






1. 论文简介
论文名:Feature Pyramid Networks for Object Detection
论文地址 :FPN
论文作者:Tsung-Yi Lin, Piotr Dollar, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie
论文时间:2016年CVPR
说明:FPN可以实现端到端训练;使得模型精度更高;且不增加推理时间。使用了FPN结构的Faster R-CNN在COCO数据集上,mAP提升了2.3个点;在Pascal VOC数据集上,mAP提升了3.8个点。
2.特征图不同的使用方式
卷积网络中,随着网络深度的增加,特征图的尺寸越来越小,语义信息也越来越抽象。浅层特征图的语义信息较少,目标位置相对比较准确,深层特征图的语义信息比较丰富,目标位置则比较粗略,导致小物体容易检测不到。FPN的功能可以说是融合了浅层到深层的特征图 ,从而充分利用各个层次的特征。
(1)特征化图像金字塔 Featurized image pyramids
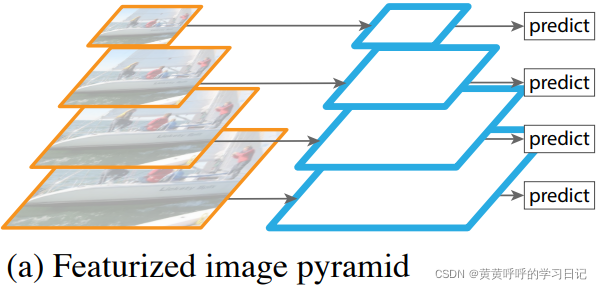
可以看到,这种方式先是对原始图像进行缩放,获得不同尺寸的图像,然后基于每种尺寸的图像生成不同尺寸的特征图,最后基于多尺寸特征图进行预测。
这种方法需要针对每种尺寸的图片生成特征图,会消耗较多的计算和内存资源,端到端训练几乎不可能实现,所以基本上就用在推理阶段且推理速度较慢。

(2)单一特征图 Single feature map

大家比较熟悉的方式,也就是使用最上层的特征图来进行预测。这种方法难以有效利用浅层特征,小尺寸目标的检测比较困难。
(3)特征图金字塔
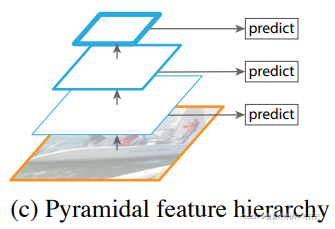
我们知道,卷积神经网络天然就会生成不同层次不同分辨率大小的特征图,那就可以直接将这些特征图当作是金字塔状的特征层结构来使用,与第一种方式类似。不过这种方法是在每种特征图上进行预测,因此对于特征图的利用仍然比较单一,难以融合不同层次特征图中的语义信息。
典型的如SSD。
(4)特征金字塔网络 Feature Pyramid Network

特征图金字塔网络,也就是作者在论文中提出的结构。
原文中有一句话总结的特别好:

也就是:自顶向下地处理特征图并通过横向连接的方式融合底层的具有较少语义信息的特征图和高层的具有丰富语义信息的特征图,同时没有牺牲表达能力、速度和资源的消耗。
3.FPN构建过程
3.1 Bottom-up pathway:自底向上构建不同尺寸的特征图。
也就是通过卷积神经网络的前向传播来得到不同尺寸的特征图从而构建特征图金字塔架构,这些特征图之间的大小是2倍关系。
作者在论文中提出,通常情况下,我们把那些产生同样大小的特征图的层归属到一个stage,因此,每个stage的最后一层输出的特征图才会被用作构建特征图金字塔。

例如,对于ResNet网络来说,会采用每个stage的最后一个residual block输出的特征图,也就是conv2、conv3、conv4、conv5最后一个residual block输出的特征图,并且将它们定义为{C2, C3, C4, C5},它们相对于原始图片的stride是{4,8,16,32}。需要注意的一点是,考虑到内存原因,conv1的输出特征图并没有被使用。
后面会再画一个图可以看的更清楚一些。
3.2 Top-down pathway and lateral connections:自顶向下处理特征图和横向连接。
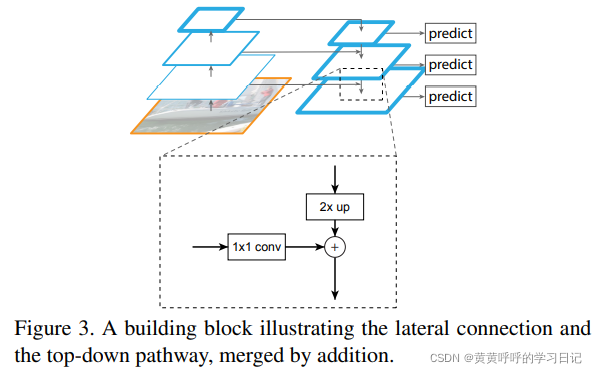
如上图所示,在得到{C2, C3, C4, C5}这些特征图之后,首先将C5进行1x1卷积将其channel的值变为256,然后进行2倍上采样(论文中提到为了简单起见采用最近邻插值的方法),此时得到的特征图的宽和高与C4是一样的,但是注意,C4的channel值和上采样得到的特征图的channel值是不一样大的,所以C4也会先进行1x1卷积将channel变为256,然后和该特征图逐元素相加。依次类推。所以特征得以不断融合。
总结来说就是,自顶向下,C5-C4-C3-C2依次进行横向的1x1卷积,再与上一层上采样的结果进行矩阵加法操作。论文中提到,C5-C4-C3-C2横向的1x1卷积不改变其宽高值,主要是将特征图的深度变为256,而且1x1的卷积不需要添加激活函数。
接下来,经过相加之后的多层特征图再分别经过3x3卷积得到最终的特征金字塔,分别为{P2, P3, P4, P5},最后分别基于{P2, P3, P4, P5}进行预测。
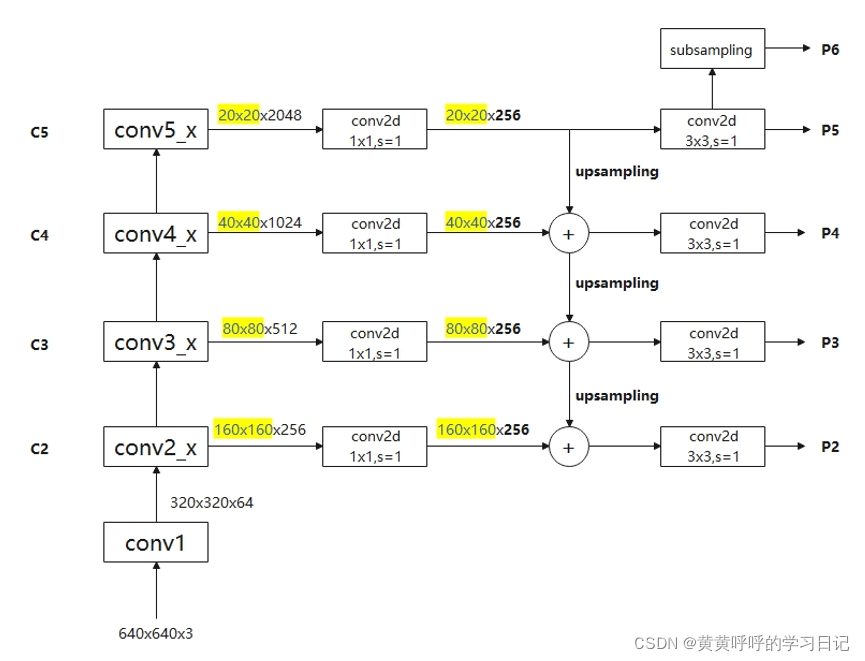
4. 一个实例:ResNet50+FPN
图中的P6后文会解释,此处可以忽略。
5. 引入FPN的RPN
一个小回忆:原先RPN部分,在经过backbone得到特征图之后,会接一个3x3的卷积,再并联两个1x1的卷积完成是否包含目标的binary分类和bounding box的回归,我们可以称之为network head(3x3 conv + two sibling 1x1 convs)。
也就是说,原先是在backbone最后输出的特征图上进行的。
那有了FPN结构之后,RPN会发生什么变化呢?其实不难理解。因为FPN会产生多层特征图:{P2, P3, P4, P5},那么在每一层后均接上刚刚提到的network head就好了。
实际上,为了获得更大尺寸的Anchor,作者对P5进一步进行了简单的2倍下采样,得到P6,不过P6只在训练RPN的时候用到,后续训练Fast R-CNN的时候并没有被使用。

关于anchor box,作者指出,对于不同层的特征图来说,没有必要采用不同尺寸的anchor box,而是每一层只采用一种尺寸的anchor box即可。于是,{P2, P3, P4, P5, P6}这些层上的anchor box的面积分别为{ ,
,
,
,
},而对于每种尺寸的anchor来说,会有三种高宽比:{1:2, 1:1, 2:1} ,所以!对于这样一种特征金字塔结构来说,一共会有15个不同样式的anchor box。
6. 引入FPN的Fast R-CNN
一个小回忆:在RPN生成region proposal之后,会将region proposal映射到特征图上,然后再进行ROI Pooling。
引入FPN之后,Fast R-CNN会发生什么变化呢?其实也不难理解。我们只需要将将这些region proposal映射到对应层的特征图上就好了。所以我们就可以把FPN看成是image pyramid。
对于在原图上宽为w高为h的region proposal来说,它的映射公式如下:
![]()
其中,
224:经典的ImageNet数据集预训练时的大小
:一个
的region proposal映射后所在的层,Resnet-based Faster R-CNN中,
=4
w和h:region proposal在原图上的宽和高
例如,对于一个112x112的region proposal来说,它应该被映射到P3进行后续的预测。
7. 补充
虽然FPN会生成多个特征层,但作者指出,不同的特征层会公用RPN和Fast R-CNN的head网络参数。也就是说,P2-P6的RPN权重共享,P2-P5的Fast R-CNN权重共享。


pytorch官方的映射代码:torchvision-ops-poolers.py














 935
935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









