







目录
一、什么是JDBC
JDBC(Java Database Connectivity)是Java编程语言中用于连接和操作数据库的标准API。它提供了一组接口和类,使Java应用程序能够与关系型数据库建立连接,并进行数据的读取、写入、更新和删除等操作。
JDBC的工作原理是通过使用不同的数据库驱动程序(Driver)来实现与各种数据库的通信。每个数据库提供商通常都会提供自己的JDBC驱动程序,开发人员只需按照JDBC API的标准接口编写代码,通过加载相应的驱动程序,就能连接到特定的数据库。
JDBC主要包含以下几个重要的组件:
1. DriverManager:负责加载和注册数据库驱动程序,并管理数据库连接。
2. Connection:表示与数据库的连接,通过它可以创建Statement(用于执行SQL语句)、PreparedStatement(预编译的SQL语句)和CallableStatement(用于调用存储过程)。
3. Statement、PreparedStatement、CallableStatement:用于执行SQL语句或存储过程,并获取执行结果。
4. ResultSet:表示数据库查询的结果集,可以通过它来遍历并获取查询结果的数据。
通过JDBC,开发人员可以使用标准的Java代码来访问和操作各种关系型数据库,无论是建立数据库连接、执行SQL语句还是处理查询结果,都可以通过JDBC提供的接口和方法来完成。这使得Java应用程序能够与数据库进行交互,读取和更新数据,并实现与数据库的集成。
二、JDBC的基本使用
直接上代码
package com.lzx.jdbc;
import java.sql.*;
public class demo1 {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
// 注册Mysql驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 创建数据库连接
Connection connection = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/mayiktmeite", "root", "123456");
// 获取到执行者对象
Statement statement = connection.createStatement();
// 执行自己编写的SQL查询语句
ResultSet resultSet = statement.executeQuery("select * from users");
//获取到每一行数据
while(resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
int age = resultSet.getInt("age");
System.out.println("id:"+id+","+"name:"+name+","+"age:"+age);
}
resultSet.close();
statement.close();
connection.close();
}
}
将要查询的表中数据如图所示

程序执行结果:
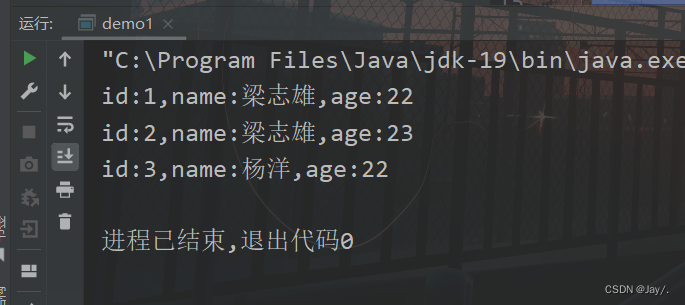
比较简单。
三、插曲1 双亲委派机制
在Java中,双亲委派机制是指类加载器的一种工作方式。Java中的类加载器使用双亲委派机制来加载类,确保类的加载是有序的,并且避免了重复加载。
当一个类需要被加载时,Java虚拟机的类加载器首先会将该任务委托给父类加载器,如果父类加载器能够加载成功,那么就直接返回父类加载器加载的类,而不会尝试自己去加载。只有当父类加载器无法完成加载任务时,子类加载器才会尝试加载类。
具体的双亲委派机制如下:
1. 当一个类需要被加载时,首先检查父类加载器是否已经加载了该类。如果是,则直接返回父类加载器加载的类。
2. 如果父类加载器没有加载该类,子类加载器会尝试自己加载该类。
3. 如果子类加载器仍然无法加载该类,则将加载请求传递给父类加载器的父类加载器,依此类推,形成一个类加载器层次结构。
4. 如果最顶层的父类加载器仍然无法加载该类,子类加载器会尝试自己加载。
5. 如果所有的父类加载器都无法加载该类,则会抛出ClassNotFoundException异常。
通过双亲委派机制,Java可以保证类的加载是有序的,避免了类的重复加载和冲突,同时也保证了类的安全性。
四、插曲2 SPI技术
在Java中,SPI(Service Provider Interface)是一种服务提供者接口的机制,用于实现模块化的插件化架构。SPI机制允许开发人员定义服务接口,并且允许第三方厂商按照该接口的规范提供自己的实现,实现了解耦和可扩展的效果。
SPI机制的核心思想是通过在classpath中的META-INF/services目录下创建一个以服务接口全限定名命名的文件,在该文件中列出所有提供者实现类的全限定名。Java的服务加载器在类加载的过程中会自动加载这些文件,并根据其中列出的实现类名实例化对象,从而实现了自动发现和加载服务的功能。
具体步骤如下:
1. 定义服务接口:开发人员首先定义一个接口,定义了一组服务的方法。
2. 创建服务提供者:第三方厂商根据服务接口的规范,实现自己的服务提供者类,并将该类打包为Jar文件。
3. 创建SPI配置文件:在classpath的META-INF/services目录下创建一个以服务接口全限定名命名的文件,比如"com.example.ServiceInterface"。文件的内容是实现类的全限定名,每行一个实现类。
4. 使用服务:在需要使用服务的地方,通过Java的服务加载器,加载并实例化提供者类,从而使用服务。
SPI机制使得应用程序可以在不修改源代码的情况下,通过添加和替换服务提供者来扩展功能。它广泛应用于许多Java的标准库和框架中,比如JDBC数据库驱动、日志框架等。
五、什么是SQL注入攻击
使用SQL语句拼接形式访问数据库容易遭到SQL注入攻击。
5.1 如何解决SQL注入攻击
使用预编译执行者对象PrepareStatement
六、C3P0数据库连接池配置步骤
6.1 包依赖:
使用C3P0连接池,需要在项目中引入以下两个JAR包依赖:
1. c3p0.jar:这是C3P0库的核心文件。
2. mchange-commons-java.jar:这是C3P0库的依赖文件。
可以通过在项目的pom.xml文件中添加以下Maven依赖项来获取这些JAR包:
<dependencies>
...
<dependency>
<groupId>com.mchange</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.5.5</version>
</dependency>
<dependency>
<groupId>org.mchange</groupId>
<artifactId>mchange-commons-java</artifactId>
<version>0.2.16</version>
</dependency>
...
</dependencies>
```当你构建和运行项目时,Maven将自动下载并添加这些依赖项到你的项目中。如果你不使用Maven,可以手动下载这些JAR文件并将其添加到项目的类路径中。
6.2 在src目录下新建c3p0-config.xml
在该文件下填入
<c3p0-config>
<default-config>
<!-- 使用连接池的数据源配置 -->
<property name="jdbcUrl">jdbc:mysql://localhost:3306/testdb</property>
<property name="user">root</property>
<property name="password">password</property>
<!-- 连接池的一些配置 -->
<property name="acquireIncrement">5</property>
<property name="initialPoolSize">10</property>
<property name="minPoolSize">5</property>
<property name="maxPoolSize">20</property>
<property name="maxIdleTime">1800</property>
<property name="idleConnectionTestPeriod">300</property>
<property name="preferredTestQuery">SELECT 1</property>
</default-config>
</c3p0-config>默认会读取该文件,不用显式读取。
在上述示例中,通过<default-config>标签定义了连接池的默认配置。其中,<property>标签用于设置连接池的各项属性。以下是一些常用的属性说明:
- jdbcUrl:数据库连接的URL。
- user:数据库用户名。
- password:数据库密码。
- acquireIncrement:每次获取连接时,连接池自动增加的连接数。
- initialPoolSize:连接池的初始连接数。
- minPoolSize:连接池中的最小连接数。
- maxPoolSize:连接池中的最大连接数。
- maxIdleTime:连接在池中保持空闲的最大时间(以秒为单位)。
- idleConnectionTestPeriod:检查空闲连接状态的时间间隔(以秒为单位)。
- preferredTestQuery:检查连接是否可用的SQL查询语句。
你可以根据需要调整这些配置属性,然后将c3p0-config.xml文件放置在类路径下,C3P0将自动加载和使用该配置文件。
注意:如果你不提供c3p0-config.xml配置文件,C3P0将使用默认的连接池配置。也可以在代码中通过C3P0的API进行配置,以覆盖c3p0-config.xml中的设置。
6.3 c3p0.properties
c3p0.properties是C3P0连接池的配置文件,它提供了一种替代c3p0-config.xml的方式来设置连接池的参数和配置选项。下面是一个c3p0.properties的示例:
c3p0.jdbcUrl=jdbc:mysql://localhost:3306/testdb
c3p0.user=root
c3p0.password=password
c3p0.acquireIncrement=5
c3p0.initialPoolSize=10
c3p0.minPoolSize=5
c3p0.maxPoolSize=20
c3p0.maxIdleTime=1800
c3p0.idleConnectionTestPeriod=300
c3p0.preferredTestQuery=SELECT 1
```在上述示例中,每个属性的名称都以c3p0.作为前缀,然后紧随连接池配置的属性名。例如,c3p0.jdbcUrl对应的是数据库连接的URL,c3p0.user对应的是数据库用户名,以此类推。
你可以根据需要调整这些配置属性,然后将c3p0.properties文件放置在类路径下。C3P0会自动加载并使用该配置文件中的属性设置连接池。
当同时存在c3p0.properties和c3p0-config.xml时,C3P0会优先使用c3p0.properties文件中的配置。如果两者都不存在,则C3P0将使用默认的连接池配置。
七、Druid数据库连接池配置步骤
Druid是一个开源的Java数据库连接池库,它提供了高性能、可靠性和丰富的监控功能。以下是使用Druid数据库连接池的详细步骤:
1. 在项目中引入Druid的依赖项,可以将以下 Maven 依赖项添加到项目的 pom.xml 文件中:
<dependencies>
...
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.6</version>
</dependency>
...
</dependencies>
```2. 创建一个数据库连接配置类,例如 `DBConfig`,用于存储数据库连接的相关信息:
public class DBConfig {
private static final String URL = "jdbc:mysql://localhost:3306/testdb";
private static final String USERNAME = "root";
private static final String PASSWORD = "password";
public static String getUrl() {
return URL;
}
public static String getUsername() {
return USERNAME;
}
public static String getPassword() {
return PASSWORD;
}
}
```3. 创建一个连接池配置类,例如 `DruidConfig`,用于配置Druid连接池的参数:
import com.alibaba.druid.pool.DruidDataSource;
import java.sql.Connection;
import java.sql.SQLException;
public class DruidConfig {
private static DruidDataSource dataSource;
static {
dataSource = new DruidDataSource();
dataSource.setUrl(DBConfig.getUrl());
dataSource.setUsername(DBConfig.getUsername());
dataSource.setPassword(DBConfig.getPassword());
}
public static synchronized Connection getConnection() throws SQLException {
return dataSource.getConnection();
}
}
```在上述示例中,我们创建了一个 DruidDataSource 对象,并通过 DBConfig类中的数据库连接信息进行配置。然后,通过调用 getConnection() 方法来获取数据库连接。4. 在应用程序中使用Druid连接池来获取连接并执行数据库操作:
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class Application {
public static void main(String[] args) {
try (Connection conn = DruidConfig.getConnection()) {
String sql = "SELECT * FROM users";
PreparedStatement statement = conn.prepareStatement(sql);
ResultSet resultSet = statement.executeQuery();
while (resultSet.next()) {
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
int age = resultSet.getInt("age");
System.out.println("ID: " + id + ", Name: " + name + ", Age: " + age);
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
```在上述示例中,通过调用 DruidConfig.getConnection() 方法从Druid连接池中获取一个连接,然后使用该连接执行数据库操作。
使用Druid连接池的好处是它不仅具备连接池管理和连接池配置的功能,还提供了丰富的监控和统计功能,可以帮助你更好地分析和优化数据库连接的使用情况。此外,Druid还支持连接泄漏监测、SQL执行性能监控、防御SQL注入攻击等特性。你可以根据实际需求,灵活配置和使用Druid连接池的各种功能。















 2437
2437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











