






一、任务区分
-
多分类分类任务:在多分类任务中,每个样本只能被分配到一个类别中。换句话说,每个样本只有一个正确的标签。例如,将图像分为不同的物体类别,如猫、狗、汽车等。
-
多标签分类任务:在多标签分类任务中,每个样本可以被分配到一个或多个类别中。换句话说,每个样本可以有多个正确的标签。例如,在图像标注任务中,一张图像可能同时包含猫和狗,因此它可以同时被分配到 "猫" 和 "狗" 这两个标签。
二、sklearn评估方式
1、多分类(multiclass)任务
多分类任务的标签有两种,一种是原始标签,例如[0,1,2],另一种是独热编码的形式,[[1,0,0],[0,1,0],[0,0,1]]
经过模型分类之后的结果一般是各类的预测分数
(1)准确率(Accuracy):是分类正确的样本数与总样本数之比,是最简单的评估方法,但在类别不平衡的情况下可能会失效。
(2)混淆矩阵(Confusion Matrix):是一个 N×N 的矩阵(N 为类别数量),将真实类别与预测类别的对应关系表示出来。基于混淆矩阵可以计算精确率、召回率、F1 分数等指标。
(3)精确率(Precision) 和 召回率(Recall):精确率表示被分类器正确分类的正样本数量与分类器预测为正样本的样本数量之比;召回率表示被分类器正确分类的正样本数量与数据集中所有正样本数量之比。
(4)F1 分数:精确率和召回率的调和平均数,综合考虑了分类器的准确性和完整性。
(5)ROC 曲线和AUC(Area Under the Curve):对于二分类任务,可以绘制ROC曲线,以真正例率(True Positive Rate)作为纵轴,假正例率(False Positive Rate)作为横轴。AUC表示ROC曲线下的面积,是一个评估分类器性能的常用指标。对于多分类任务,通常使用微平均(micro-average)或宏平均(macro-average)来计算AUC。
- 引入模块,并自己定义一下模型输出
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report, precision_score, recall_score, f1_score, roc_auc_score, roc_curve
import numpy as np
import matplotlib.pyplot as plt
import torch
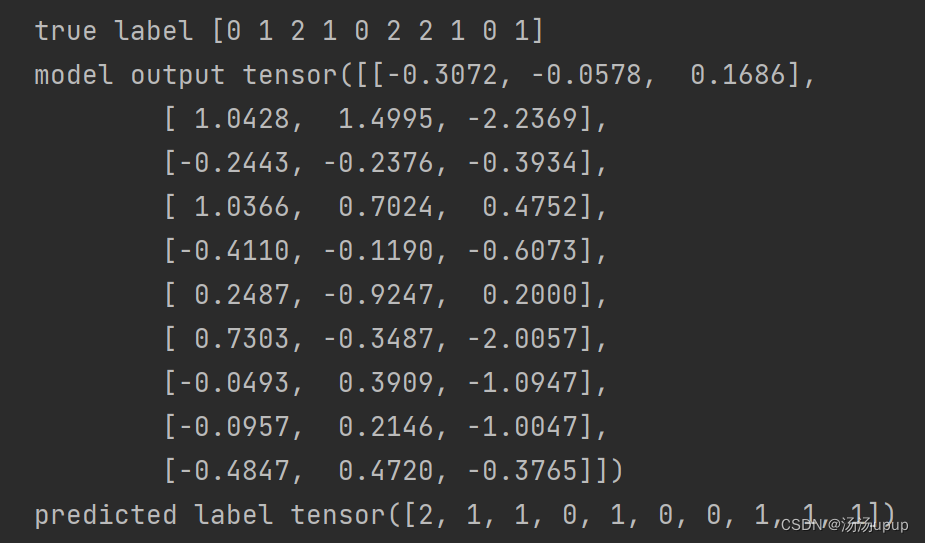
# 示例真实标签和预测结果
true_labels = np.array([0, 1, 2, 1, 0, 2, 2, 1, 0, 1])
print("true label",true_labels)
# 生成随机数据作为概率值,实际应用中需要替换为模型的预测概率值
model_output = torch.randn(len(true_labels), 3)
print("model output",model_output)
# 获得最大类别的index
_, predicted_labels = torch.max(model_output, 1)
print("predicted label",predicted_labels)示例数据如下:
- 进行模型评估
注意,计算roc_auc时需要将输出概率归一化,否则会报错
ValueError: Target scores need to be probabilities for multiclass roc_auc, i.e. they should sum up to 1.0 over classes
准确率等的计算用的是模型输出后最大类别的index,而计算roc_auc直接用模型输出的概率,但需要归一化。
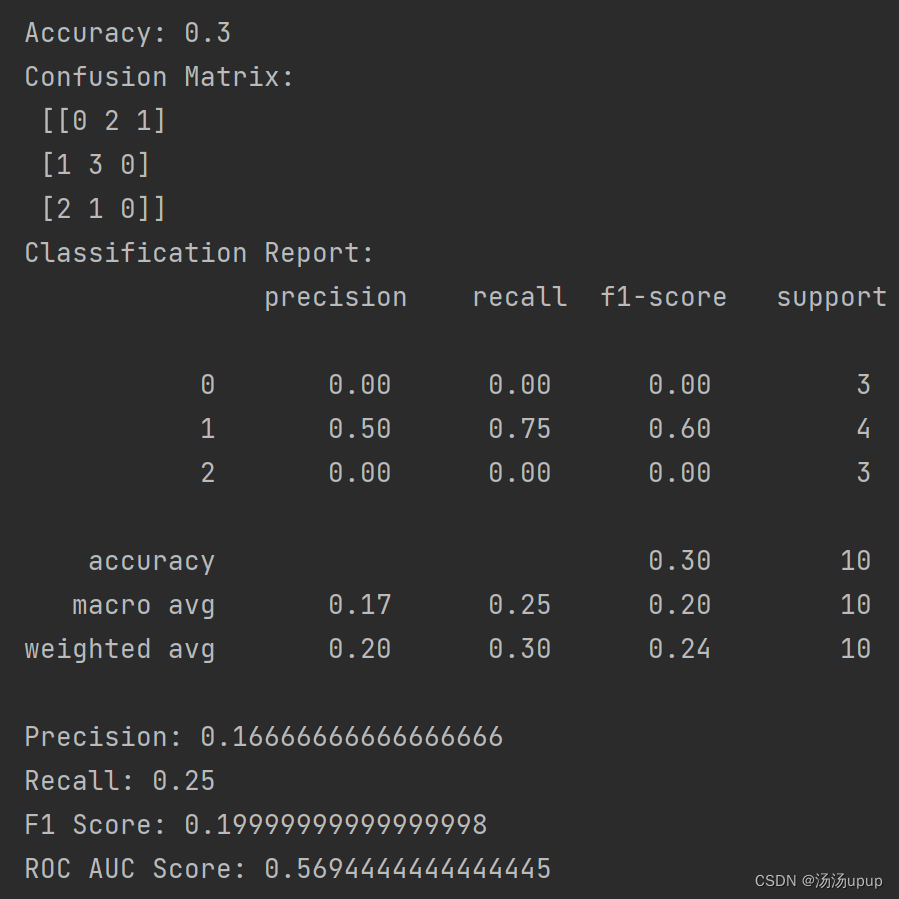
# 准确率
accuracy = accuracy_score(true_labels, predicted_labels)
print("Accuracy:", accuracy)
# 混淆矩阵
conf_matrix = confusion_matrix(true_labels, predicted_labels)
print("Confusion Matrix:\n", conf_matrix)
# 分类报告
class_report = classification_report(true_labels, predicted_labels)
print("Classification Report:\n", class_report)
# 精确率
precision = precision_score(true_labels, predicted_labels, average='macro')
print("Precision:", precision)
# 召回率
recall = recall_score(true_labels, predicted_labels, average='macro')
print("Recall:", recall)
# F1 分数
f1 = f1_score(true_labels, predicted_labels, average='macro')
print("F1 Score:", f1)
# ROC AUC
# 计算ROC需要将模型输出概率归一化
prob_new = torch.nn.functional.softmax(model_output, dim=1)
print(prob_new)
roc_auc = roc_auc_score(true_labels, prob_new, average='macro', multi_class='ovo')
print("ROC AUC Score:", roc_auc)
结果:
- 独热编码
但如果是对原始的标签数据进行了独热编码,那么在进行准确率等的计算的时候,需要将输出也转化为与独热编码类似的形式,然后再使用sklearn的函数进行计算
from sklearn.preprocessing import label_binarize
# 进行独热编码
true_one_hot = label_binarize(true_labels, classes=np.arange(3))
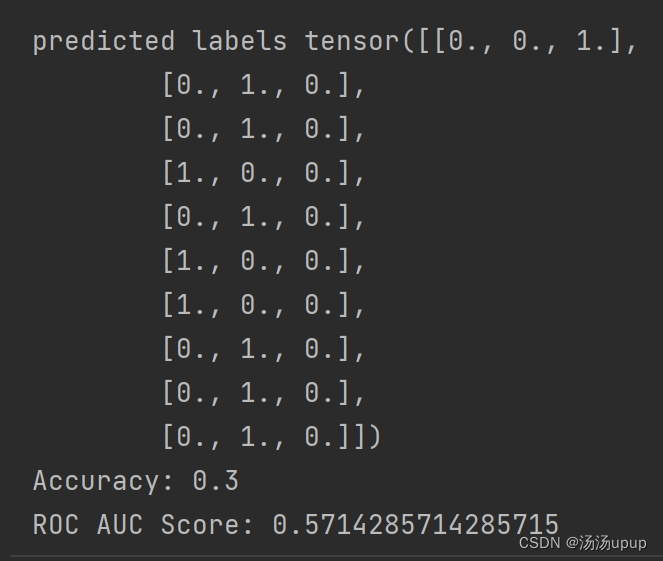
# 获取每行最大值的索引
max_indices = torch.argmax(model_output, dim=1)
# 创建一个与模型输出相同形状的零张量
predicted_labels = torch.zeros_like(model_output)
# 将每行最大值的位置设为1
predicted_labels[torch.arange(len(max_indices)), max_indices] = 1
print("predicted labels",predicted_labels)
accuracy = accuracy_score(true_one_hot, predicted_labels)
print("Accuracy:", accuracy)
roc_auc = roc_auc_score(true_one_hot, model_output, average='macro')
print("ROC AUC Score:", roc_auc)结果如下:
总之,无论是采用原始标签的形式,还是独热编码的形式,在计算accuracy,recall,precision,F1-score的时候,都需要将模型输出转化为0,1且与真实标签维度一致的格式,而在计算roc的时候,若是独热编码的真实标签,则可以直接用模型输出,但如果不是,就需要归一化概率。
2、多标签(multilabel)分类任务
对于多标签分类,初始的真实标签要用到独热编码
针对模型输出的概率分数,需要设定一个阈值,大于阈值的标记为1,低于阈值的标记为0,如下代码所示:
import torch
# 示例模型输出
model_output = torch.tensor([[0.8, 0.3, 0.9],
[0.2, 0.7, 0.4],
[0.9, 0.1, 0.3]])
# 设置阈值
threshold = 0.5
# 将概率分数转换为0-1结果
predicted_labels = (model_output > threshold).float()
print(predicted_labels)
然后直接使用sklearn的函数进行评估
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, hamming_loss, jaccard_score, coverage_error, average_precision_score, roc_auc_score
import numpy as np
# 示例标签和预测结果
true_labels = np.array([[1, 0, 1], [0, 1, 1], [1, 1, 0]])
predicted_labels = np.array([[1, 0, 1], [0, 1, 0], [1, 0, 0]])
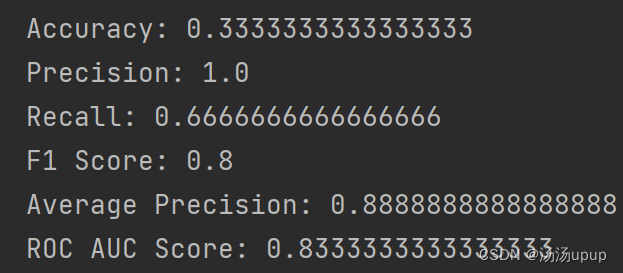
# 准确率
accuracy = accuracy_score(true_labels, predicted_labels)
print("Accuracy:", accuracy)
# 精确率
precision = precision_score(true_labels, predicted_labels, average='micro')
print("Precision:", precision)
# 召回率
recall = recall_score(true_labels, predicted_labels, average='micro')
print("Recall:", recall)
# F1 分数
f1 = f1_score(true_labels, predicted_labels, average='micro')
print("F1 Score:", f1)
# 平均准确率
average_precision = average_precision_score(true_labels, predicted_labels, average='micro')
print("Average Precision:", average_precision)
# ROC AUC
roc_auc = roc_auc_score(true_labels, predicted_labels, average='micro')
print("ROC AUC Score:", roc_auc)
得到的结果如下:
详细对于多标签分类的指标解释可以参考下面的文章:
sklearn中多标签分类场景下的常见的模型评估指标_51CTO博客_sklearn模型评估![]() https://blog.51cto.com/liguodong/4290183总的来说,要根据自己的任务和目标来制定合适的评估指标,因为评估指标是实验结果的体现。
https://blog.51cto.com/liguodong/4290183总的来说,要根据自己的任务和目标来制定合适的评估指标,因为评估指标是实验结果的体现。
都看到了这里了,给个小心心♥呗~















 1619
1619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









