







1.顺序表和链表的区别

顺序表和链表的区别(这里的链表主要指的是带头双向循环链表)
| 不同点 | 顺序表 | 链表 |
|---|---|---|
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但物理上不一定连续 |
| 随机访问 | 支持O(1) | 不支持 O(N) |
| 任意位置插入或删除元素 | 可能需要搬移元素,效率低 | 只需修改指针指向 |
| 插入 | 动态顺序表,空间不够需要扩容 | 没有容量的概念 |
| 应用场景 | 元素高效存储+频繁访问 | 任意位置插入和删除频繁 |
| 缓存利用率 | 高 | 低 |
对于最后一点说明以下:
实现分别对顺序表和链表上的每个数据+1,要先读取数据,然后运算,再写回主存
CPU执行指令运算要访问数据,会先去缓存中找有没有这个数据:
如果有,说明缓存命中了
如果没有,说明缓存未命中,就从主存中读取一段连续内存空间的数据到缓存,继续找
顺序表物理地址是连续的,增加了命中率,就不用频繁的从主存中读数据到缓存中,提高了缓存利用率
这就是物理地址连续的优势,所以在现实生活中,很多地方还是推荐用顺序表的
缓存基本上来说就是把后面的数据加载到离自己近的地方,对CPU来说,它是不会一个字节一个字节的加载的,因为这样非常没有效率,一般都是要一块一块加载的,顺序表物理空间连续,加载时会加载到一块,所有它的缓存命中率高,而链表在存储空间上,逻辑上连续,但物理上不一定连续,加载时不一定会加载到一块,所有它的缓存命中率低,也就是利用率低。

顺序表优点:下标随机访问、cpu高速缓存命中率高
顺序表缺点:头部或者中间插入删除效率低、扩容(有一定的性能消耗、可能存在一定程度空间浪费)
链表优点:在任意位置插入删除O(1),按需申请释放
链表缺点:不支持下标随机访问
所以虽然链表很强大,但它并不能完全代替顺序表,可以说它们二者相辅相成。
2.与程序员相关的CPU缓存知识
下面介绍一些与程序员相关的CPU缓存知识
因为无论你写什么样的代码都会交给CPU来执行,所以如果你想写出性能比较高的代码,这里提到的技术还是值得认真学习的。
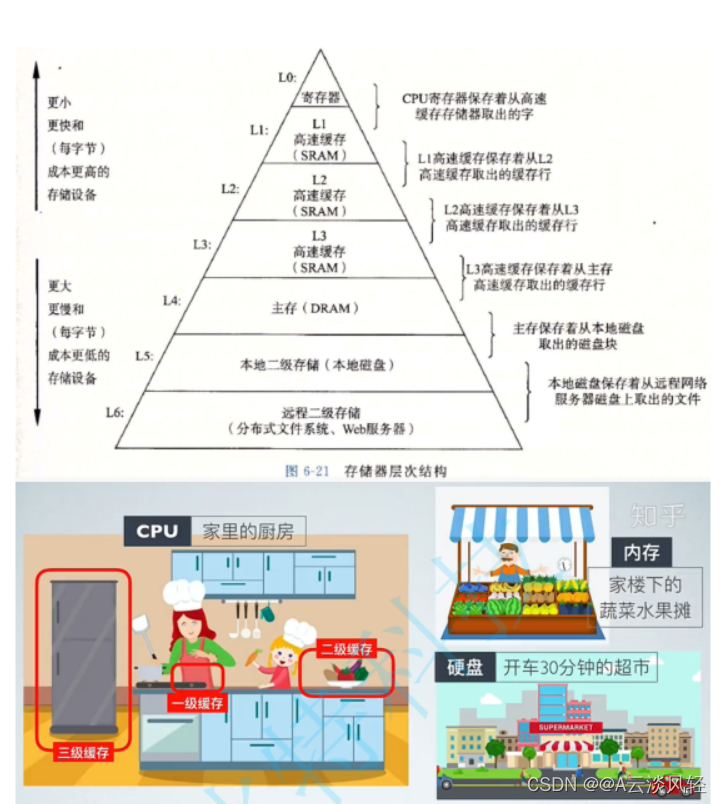
如图:做菜时先会到缓存中去取食材,缓存中没有食材,再去内存那里买……
基础知识
首先,我们都知道现在的CPU多核技术,都会有几级缓存,老的CPU会有两级缓存(L1和L2),新的CPU会有三级缓存(L1,L2,L3),如下图所示:

其中:
- L1缓存分成两种,一种是指令缓存,一种是数据缓存。L2缓存和L3缓存不分指令和数据。
- L1和L2在每一个CPU核中,L3则所有CPU核 核心共享的缓存
- L1、L2、L3离CPU离得越近,大小就越小,速度也就越快,离得越远,大小较大,速度也就越慢。
再往后面就是内存,内存的后面就是硬盘。我们来看一些它们的速度:
L1 的存取速度:4 个CPU时钟周期
L2 的存取速度: 11 个CPU时钟周期
L3 的存取速度:39 个CPU时钟周期
RAM内存的存取速度:107 个CPU时钟周期
我们可以看到,L1的速度是RAM的27倍,但是L1/L2的大小基本上也就是KB级别的,L3会是MB级别的。例如:Intel Core i7-8700K ,是一个6核的CPU,每核上的L1是64KB(数据和指令各32KB),L2 是 256K,L3有2MB。
我们数据就从内存向上,先到L3,再到L2,再到L1,最后到寄存器进行CPU计算。为什么会设计成三层?这里有几个方面的考虑:
一个方面是物理速度,如果要更大的容量就需要更多的晶体管,除了芯片的体积会变大,更重要的是大量的晶体管会导致速度下降,因为访问速度和要访问的晶体管所在位置成反比,也就是当信号路径变长,通信速度会变慢。这是物理问题。
另外一个问题是,多核技术中,数据的状态需要在多个CPU中进行同步,并且,我们可以看到,cache和RAM的速度差距太大,CPU运算速度快,读取内存,内存速度跟不上,CPU一般就不会直接访问内存,而是把要访问的数据先加载到缓存体系,如果是小于8byte的数据,直接到寄存器,如果是大的数据会到三级缓存,CPU直接跟缓存交互。所以,多级不同尺寸的缓存有利于提高整体的性能。
这个世界永远是平衡的,一面变得有多光鲜,另一面也会变得有多黑暗。建立这么多级的缓存,一定就会引入其它的问题,这里有两个比较重要的问题,
一个是比较简单的缓存的命中率的问题。
另一个是比较复杂的缓存更新的一致性问题。
尤其是第二个问题,在多核技术下,这就很像分布式的系统了,要对多个地方进行更新。
缓存的命中
缓存基本上来说就是把后面的数据加载到离自己近的地方,对CPU来说,它是不会一个字节一个字节的加载的,因为这样非常没有效率,一般都是要一块一块加载的,对于这样一块一块的数据单位,术语叫“Cache Line",一般来说,一个主流的CPU的Cache Line 是 64 Bytes(也有的CPU用32Bytes和128Bytes),64Bytes也就是16个32位的整型,这就是CPU从内存中捞数据上来的最小数据单位。
比如:Cache Line是最小单位(64Bytes),所以先把Cache分布多个Cache Line,比如:L1有32KB,那么,32KB/64B = 512 个 Cache Line。
一方面,缓存需要把内存里的数据放到放进来,英文叫 CPU Associativity。Cache的数据放置的策略决定了内存中的数据块会拷贝到CPU Cache中的哪个位置上,因为Cache的大小远远小于内存,所以,需要有一种地址关联的算法,能够让内存中的数据可以被映射到Cache中来。这个有点像内存地址从逻辑地址向物理地址映射的方法,但不完全一样。
参考文章:与程序员相关的CPU缓存知识
如果对您有所帮助,期待您的点赞和关注呀😍!
如果有不明白的地方可以私信我,很乐意为您解答😉👍。















 143
143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









