






目录
1.什么是拉链表
我们首先要知道,拉链表是一个逻辑上的概念。
拉链表记录的是增量数据,它通过不断的同步增量数据来构成,不断进行数据清洗。
拉链表有数据的开始日期和结束日期,记录着数据的生命周期。(有开始有结束,也因此被称为拉链)
总而言之,拉链表通过增量表进行不断的更新
2.拉链表的产生背景
Hive在实际工作中主要用于构建离线数据仓库。而说到拉链表的产生背景,我们就不得不提到离线数仓中的数据同步问题
2.1数据同步
我们知道,数据同步分为增量同步和全量同步。
2.1.1全量同步
全量同步,就是每天都将业务数据库中的全部数据同步一份到数据仓库,这是保证两侧数据同步的最简单的方式。
2.1.2增量同步
增量同步,就是每天只将业务数据中的新增及变化数据同步到数据仓库。采用每日增量同步的表,通常需要在首日先进行一次全量同步。
2.2增量同步和拉链表
全量同步逻辑简单也容易使用,但在有些情况下效率较低:例如某张表数据量较大,但是每天数据的变化比例很低,若对其采用每日全量同步,则会重复同步和存储大量相同的数据。
此时增量同步应运而生:构建拉链表,插入增量数据,通过时间标记发生变化的数据的每种状态的时间周期
3.拉链表的实现方式
3.1数据准备
1.构建模拟数据:
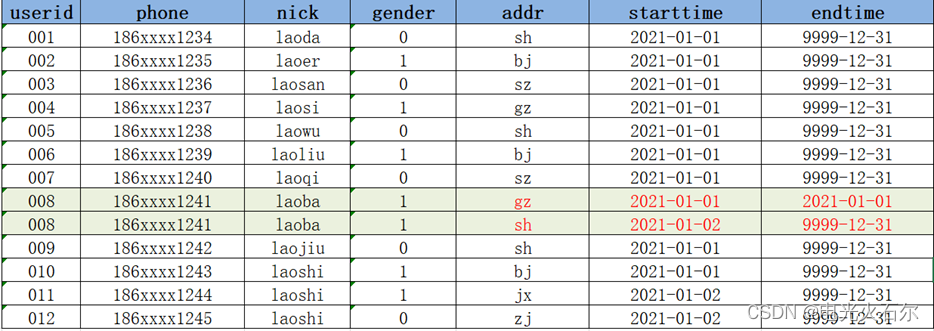
拉链表数据:
vim /export/data/zipper.txt
001 186xxxx1234 laoda 0 sh 2021-01-01 9999-12-31
002 186xxxx1235 laoer 1 bj 2021-01-01 9999-12-31
003 186xxxx1236 laosan 0 sz 2021-01-01 9999-12-31
004 186xxxx1237 laosi 1 gz 2021-01-01 9999-12-31
005 186xxxx1238 laowu 0 sh 2021-01-01 9999-12-31
006 186xxxx1239 laoliu 1 bj 2021-01-01 9999-12-31
007 186xxxx1240 laoqi 0 sz 2021-01-01 9999-12-31
008 186xxxx1241 laoba 1 gz 2021-01-01 9999-12-31
009 186xxxx1242 laojiu 0 sh 2021-01-01 9999-12-31
010 186xxxx1243 laoshi 1 bj 2021-01-01 9999-12-31
增量表数据:
vim /export/data/update.txt
008 186xxxx1241 laoba 1 sh 2021-01-02 9999-12-31
011 186xxxx1244 laoshi 1 jx 2021-01-02 9999-12-31
012 186xxxx1245 laoshi 0 zj 2021-01-02 9999-12-31
-- 拉链表
create temporary table dw_zipper
(
userid string,
phone string,
nick string,
gender int,
addr string,
starttime string,
endtime string
) row format delimited fields terminated by '\t';
load data local inpath '/export/data/zipper.txt' into table dw_zipper;
-- 增量表
create temporary table ods_zipper_update
(
userid string,
phone string,
nick string,
gender int,
addr string,
starttime string,
endtime string
) row format delimited fields terminated by '\t';
load data local inpath '/export/data/update.txt' into table ods_zipper_update;3.2思路1
通过左连接 left join
先上代码:
-- step1 创建临时表,插入查询结果
drop table if exists tmp_zipper2;
create table if not exists tmp_zipper2(
userid string,
phone string,
nick string,
gender int,
addr string,
starttime string
)partitioned by (endtime string)
row format delimited fields terminated by '\t';
-- step2 合并拉链表和增量表并插入到临时表
-- left join 则是为了修改旧拉链表中(update数据)的endtime
-- union all 是为了合并增量表和修改了endtime的旧拉链表
-- 从而合成临时表,再把临时表插入旧拉链表中作为新的拉链表
insert overwrite table tmp_zipper
select userid, phone, nick, gender, addr, starttime, endtime
from ods_zipper_update
union all --union all是拼接两个表,join是交集之类的?
--查询原来拉链表的所有数据,并将这次需要更新的数据的endTime更改为更新值的startTime
select a.userid, a.phone, a.nick, a.gender, a.addr, a.starttime, if(b.userid is null or a.endtime < '9999-12-31', a.endtime , date_sub(b.starttime,1)) as endtime
from dw_zipper a
left join
ods_zipper_update b on a.userid = b.userid ;
通过 拉链表左连接增量表 修改拉链表endtime字段:若拉链表和增量表中存在相同的userid,则修改拉链表中的endtime字段为增量表中starttime字段的前一天
然后再合并(修改了endtime字段的拉链表)和 (增量表)

3.3思路2
使用窗口函数 lag() 和 row_number()
先上代码:
drop table if exists tmp_zipper3;
create table if not exists tmp_zipper3(
userid string,
phone string,
nick string,
gender int,
addr string,
starttime string
)partitioned by (endtime string)
row format delimited fields terminated by '\t';
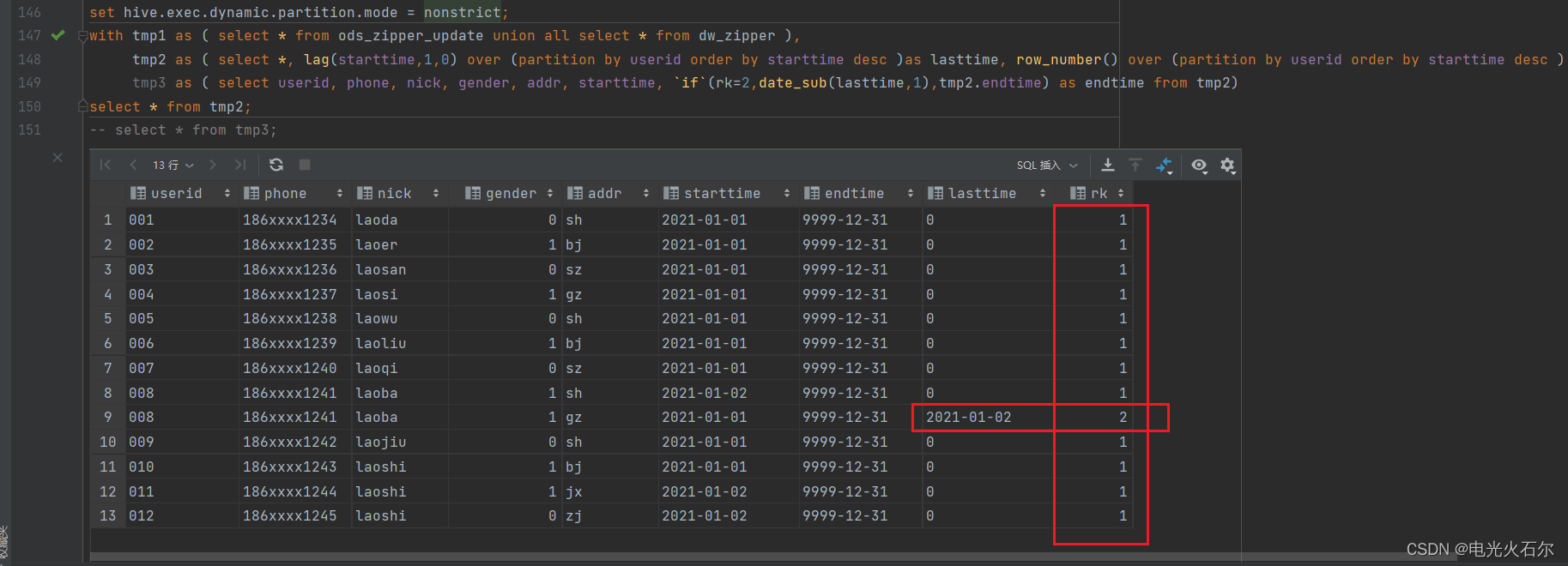
set hive.exec.dynamic.partition.mode = nonstrict;
with tmp1 as ( select * from ods_zipper_update union all select * from dw_zipper ),
tmp2 as ( select *, lag(starttime,1,0) over (partition by userid order by starttime desc )as lasttime, row_number() over (partition by userid order by starttime desc ) as rk from tmp1),
tmp3 as ( select userid, phone, nick, gender, addr, starttime, `if`(rk=2,date_sub(lasttime,1),tmp2.endtime) as endtime from tmp2)
insert overwrite table tmp_zipper3 partition(endtime) select userid, phone, nick, gender, addr, starttime, endtime from tmp3 ;
使用窗口函数 lag() 和 row_number():
首先合并拉链表和增量表;
使用row_number() 函数对合并表中对userid进行分区排序,
使用lag()函数获取userid分区中的上一行数据的endtime字段
使row_number()字段为2的数据修改endtime字段为lag()函数获取的上一行数据的endtime字段-1
有不理解的地方对上面各子查询进行select查看结果即可。
















 712
712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











