






1.数据集来源
需要自己注册一个Kaggle账号才能获取:Pima Indians Diabetes Database | Kaggle
或者从我的百度网盘中获取:
链接:https://pan.baidu.com/s/11HAgMGGHXIUZPZJTPUAKkA
提取码:wjjd
2.数据分析
从csv文件中可以看到,最后一列是“是否患病”,前边几列都是影响是否患病的因素。在进行深度学习模型搭建之前,需要进行数据预处理工作,这是非常必要的。
3.代码
本文基于Pytorch框架编程。作者自认为有难度的代码部分都进行了注释,读者可以自行参考。由于作者本人也是一名新手,欢迎大家随时来访,共同交流学习。
import torch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import torch.nn.functional as F
doc = pd.read_csv('G:/diabetes.csv') # 读取数据集信息,改成自己的csv文件所在的目录,不能有中文
# print(doc.head()) # 显示导入的数据前5行 此处必须加print 否则不显示不报错
print(doc.shape[0], doc.shape[1]) # 查看数据集行数和列数 大小为768*9
# 查看是否有空缺值 两种方法 发现没有
# print(doc.isnull().sum())
# print(doc.isna().sum())
# 分别检查数据中有存在零的情况 (怀孕次数不需要检查)如下:
print("Glucose=0: ", doc[doc.Glucose == 0].shape[0]) # 血糖有5例为零,不符合实际情况
print("BloodPressure=0:", doc[doc.BloodPressure == 0].shape[0]) # 血压有35例为零
print("SkinThickness=0:", doc[doc.SkinThickness == 0].shape[0]) # 皮肤厚度有227例为零
print("Insulin=0:", doc[doc.Insulin == 0].shape[0]) # 胰岛素有374例为零
print("BMI=0:", doc[doc.BMI == 0].shape[0]) # BMI有11例为零
print("DiabetesPedigreeFunction=0:", doc[doc.DiabetesPedigreeFunction == 0].shape[0]) # 糖尿病谱系功能无异常
print("Age=0:", doc[doc.Age == 0].shape[0]) # 年龄无异常
# 处理无效值
# 删除 Glucose 和 BMI 中无效的行
doc_next = doc[(doc.Glucose != 0) & (doc.BMI !=0)]
print(doc_next.shape) # 此时数据大小变为 752*9
# 对于确实量大的用平均值填充
def mean_column(feature):
temp = doc_next[doc_next[feature] != 0]
temp = temp[[feature, 'Outcome']].groupby(['Outcome'])[[feature]].mean().reset_index() # 重置索引
return temp
print(mean_column('BloodPressure'))
# 血压数据填充
doc_next.loc[(doc_next['Outcome'] == 0) & (doc_next['BloodPressure'] == 0), 'BloodPressure'] = \
mean_column('BloodPressure')['BloodPressure'][0]
doc_next.loc[(doc_next['Outcome'] == 1) & (doc_next['BloodPressure'] == 0), 'BloodPressure'] = \
mean_column('BloodPressure')['BloodPressure'][1]
# 皮肤厚度数据填充
doc_next.loc[(doc_next['Outcome'] == 0) & (doc_next['SkinThickness'] == 0), 'SkinThickness'] = \
mean_column('SkinThickness')['SkinThickness'][0]
doc_next.loc[(doc_next['Outcome'] == 1) & (doc_next['SkinThickness'] == 0), 'SkinThickness'] = \
mean_column('SkinThickness')['SkinThickness'][1]
# 胰岛素数据填充
doc_next.loc[(doc_next['Outcome'] == 0) & (doc_next['Insulin'] == 0), 'Insulin'] = \
mean_column('Insulin')['Insulin'][0]
doc_next.loc[(doc_next['Outcome'] == 1) & (doc_next['Insulin'] == 0), 'Insulin'] = \
mean_column('Insulin')['Insulin'][1]
# 检验是否还有零值
"""
print("Glucose=0: ", doc_next[doc_next.Glucose == 0].shape[0]) # 血糖有5例为零,不符合实际情况
print("BloodPressure=0:", doc_next[doc_next.BloodPressure == 0].shape[0]) # 血压有35例为零
print("SkinThickness=0:", doc_next[doc_next.SkinThickness == 0].shape[0]) # 皮肤厚度有227例为零
print("Insulin=0:", doc_next[doc_next.Insulin == 0].shape[0]) # 胰岛素有374例为零
print("BMI=0:", doc_next[doc_next.BMI == 0].shape[0]) # BMI有11例为零
print("DiabetesPedigreeFunction=0:", doc_next[doc_next.DiabetesPedigreeFunction == 0].shape[0]) # 糖尿病谱系功能无异常
print("Age=0:", doc_next[doc_next.Age == 0].shape[0]) # 年龄无异常
"""
# 全部列显示出来
# pd.set_option('display.max_columns', 10)
# print(doc_next.head(10))
# 特征选取
inputs, outputs = doc_next.iloc[:, 0:8], doc_next.iloc[:, 8]
# 归一化
# 输入归一化
inputs_mean = inputs.mean()
inputs_std = inputs.std()
inputs = (inputs - inputs_mean) / inputs_std
# print(inputs.shape, outputs.shape)
# training set and testing set
in_train = inputs.iloc[0:602, :]
in_train = in_train.values # 想转为tensor类型,得把数值提取出来
in_train = torch.tensor(in_train).to(torch.float32) # 将DataFrame类型转换为Tensor类型,然后再转为float32类型,否则无法输入到网络中
out_train = outputs.iloc[0:602]
out_train = out_train.values
out_train = torch.tensor(out_train).to(torch.float32).reshape(602, 1)
in_test = inputs.iloc[602:, :]
in_test = in_test.values
in_test = torch.tensor(in_test).to(torch.float32)
out_test = outputs.iloc[602:]
out_test = out_test.values
out_test = torch.tensor(out_test).to(torch.float32)
# print(in_test.shape, out_test.shape)
# 定义网络
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.linear1 = torch.nn.Linear(8, 72)
self.linear2 = torch.nn.Linear(72, 64)
self.linear3 = torch.nn.Linear(64, 1)
def forward(self, x):
x = F.relu(self.linear1(x))
x = F.relu(self.linear2(x))
x = F.relu(self.linear3(x))
return x
model = Net()
# 定于损失函数和优化器
criterion = torch.nn.MSELoss(size_average=None)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
loss_store = [] # 用于存储每一步的loss值,用于之后的plt绘制
iter = [] # 每执行一步,iter都会加一,否则如果在plt.plot()中直接用epoch或者len(str(loss_store)会出现维度不匹配
def train():
acc = 0
for epoch in range(1001):
iter.append(epoch) # iter空间加一
out_pred = model(in_train) # 将training set输入到网络中,得到输出的predication
# print(out_pred)
loss = criterion(out_pred, out_train) # 计算损失(目标真实值和预测值)
# print(epoch, loss.item())
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 梯度更新
loss_store.append(loss.item()) # 存储loss值
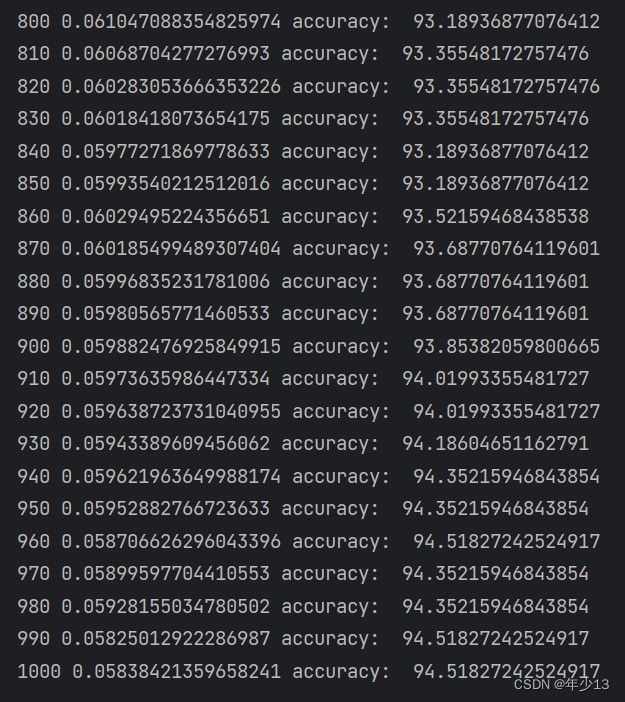
if epoch % 10 == 0:
out_pred_lable = torch.where(out_pred >= 0.5, torch.tensor([1.0]), torch.tensor([0.0])) # condition (bool型张量) :当condition为真,返回x的值,否则返回y的值
# print(out_train)
acc = torch.eq(out_pred_lable, out_train.reshape(602, 1)).sum().item()
print(epoch, loss.item(), 'accuracy: ', 100 * acc / len(in_train))
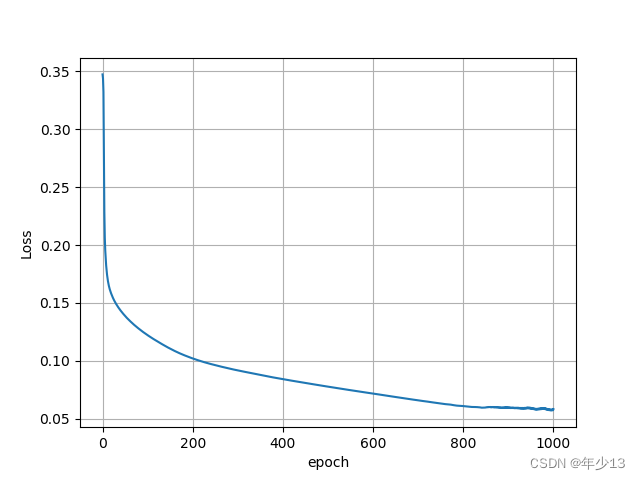
plt.plot(iter, loss_store)
plt.xlabel('epoch')
plt.ylabel('Loss')
plt.grid() # 显示网格
plt.show() # 这一步必须加,没有就不会出图
def test():
acc = 0
# 测试无需计算梯度
with torch.no_grad():
out_test_pre = model(in_test)
print(out_test_pre.shape)
# predicted = out_test_pre.argmax(dim=0, keepdim=True)
# print(predicted)
out_pred_test_lable = torch.where(out_test_pre >= 0.5, torch.tensor([1.0]), torch.tensor([0.0]))
acc = torch.eq(out_pred_test_lable, out_test.reshape(150, 1)).sum().item()
print('accuracy: ', 100*acc/len(in_test))
if __name__ == '__main__':
train()
# test()4.代码运行结果
(1)Loss损失函数曲线
(2)损失函数和准确率展示















 2551
2551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









