






目录
Task01: 环境搭建 , 初识数据库(5.16-5.17)
课后习题:
Task01: 环境搭建 , 初识数据库(5.16-5.17)
课堂笔记:
初识数据库

数据库管理系统(Database Management System,DBMS):
用来管理数据库的计算机系统

-
创建数据库
CREATE DATABASE < 数据库名称 > ;- 创建表:
CREATE TABLE < 表名 >
(
< 列名 1> < 数据类型 > < 该列所需约束 > ,
< 列名 2> < 数据类型 > < 该列所需约束 > ,
< 列名 3>< 数据类型 > < 该列所需约束 > ,
< 列名 4> < 数据类型 > < 该列所需约束 > ,
. . .
< 该表的约束 1> , < 该表的约束 2> ,……
);- 基本的数据类型:
INTEGER型:存储整数型,不能存储小数。
CHAR型“:存储定长字符串
VARCHAR型:存储可变长度字符串
DATE型:指定存储日期(年月日),日期型
- 约束设置:
NOT NULL非空约束:即该列必须输入数据
PRIMARY KEY主键约束:该列是唯一值,因此我们能够通过该列取出特定的行的数据
示例:
-- 创建商品表product
CREATE TABLE product
(
-- CHAR:长字符串
product_id CHAR(4) NOT NULL,
-- VARCHAR:存储可变长度字符串
product_name VARCHAR(100) NOT NULL,
product_type VARCHAR(32)NOT NULL,
-- INTEGER:存储整数的列的数据类型(数字型),不能存储小数
sale_price INTEGER,
purchase_price INTEGER,
-- DATE:指定存储日期(年月日)的列的数据类型(日期型)
regist_date DATE,
-- 主键:
PRIMARY KEY (product_id)
);- 表的删除和更新
1. 删除表:
DROP TABLE < 表名 > ;2. 添加列
ALTER TABLE < 表名 > ADD COLUMN < 列的定义 >;3. 删除添加的列
ALTER TABLE < 表名 > DROP COLUMN < 列名 >;4. 删除特定的行
注意:一定要加上where语句,否则会删除所有的数据
DELETE FROM product WHERE COLUMN_NAME='XXX';5. 清空表内容
TRUNCATE TABLE <表名>;6. TRUNCATE 的清除速度最快
- 数据更新update(注意要添加where条件)
UPDATE <表名>
SET <列名> = <表达式> [, <列名2>=<表达式2>...],
<列名> = <表达式> [, <列名2>=<表达式2>...],
<列名> = <表达式> [, <列名2>=<表达式2>...]; (可以是多列)
WHERE <条件>; -- 可选,非常重要。
ORDER BY 子句; --可选
LIMIT 子句; --可选* UPDATE 也可以将列更新为 NULL
* update 时要注意添加 where 条件
* 如果条件where是一样的话,set 后可以加多列(想要改变的字段内的数据),用逗号隔开
- 表中插入数据
插入一行数据
INSERT INTO <表名> (列1, 列2, 列3, ……) VALUES (值1, 值2, 值3, NULL);* values对应的值包含全部列可以省略列名
* 否则列名要与数值一一对应
* 无需插入数值的直接在 `VALUES`子句的值`NULL` ,但在创建表的时候一定不能设置非空约束
插入多行数据
INSERT INTO <表名> VALUES (值1,NULL, 值3, ……),
(值1,NULL, 值3, ……),
(值1,NULL, 值3, ……); 索引
索引创建了一种有序的数据结构,采用二分法搜索数据
```sql
-- 方法1
CREATE INDEX indexName ON table_name (column_name)
-- 方法2
ALTER table tableName ADD INDEX indexName(columnName)
```课后习题:
第一题:
编写一条 CREATE TABLE 语句,用来创建一个包含表 1-A 中所列各项的表 Addressbook (地址簿),并为 regist_no (注册编号)列设置主键约束
表1-A 表 Addressbook (地址簿)中的列

# CREATE DATABASE task01;
# USE task01;
CREATE TABLE Addressbook
(
-- regist_no VARCHAR(128) NOT NULL,
regist_no int NOT NULL,
name VARCHAR(128) NOT NULL,
address VARCHAR(256) NOT NULL,
tel_no CHAR(10),
mail_adress CHAR(20),
PRIMARY KEY(regist_no)
);
第二题:
假设在创建练习1.1中的 Addressbook 表时忘记添加如下一列 postal_code (邮政编码)了,请编写 SQL 把此列添加到 Addressbook 表中。
列名 : postal_code
数据类型 :定长字符串类型(长度为 8)
约束 :不能为 NULL
ALTER TABLE Addressbook ADD COLUMN postal_code CHAR(8) NOT NULL;
第三题:
请补充如下 SQL 语句来删除 Addressbook 表。
TRUNCATE TABLE Addressbook;其中 TRUNCATE 的速度比drop 和 delate 快
第四题:
是否可以编写 SQL 语句来恢复删除掉的 Addressbook 表?
不可以,只可以重新创建
Task02:基础查询与排序(5.18-5.20)
课堂笔记:
从表中选取数据
通过SELECT语句查询从而得到我们想要的数据
SELECT <列名>,
<列名>,
<列名>,
......
FROM <表名> ;WHERE语句
用法:指定查询数据的条件
SELECT <列名>, ……
FROM <表名>
WHERE <条件表达式>;条件运算按照NOT、AND 、OR的优先级进行
-- 查询product_name, product_type,其中product_type = '衣服'
SELECT product_name, product_type
FROM product
WHERE product_type = '衣服'; 
-- 查询product_name,其中该product_name的product_type = '衣服'
SELECT product_name
FROM product
WHERE product_type = '衣服'; 
相关法则
(*)代表全部列
想要计算值的种类时,可以在COUNT函数的参数中使用DISTINCT。
在聚合函数的参数中使用DISTINCT,可以删除重复数据。
SELECT DISTINCT product_type
FROM product;
SELECT product_type
FROM product;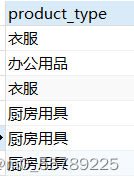
算术运算符和比较运算符
SELECT product_name, sale_price, purchase_price
FROM product
WHERE sale_price - purchase_price >= 500;常用法则
字符串类型的数据原则上按照字典顺序进行排序
空:IS NULL
非空:IS NOT NULL
SELECT product_name, purchase_price
FROM product
WHERE purchase_price IS NULL;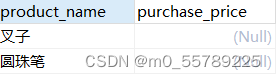
SELECT product_name, purchase_price
FROM product
WHERE purchase_price IS NOT NULL;
NOT运算符
NOT不能单独使用,必须和其他查询条件组合起来使用
SELECT product_name, product_type, sale_price
FROM product
WHERE NOT sale_price >= 1000;
-- NOT sale_price >= 1000 即 小于1000
-- NOT sale_price >= 1000 等价于 sale_price < 1000但NOT 运算符可读性明显不如显式指定查询条件,因此不可滥用
AND运算符和OR运算符
通过括号优先处理
这样的表达我们以为会得到regist_date = '2009-09-11'或者regist_date = '2009-09-20'的结果,且product_type = '办公用品' 但结果并不是这样
SELECT product_name, product_type, regist_date
FROM product
WHERE product_type = '办公用品'
AND regist_date = '2009-09-11'
OR regist_date = '2009-09-20';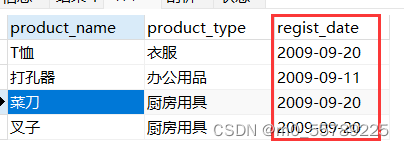
AND 运算符优先于 OR 运算符
SELECT product_name, product_type, regist_date
FROM product
WHERE product_type = '办公用品'
AND ( regist_date = '2009-09-11'
OR regist_date = '2009-09-20');
聚合函数
`COUNT()`查询有多少条记录 `COUNT (字段名)`作为返回数据的列名
通常,使用聚合查询时,我们应该给列名**设置一个别名**,便于处理结果
SELECT COUNT(字段名)别名 FROM表名;
`SUM()`计算某一列的合计值,该列必须为数值类型
`AVG()`计算某一列的平均值,该列必须为数值类型
`MAX()`计算某一列的最大值,若字符型,找字典序最大的
`MIN()`计算某一列的最小值,若字符型,找字典序最小的
SELECT COUNT(DISTINCT 字段名)别名 FROM表名;SELECT COUNT( DISTINCT product_type) FROM product;
SELECT COUNT(product_type)
FROM product;
-- 是否使用DISTINCT时的动作差异(SUM函数)
SELECT SUM(sale_price), SUM(DISTINCT sale_price)
FROM product;
常用法则
COUNT(*)会得到包含NULL的数据行数,而COUNT(<列名>)会得到NULL之外的数据行数
聚合函数会将NULL排除在外。但COUNT(*)例外,并不会排除NULL
SUM/AVG函数**只适用于数值类型的列**
MAX/MIN函数**几乎适用于所有数据类型的列**
对表进行分组
GROUP BY语句
将字段中数据相同的作为一组,该字段中有多少个不同的值,就会分成多少组
优先级高于聚合函数
`having` 作用相当于条件
常见错误
GROUP BY中不能使用别名
在聚合函数的SELECT子句中写了聚合健以外的列使用COUNT等聚合函数时,SELECT子句中如果出现列名,只能是GROUP BY子句中指定的列名(也就是聚合键)。
为聚合结果指定条件
用HAVING得到特定分组
HAVING子句用于对分组进行过滤,可以使用**数字、聚合函数和GROUP BY中指定的列名(聚合键**)
而WHERE子句只能指定记录(行)的条件
-- 使用**数字**
SELECT product_type, COUNT(*)
FROM product
GROUP BY product_type
HAVING COUNT(*) = 2;---错误原因:product_name不包含在GROUP BY聚合键中
-- 运行结果:Unknown column 'product_type' in 'field list'
SELECT product_type, COUNT(*)
FROM product
GROUP BY product_type
HAVING product_name = '圆珠笔';对查询结果进行排序
ORDER BY
需要按照特定顺序排序使用
SELECT <列名1>, <列名2>, <列名3>, ……
FROM <表名>
ORDER BY <排序基准列1>, <排序基准列2>, ……默认为升序排列ASC,
降序排列为DESC
ORDER BY中列名可使用别名
在ORDER BY中可以使用别名,但是在GROUP BY中不能使用别名,因为执行顺序是:
FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY
相当于当在ORDER BY中使用别名时,已经知道了SELECT设置的别名存在
ORDER BY 排序列中存在 NULL 时,指定其出现在首行或者末行的方式
当顺序为 ASC(升序):`NULL` 值出现在第一位;
当顺序为 DESC(降序)时,`NULL` 值排序在最后;
因此要特殊处理:
将 `NULL` 值排在末行,同时将所有 `非NULL` 值按升序排列
将 `NULL` 值排在首行,同时将所有 `非NULL` 值按倒序排列
`COALESCE` 函数实现
课后习题:
第一部分:
第一题:
SELECT
product_name,
regist_date
FROM product
WHERE regist_date> '2009-04-28';第二题
语法错误:IS NULL 或者IS NOT NULL
所以没有返回结果
第三题:
SELECT sale_price,purchase_price FROM product
WHERE sale_price-purchase_price >500;
SELECT sale_price,purchase_price FROM product
WHERE sale_price>500+purchase_price;第四题:
SELECT product_name,product_type,sale_price*0.9-purchase_price AS profit
FROM product
WHERE sale_price * 0.9-purchase_price > 100
AND(product_type='办公用品' or product_type='厨房用具');第二部分:
第一题:
WHERE 子句写在了 GROUP BY 子句之后
SUM 函数只能作用于数值类型的列
第二题
SELECT product_type,sum(sale_price),sum(purchase_price)
FROM product
GROUP BY product_type
HAVING sum(sale_price)>sum(purchase_price)*1.5;一开始看到条件查询就想用:WHERE,运行了一下报错,想起了WHERE子句只能指定记录(行)的条件,而HAVING子句用于对分组进行过滤
第三题:
select *
from product
order by regist_date desc,product_id;














 698
698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









