







前言: 本文将大致浏览数据结构中,网络,算法的一小部分,不涉及大量代码,请放心食用;
第一章:算法的基本知识
本章的重点是运行时间的计算方法;笼统的来讲,运行时间描述的是数据量线性增长时运行时间的变化规律;我们将运行时间写为:O(表达式)
在计算机中每个内存单元都有自己的编号,也就是说在处理器眼中它们是线性且连续排列的;访问某个确定的内存单元时,也可以使用明确的内存地址来具体访问某个单元;
1.链表:
链表的结构:
链表单元不一定在内存中是连续存储的,但因为指针,访问时可以按顺序访问;
- 好处是添加新单元的复杂度为1
- 缺点是访问数据的复杂度为n,因为查找某个单元必须从头逐个按顺序扫描每个单元直到找到目标单元;
添加单元:
修改指针的方向,让B指向D并让D指向C:
这样我们就成功将单元D插入到了C和B的中间;要删除单元时,只需反向执行这个过程;
对于上面这个过程,查找数据的复杂度是O(n),插入数据的复杂度是O(1),删除数据的复杂度也是O(1);
另外链表也有其它变体:
上图是单元间首尾相连的循环链表
下图是单元间指针双向的双向链表
2.数组:
数组是一种很基本的数据结构,以至于绝大部分编程语言将它嵌入了本身,而非交给程序员实现;对于数组来说,要删除或添加一个元素时,必须将其后的元素全部向前或先后挪动,因此复杂度为O(n),而访问数据时,只要知道下标就能直接访问,因此复杂度为O(1)
下面总结一下链表和数组的优缺点:
| 访问 | 添加 | 删除 | |
|---|---|---|---|
| 链表 | 慢 | 快 | 快 |
| 数组 | 快 | 慢 | 慢 |
3.栈
栈是一种从同一端输入,同一端读取的数据结构;首先是压栈:
现在将一个元素压入栈中:
弹出数据的过成则正好和压栈的过程相反;压入栈中的数据有个特点:最先添加的数据最后被取出,又称为LIFO(last in first out)规则;
不过这有什么用呢?举个例子,可以利用栈来检测源代码的括号是否正确闭合了;判断括号正确闭合的标准是:Ⅰ.一段源代码可以由相同类型的一对括号包裹;Ⅱ.括号可以嵌套;
根据这两条规则我们可以设计一个判断括号是否正确闭合的算法,它的数据基础是一个栈,用来存储括号;程序逻辑包括:
- 读左括号压栈
- 读右括号和栈顶匹配则弹出栈顶元素,否则压栈
程序执行完毕后,若栈不为空,则说明有括号没有匹配;
4.队列
队列也是一种线性数据结构,但和栈不同,它的读写规则是:从一端添加数据,从另一端取出数据;
将数据写入一个队列:
将D写入后:
现在让我们从上面的队列中取出一个元素:
对于这种数据结构,比较常见的做法是服务器中对服务请求的处理:新的申请添加在写入端,每次从读取端取出一项任务进行处理;
队列也称FIFO(first in first out),即先进先出;
5.哈希表
现在我们已经了解了数组和链表,针对高读写低访问需求的场景可以选择链表,针对高访问低读写的场景可以选择数组;但是,有没有哪种数据结构能做到读写和访问都相对较快呢?
有。这种数据结构叫“链表”;
文章后面会提到哈希函数,现在你只需要了解它的作用是:根据数据的特征,生成一个长度固定的编码;**对于相似的数据,它们的编码大相径庭;对于相去甚远的数据,甚至可能具有相同的编码;**这种编码我们称它为哈希值;
有了这种编码能怎样呢?假设我们创建了一个很庞大的数组,要写入一个数据时,我们可以直接将哈希值作为下标,要访问时也可以通过要查找的数据的哈希值直接找到它;当两个元素的哈希值重复时,可以把要添加的元素以链表的形式添加在现有元素后面;
看起来这种数据结构真的很棒——它的访问和读写性能都很优异,但它真的没有缺点吗?
有。比如为了实现哈希表,你需要地毯式申请空间,创建一个数组但可能其中某些单元并没有被写入数据;换句话说,这时拿空间换时间的妥协;
这是百度百科的一张哈希表示意图:
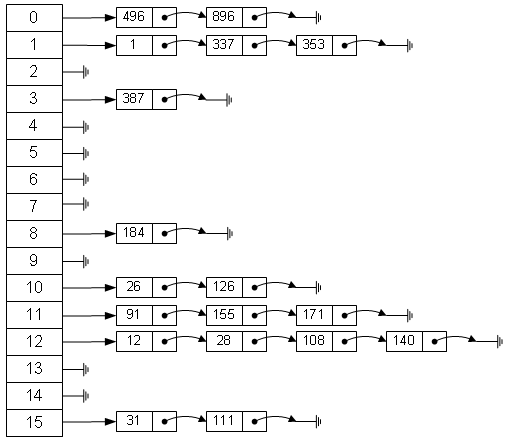
这里另外还要补充一点,上面解决哈希值相等时发生冲突的方法称为链地址法,除此之外还有开放地址法,指当冲突发生时立刻计算出一个候补位置如果仍然冲突则计算喜爱个候补位置直到有空地址时;















 3726
3726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









