







算法篇
线性回归
线性回归属于有监督学习中的回归算法,只能处理标签是连续数据类型的数据。通过寻找特征和标签之间的关系,生成线性方程,所以线性回归算法只针对线性回归方程。
多元线性回归方程:
y
=
a
1
x
1
+
a
2
x
2
+
.
.
.
.
+
a
n
x
n
+
b
y=a_1x_1+a_2x_2+....+a_nx_n+b
y=a1x1+a2x2+....+anxn+b
假设具有n个特征的样本和标签的关系是线性的,可以将其定义为多元线性回归:
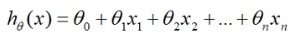
其中,n表示特征数目,因为还有一个回归参数b是没有未知数的所以需要添加一列
x
0
=
1
x_0=1
x0=1
线性回归系数求解
正规方程法
均方误差损失函数:
L o s s = ∑ ( y i − ( w 1 x 1 + w 2 x 2 + . . . . . + w n x n + b ) ) 2 Loss=∑(y^i-(w_1x_1+w_2x_2+.....+w_nx_n+b))^2 Loss=∑(yi−(w1x1+w2x2+.....+wnxn+b))2
备 注 : w 是 行 向 量 , x 是 列 向 量 备注:w是行向量,x是列向量 备注:w是行向量,x是列向量
正规方程法就是令均方误差损失函数的导数等于0,获取回归系数
L
o
s
s
=
∑
(
y
i
−
w
x
i
)
2
Loss=∑(y^i-wx^i)^2
Loss=∑(yi−wxi)2
−
−
−
−
−
−
−
>
------->
−−−−−−−>求导得到以下结果
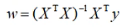
比如原数据集是有k个特征,那么求导结果就会是一个k+1行1列的数组,分别对应多元线性回归方程中的b和k
缺点:
- X T X X^TX XTX的逆不存在时无法计算
- 如果数据集样本或特征较多时,计算复杂度大
适用于数据量较小的时候
代码实现
from sklearn.linear_model import LinearRegression
# 实例化
alg = LinearRegression()
# 拟合
alg.fit(X_train, y_train)
# 查看回归系数
print('回归系数:', alg.coef_) # 返回的是一个数组
# 查看截距
print('截距:', alg.intercept_)
# 查看预测结果
y_pred = alg.predict(X_test)
print('预测结果:', y_pred)
# 查看R2
score = alg.score(X_test, y_test)
print('R2:', score)
随机梯度下降法
注意:使用随机梯度下降法时需要对数据进行标准化
随机梯度下降法不仅要使用导数的知识,还要使用偏导。所谓偏导就是将要求偏导的项的x作为未知数,其余的项全部视为常数,再求导即可。
和正规方程解一样,都是在寻找导数等于零的情况,随机梯度下降也需要使用均方误差损失函数Loss。
L o s s = ∑ ( y i − ( w 1 x 1 + w 2 x 2 + . . . . . + w n x n + b ) ) 2 Loss=∑(y^i-(w_1x_1+w_2x_2+.....+w_nx_n+b))^2 Loss=∑(yi−(w1x1+w2x2+.....+wnxn+b))2
预测值 y^ = w 1 x 1 + w 2 x 2 + . . . . . + w n x n + b =w_1x_1+w_2x_2+.....+w_nx_n+b =w1x1+w2x2+.....+wnxn+b
随机梯度下降的求解步骤为:
- 随机初始化一组 [ w 0 , w 1 , w 2 , w 3....... w n ] [w0,w1,w2,w3.......wn] [w0,w1,w2,w3.......wn]
- 根据初始化 w w w和特征值,计算出预测值y^
- 利用损失函数,计算真实值与预测值之间的误差和Loss
- 计算误差关于
w
w
w的偏导(
w
同
θ
w同θ
w同θ)
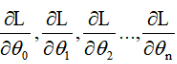
- 沿着梯度的负方向进行更新
w
w
w(
w
同
θ
w同θ
w同θ)
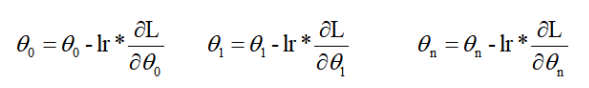
lr表示的是学习率,lr是小于零的数,意思就是当求出的偏导太大时,减去一个很大的值很容易跳过导数等于0的点,所以要用学习率来控制它梯度下降的幅度。 - 重复2-5步骤,直到达到一定的迭代次数或者损失小于某个值时停止。
代码实现
from sklearn.linear_model import SGDRegerssor
# 实例化
alg = SGDRegerssor()
# 参数:random_state=1
# 拟合
alg.fit(X_train, y_train)
# 查看回归系数
print('回归系数:', alg.coef_) # 返回的是一个数组
# 通过观察回归系数的大小可以观察出哪个系数对应的特征对标签影响最大或最小
# 查看截距
print('截距:', alg.intercept_)
# 查看预测结果
y_pred = alg.predict(X_test)
print('预测结果:', y_pred)
# 查看R2
score = alg.score(X_test, y_test)
print('R2:', score)
'''
随机梯度下降可以将样本分为多个分批次操作,避免数据量太大造成影响
'''















 340
340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









