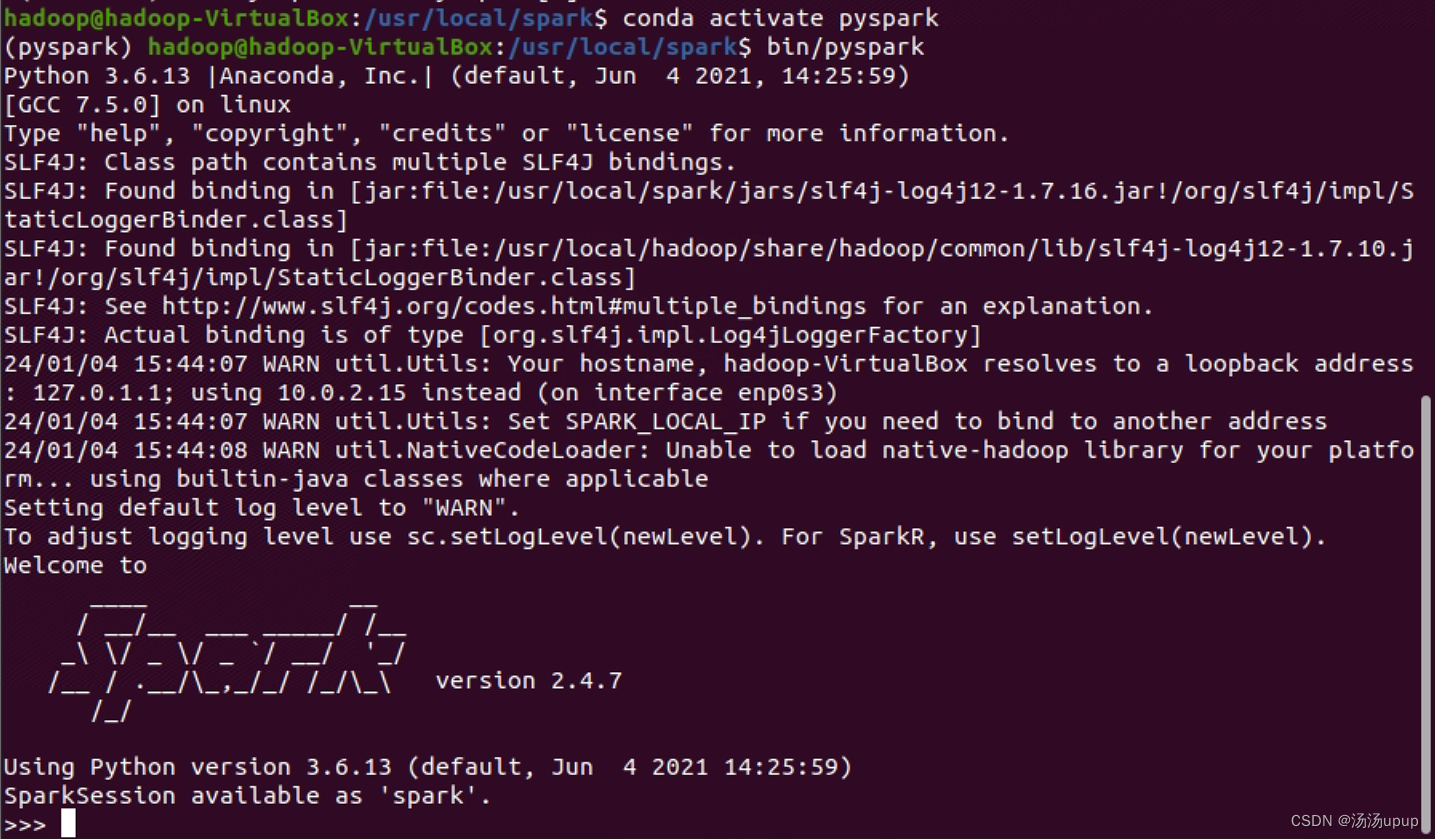
至此就可以使用pyspark进行编程,这对不熟悉scala语言的人来说十分友好~
都看到这里了,给个小心心呗♥~














 1891
1891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









