






前言
本项目利用爬虫技术和语义分析技术实现了一个微博超级话题情感分析系统,可为一些同学的课设、大作业等提供参考。该项目分为两个部分,先通过爬虫技术将微博超级话题(可指定)下的讨论文本爬取下来,再通过语义分析技术对其进行情感分析。


一、项目环境配置
1.数据库配置
首先创建一个属于该项目的mysql数据库(这里就称它为database1了)。
然后在settings.py文件下配置好数据库信息:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': '', # 数据库名字
'USER':'', # 用户名
'PASSWORD':'', # 密码
'HOST':'',
'PORT':3306,
'OPTIONS': {'charset': 'utf8mb4'},
}
}填写好数据库信心后,在项目的terminal里运行以下两句代码:
python manage.py makemigrations
python manage.py migrate数据迁移就完成啦!
最后在数据库中找到UserAdmin表,填写你自己想设置的账户和密码,在登录系统的时候用得到。
2.环境配置
首先确保你的python根目录下(python.exe所在的文件夹)有与你的Google浏览器版本匹配的chromedriver.exe,可以在这里下载:CNPM Binaries Mirror
再下载好相关依赖即可:
pip install -r requirements.txt3.运行步骤
首先确保weibo_topic_spyder.py文件下的username、password,和analysis.py文件下的APP_ID、API_KEY、SECRET_KEY填写正确:
# weibo_topic_spyder:
def main(keywords):
# 此处输入微博账号及密码
username = ''
password = ''
driver = webdriver.Chrome()
maxWeibo = 100 # 设置最多多少条微博
for keyword in keywords:
spider(username, password, driver, keyword, maxWeibo)# analysis:
# 此处输入baiduAIid
APP_ID = ''
API_KEY = ''
SECRET_KEY = ''最后在项目的terminal里启动程序即可:
python manage.py runserver二、系统运行效果
首先登录系统(三天内登陆过一次,则可免登录):
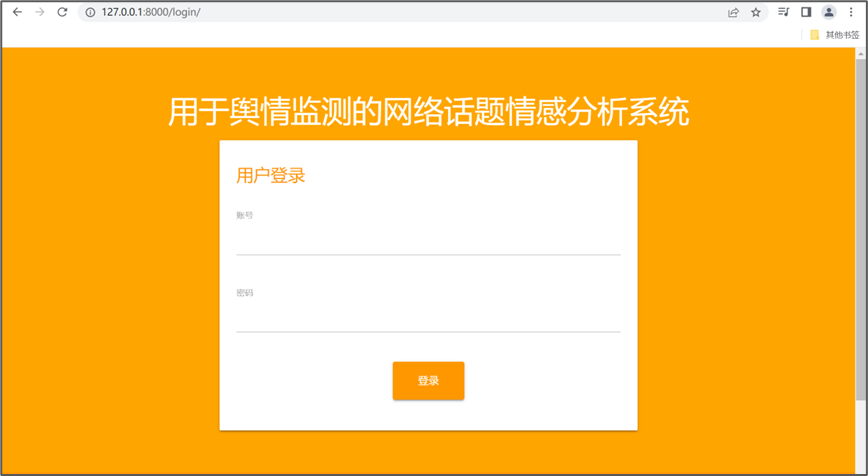
登录成功后进入到系统的首页:
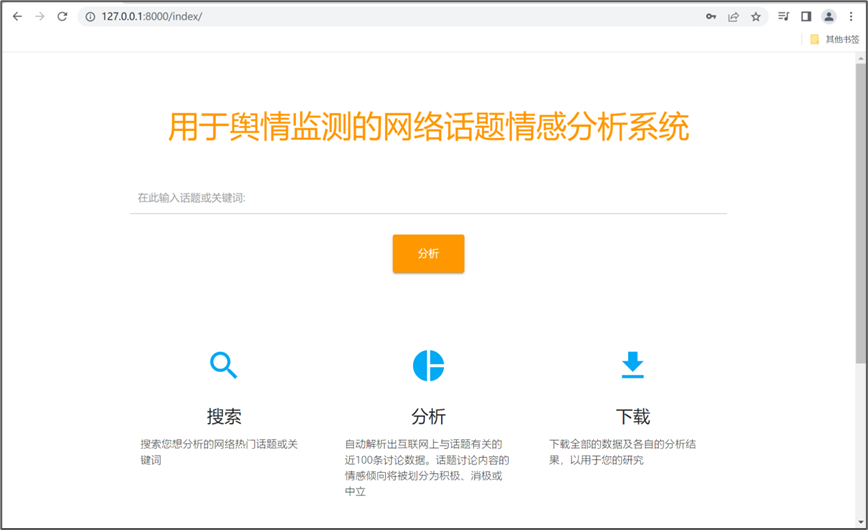
在系统首页输入微博超级话题的名称,点击“分析”即可。
系统会自动爬取话题下的文本数据,并完成分析,呈现如下的分析结果:


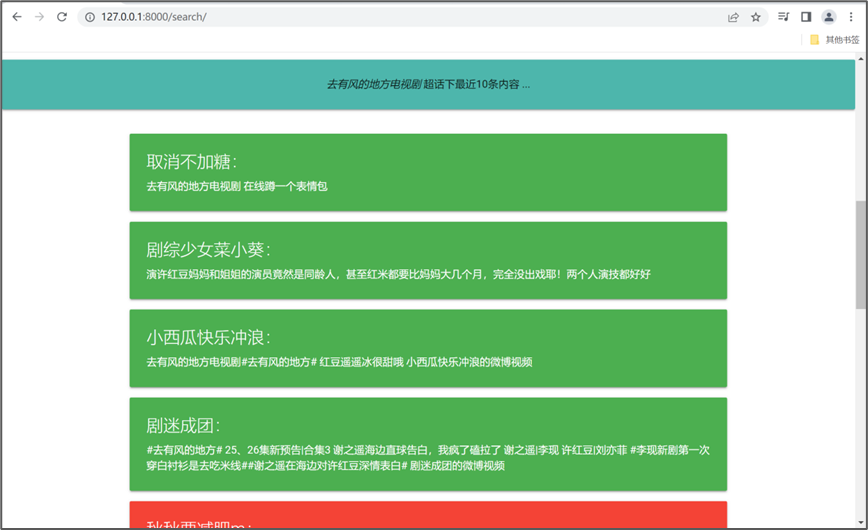

点击“下载”按钮,还可以将分析的数据下载下来:

总结及源代码获取
项目内容:

还包含完整word版本说明文档,可用于写论文、课设报告的参考。
资源获取:
获取整套代码、说明文档(有偿)
------------- -->qq: 1403814258 ---------------













 926
926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









