







昨天尝试到了自动化的甜么今天就要让它更甜一点吧。
自动化测试不能说最重要的东西吧,但是最起码你定位不到唯一的元素如何去进行下一步呢?所以还是一小步一小步的来吧。
我自己将他划分为四类:首选类、必会类、掌握类、无所谓类(也不是正的无所谓哈,愿意掌握还是可以的)。那么下边一步一步开始吧。
1、首选类
- ID
- NAME
2、必会类
- Xpath
3、掌握类
- Link_Text
- Partial_Link_Text
4、无所谓类
- Tag_Name
- Class_Name
- CSS
前边两个类型作为测试是必须要会的,ID、Name其实就是前端工程师或者是开发人员在编写代码时赋予的标签属性。可以唯一也可以不唯一,当然这个是他们需要去考虑的问题而我们只需要考虑定位是唯一的可以了。
还是以百度页面为例.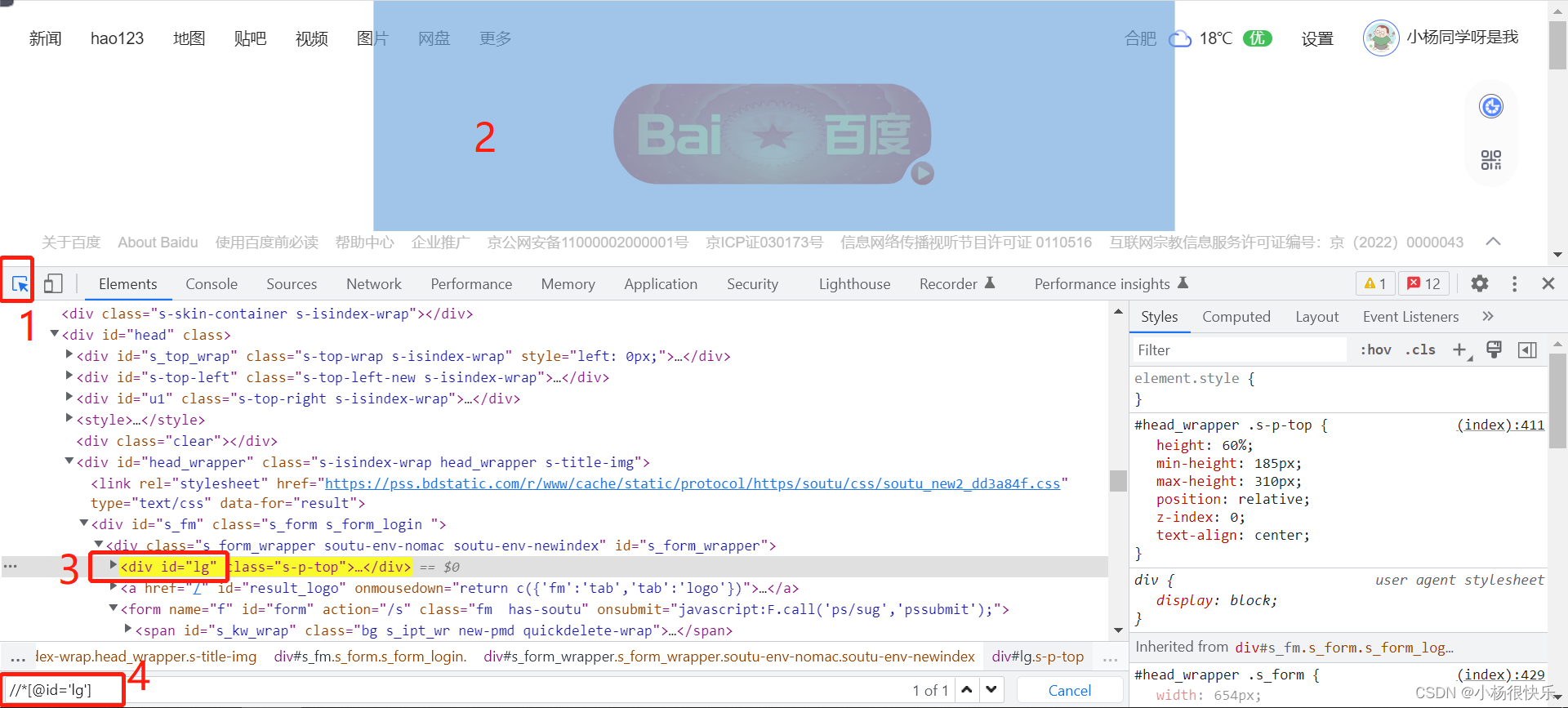
F12可以进到调试界面,点击需要1的位置就可以查看具体页面对应的是那块代码。 (2对应3)那么我们可以看他一个div标签中有一个id = "lg",那么这个就表示这个div有一个id属性,这个id属性的值是lg,4是Xpath表达式。下边用ID去定位一下这个元素。
# @Time : 2022/10/28 0028 17:45
# @Author : jinting
# 导入必要类库
from selenium import webdriver
from selenium.webdriver.common.by import By
# 加载浏览器驱动,获取测试页面信息
wb = webdriver.Chrome()
testUrl = wb.get('https://www.baidu.com/')
wb.maximize_window()
if wb.find_element(By.ID, 'lg'): # 因为是个图片不方便所以用个输出看是否成功
print("OK")
else:
print("没有")Name的是一样的只不过是换成如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
# 加载浏览器驱动,获取测试页面信息
wb = webdriver.Chrome()
testUrl = wb.get('https://www.baidu.com/')
wb.maximize_window()
if wb.find_element(By.NAME, 'lg'): # 方法换成name,值换成name的值即可
print("OK")
else:
print("没有")个人觉得最主要的还是Xpath,Xpath在手,啥都可有。Xpath可以通过浏览器右击copy Xpath去复制,但是个人建议还是要自己去写,毕竟浏览器复制出来的可能会很长但是自己写出来的可能还简单一些。
复制步骤:
F12调试模式,左上角小箭头选中需要定位的元素,右击Copy-Copy-Xpath
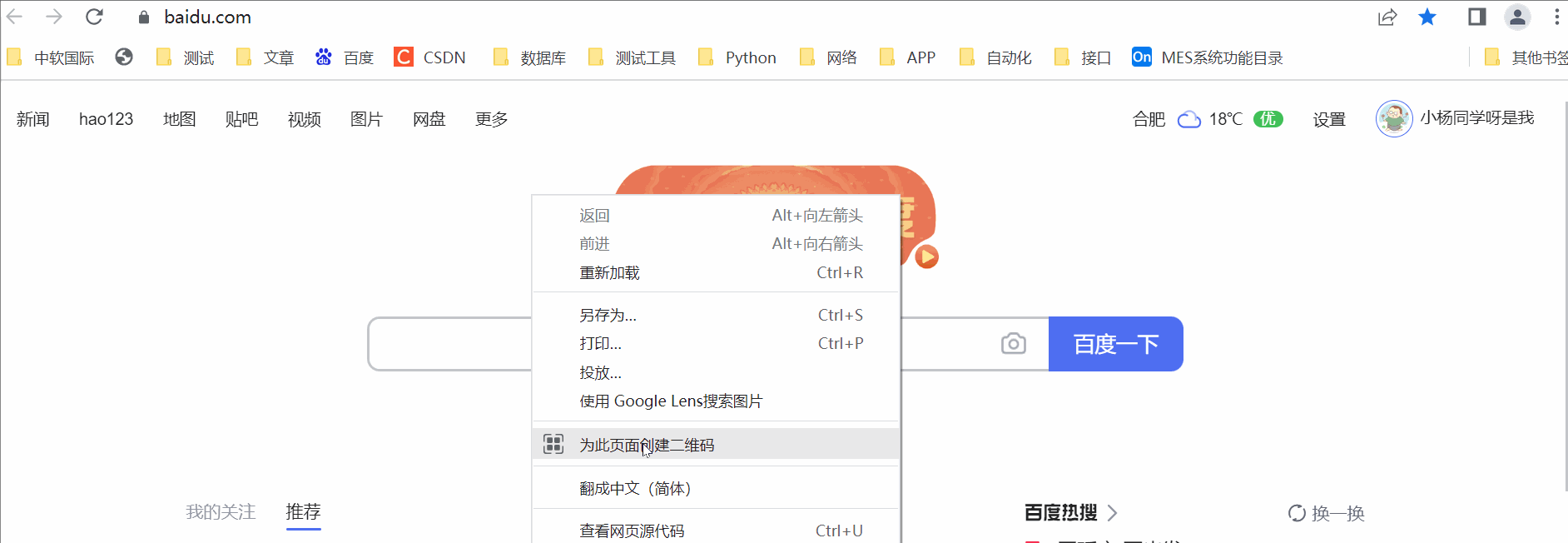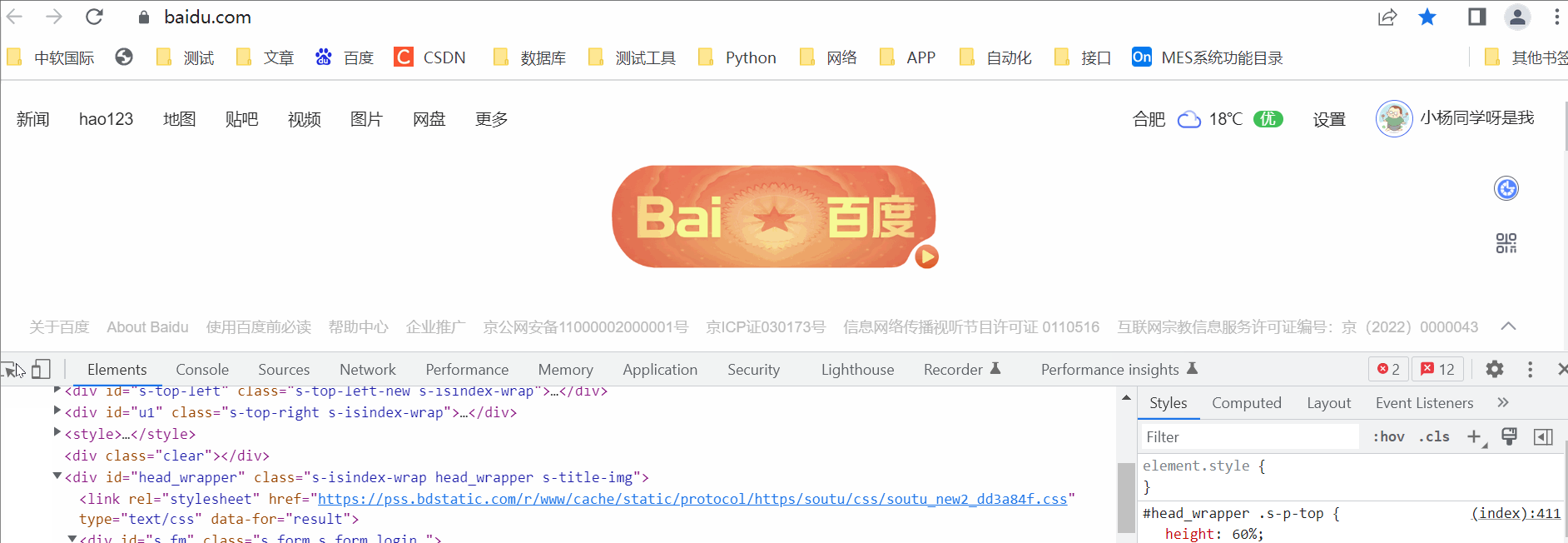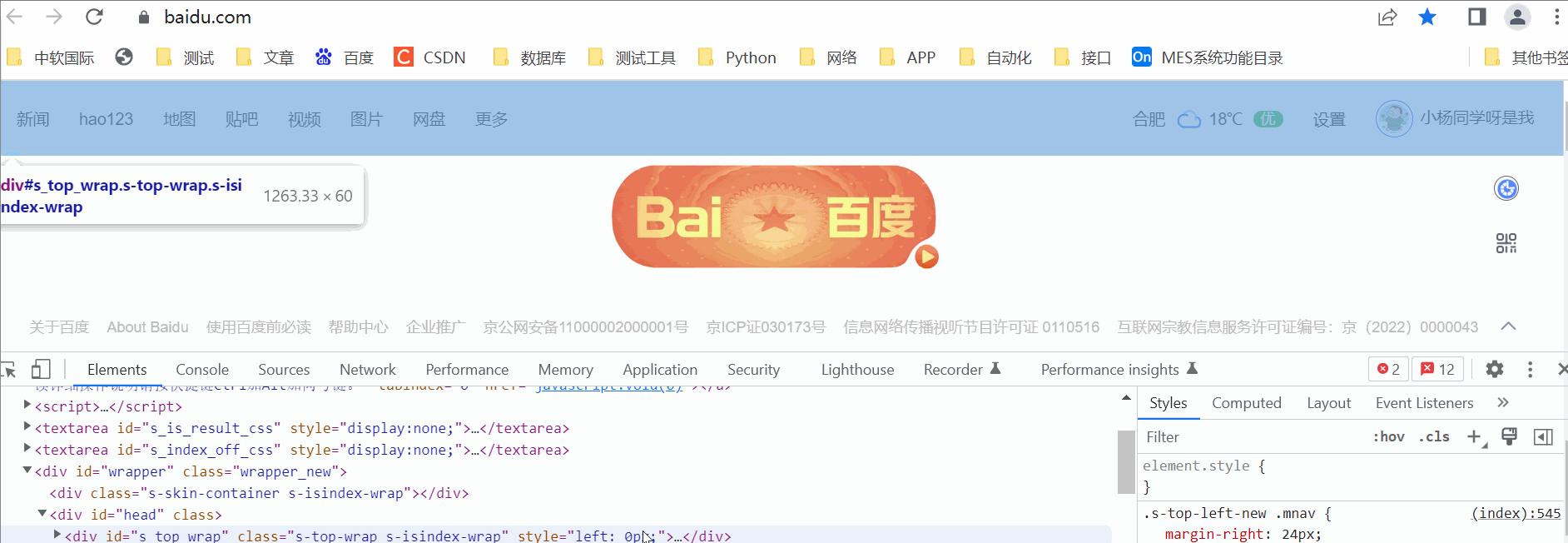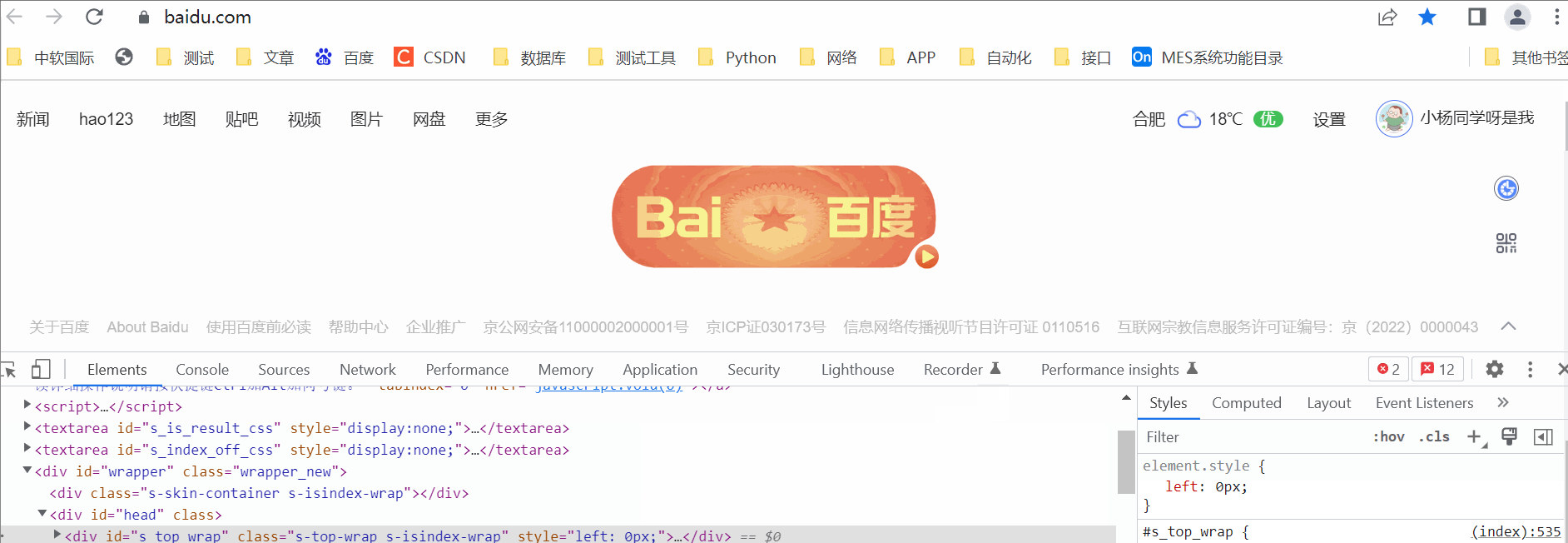
途中大家可以看到复制的时候还有一个full xpath,它是绝对路径的复制,从html标签开始,但是我们日常使用中其实是越简单越好的。这个是复制的方法,后边我们讲下手动写。
手动写其实也是从标签的属性已经标签的层级关系进行思考出发的,我这里就简单的讲一下,可以去搜Xpath定位其他人那里会更详细一些。我们想要写的东西少一点肯定是从相对路径出发的,xpath以//开头。例如上边的ID:
# 导入必要类库
from selenium import webdriver
from selenium.webdriver.common.by import By
# 加载浏览器驱动,获取测试页面信息
wb = webdriver.Chrome()
testUrl = wb.get('https://www.baidu.com/')
wb.maximize_window()
if wb.find_element(By.XPATH, '//*[@id="lg"]'): # 因为是个图片不方便所以用个输出看是否成功
print("OK")
else:
print("没有")前边的*号标识我不管他是什么标签只要是它的id属实等于lg就可以。
//div[@id='lg']/a/ul[2]/li
这个表达式是:找到id属性等于lg的div标签下边的a标签下边的第二个ul标签下边的li标签。
只做简单的阐述,更详细的就通过其他的博主那里学习一下吧。今天水一下。哈哈哈哈。
还可以通过属性的组合、包含的文字、轴定位(俗话说得,兄弟姐妹,都可以靠一靠。哈哈哈)














 4676
4676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









