






概要
ASPP主要用于解决语义分割任务中的尺度问题。在语义分割任务中,需要将图像中的每个像素分类到不同的类别中,而不同物体和结构在图像中可能有不同的尺度。传统的卷积神经网络在提取语义信息时,只能通过固定尺度的卷积核进行操作,因此无法很好地捕捉到不同尺度下的上下文信息。
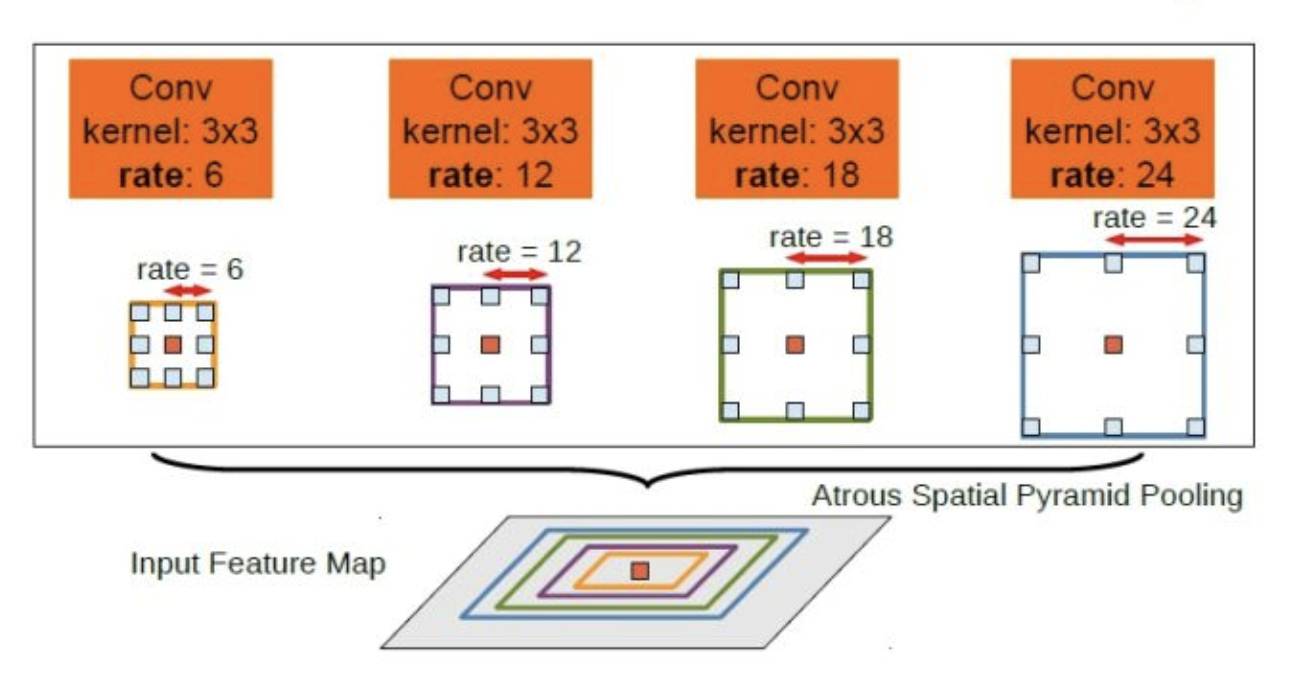
ASPP通过在网络中引入多个并行的分支,每个分支使用不同尺度的空洞卷积和池化操作,来捕获不同级别的上下文信息。通过使用不同的空洞率(或称为膨胀率)进行空洞卷积,可以扩大感受野( receptive field),从而获得更广阔的上下文信息。同时,池化操作可以在不同尺度上进行信息的聚合,增加网络对不同尺度物体和结构的感知能力。
-
多尺度感知:ASPP通过并行地应用不同尺度的空洞卷积和池化操作,能够捕获图像中不同级别的上下文信息,实现多尺度感知。
-
扩大感受野:通过使用不同的空洞率(膨胀率)进行空洞卷积,ASPP能够扩大感受野,使神经网络能够更好地理解更广阔的上下文信息。
-
物体和结构的多尺度处理:传统的卷积操作只能处理固定尺度的物体和结构,而ASPP可以通过多尺度的空洞卷积和池化操作来处理不同尺度的物体和结构。
-
上下文信息融合:ASPP利用并行分支对不同尺度的特征进行处理,并通过池化操作将不同尺度的上下文信息融合,增加网络对不同尺度物体和结构的感知能力。
整体架构流程
演化过程与代码实现
- DeepLab v1
在这个版本中,没有明确的ASPP模块,但是这个版本开始引入了空洞卷积(Dilated Convolutions)。 - DeepLab v2
DeepLab v2首次引入了ASPP模块。ASPP是通过在输入上并行应用多个带有不同采样率的空洞卷积来实现的,目的是在多个不同的尺度上捕捉图像上下文。每个空洞卷积在对输入进行处理时,都会使用不同的采样率(或者叫做空洞率),从而产生不同的感受野大小。
import torch
from torch import nn
import torch.nn.functional as F
class ASPP_v2(nn.Module):
def __init__(self, in_channels=2048, out_channels=256, rates=[6, 12, 18, 24]):
super(ASPP_v2, self).__init__()
self.aspp1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, dilation=rates[0])
self.aspp2 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=rates[1], dilation=rates[1])
self.aspp3 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=rates[2], dilation=rates[2])
self.aspp4 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=rates[3], dilation=rates[3])
def forward(self, x):
x1 = self.aspp1(x)
x2 = self.aspp2(x)
x3 = self.aspp3(x)
x4 = self.aspp4(x)
out = torch.cat((x1, x2, x3, x4), dim=1)
return out
- DeepLab v3
DeepLab v3: 在DeepLab v3中,对ASPP模块进行了改进,引入了全局平均池化层,将全局上下文信息并入ASPP模块中,以增强模型的全局上下文理解能力。
import torch
from torch import nn
import torch.nn.functional as F
class ASPP_v3(nn.Module):
def __init__(self, in_channels=2048, out_channels=256, rates=[6, 12, 18, 24]):
super(ASPP_v3, self).__init__()
self.aspp1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, dilation=rates[0])
self.aspp2 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=rates[1], dilation=rates[1])
self.aspp3 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=rates[2], dilation=rates[2])
self.aspp4 = nn.Conv2d(in_channels,out_channels, kernel_size=3, stride=1, padding=rates[3], dilation=rates[3])
self.global_avg_pool = nn.Sequential(nn.AdaptiveAvgPool2d((1, 1)),
nn.Conv2d(in_channels, out_channels, 1, stride=1, padding=0))
def forward(self, x):
x1 = self.aspp1(x)
x2 = self.aspp2(x)
x3 = self.aspp3(x)
x4 = self.aspp4(x)
x5 = self.global_avg_pool(x)
x5 = F.interpolate(x5, size=x.size()[2:], mode='bilinear', align_corners=True)
out = torch.cat((x1, x2, x3, x4, x5), dim=1)
return out
- DeepLab v3+
DeepLab v3+使用了深度可分离卷积(Depthwise Separable Convolution),这是一种更高效的卷积方式。
import torch
from torch import nn
from torch.nn import functional as F
class ASPPConv(nn.Sequential):
def __init__(self, in_channels, out_channels, dilation):
super().__init__(
nn.Conv2d(
in_channels,
out_channels,
kernel_size=3,
padding=dilation,
dilation=dilation,
bias=False,
),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
)
class ASPPSeparableConv(nn.Sequential):
def __init__(self, in_channels, out_channels, dilation):
super().__init__(
SeparableConv2d(
in_channels,
out_channels,
kernel_size=3,
padding=dilation,
dilation=dilation,
bias=False,
),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
)
class ASPPPooling(nn.Sequential):
def __init__(self, in_channels, out_channels):
super().__init__(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
)
def forward(self, x):
size = x.shape[-2:]
for mod in self:
x = mod(x)
return F.interpolate(x, size=size, mode="bilinear", align_corners=False)
class ASPP(nn.Module):
def __init__(self, in_channels, out_channels, atrous_rates, separable=False):
super(ASPP, self).__init__()
modules = []
modules.append(
nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
)
)
rate1, rate2, rate3 = tuple(atrous_rates)
ASPPConvModule = ASPPConv if not separable else ASPPSeparableConv
modules.append(ASPPConvModule(in_channels, out_channels, rate1))
modules.append(ASPPConvModule(in_channels, out_channels, rate2))
modules.append(ASPPConvModule(in_channels, out_channels, rate3))
modules.append(ASPPPooling(in_channels, out_channels))
self.convs = nn.ModuleList(modules)
self.project = nn.Sequential(
nn.Conv2d(5 * out_channels, out_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Dropout(0.5),
)
def forward(self, x):
res = []
for conv in self.convs:
res.append(conv(x))
res = torch.cat(res, dim=1)
return self.project(res)
class SeparableConv2d(nn.Sequential):
def __init__(
self,
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
bias=True,
):
dephtwise_conv = nn.Conv2d(
in_channels,
in_channels,
kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=in_channels,
bias=False,
)
pointwise_conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=1,
bias=bias,
)
super().__init__(dephtwise_conv, pointwise_conv)

















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









