







目录
今天为大家解析YOLO-Mamba这篇论文开源的代码,首先讲解YOLO格式数据集转换为YOLO-Mamba等特定工具指定的数据集格式的操作。
温馨提示:该帖尚未完全解决,debug部分仅供参考!

克隆Github YOLO-Mamba源码
git clone https://github.com/SwjtuMa/FER-YOLO-Mamba.git
YOLO-Mamba数据集格式
在FER_YOLO_Mamba/data/2007_val.txt中可以看到YOLO-Mamba接受的特定数据集格式
注意:相比源码最高级文件夹,我的文件夹修改为FER_YOLO_Mamba
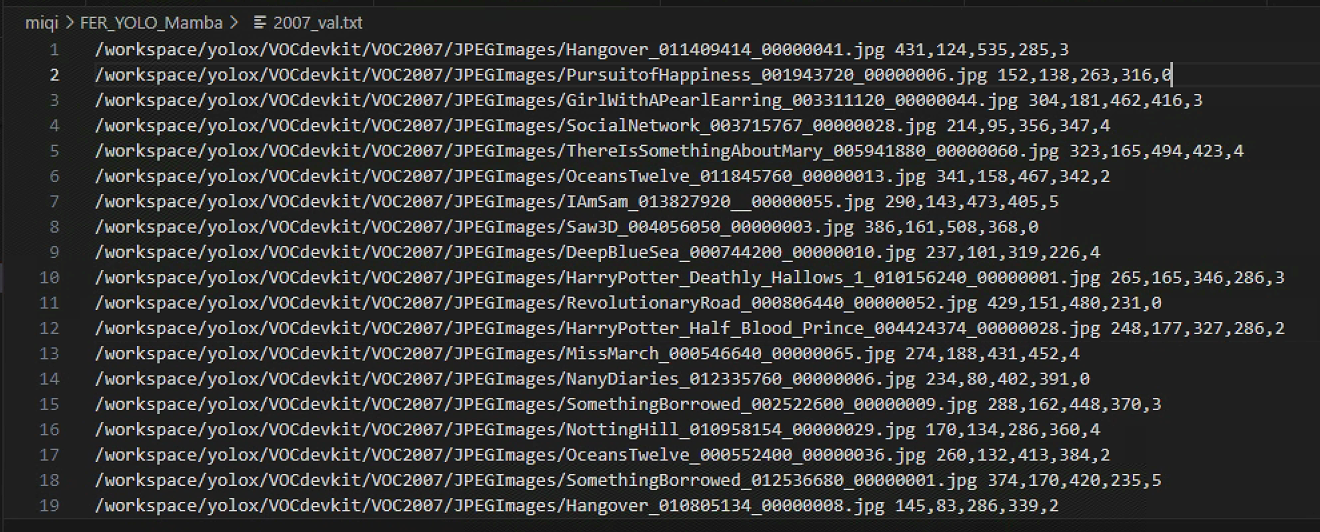
/workspace/yolox/VOCdevkit/VOC2007/JPEGImages/Hangover_011409414_00000041.jpg 431,124,535,285,3
这种指定格式实际上不是标准的YOLO格式,而是更接近Pascal VOC或自定义的文本标注格式。这种格式通常包含图像文件的路径,以及每个目标物体的坐标和类别信息,但表达方式与YOLO格式有所不同。
- 图像路径:每行开始是图像的完整文件路径,例如
/workspace/yolox/VOCdevkit/VOC2007/JPEGImages/...jpg。 - 坐标信息:紧接着是一个由逗号分隔的坐标序列,通常表示目标框的左上角和右下角坐标(而非YOLO格式中的中心坐标和宽高比例)。例如,
431,124,535,285表示一个目标框左上角位于图像坐标(431, 124),右下角位于(535, 285)。 - 类别ID:坐标序列之后是一个整数,表示目标物体的类别ID。例如,
3表示第三个类别。
这种格式与标准YOLO格式的主要区别在于:
- 坐标表示:标准YOLO格式使用边界框的中心点坐标(归一化到图像尺寸的百分比)和宽高比例,而上述格式使用的是绝对像素坐标来直接表示边界框的左上角和右下角。
- 信息排列:YOLO格式每行数据包含一个物体的所有信息(类别ID+中心点坐标+宽高比例),而上述格式首先是图像路径,随后是每个物体的坐标和类别ID,没有直接体现中心点坐标和宽高比例的归一化信息。
这种格式是为了适应例如YOLO-mamba的特定处理流程或工具,比如某些数据集处理脚本或自定义的数据加载器,它不一定遵循YOLO算法的标准输入格式。
下载的公开数据集目录
以下是我从Kaggle官网下载的一个RAF-DB表情识别数据集目录
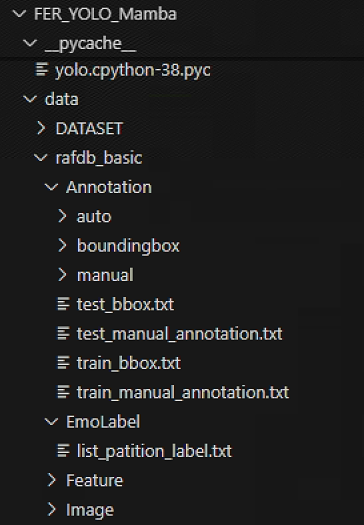
在bbox坐标文件FER_YOLO_Mamba/data/rafdb_basic/Annotation/boundingbox/test_0001_boundingbox.txt中
153.841080 130.382935 327.412231 355.140106
在类别标签文件FER_YOLO_Mamba/data/rafdb_basic/EmoLabel/list_patition_label.txt中
train_12267.jpg 7
train_12268.jpg 7
train_12269.jpg 7
train_12270.jpg 7
train_12271.jpg 7
test_0001.jpg 5
test_0002.jpg 1
test_0003.jpg 4
test_0004.jpg 1
YOLO(You Only Look Once)是一种广泛使用的实时目标检测算法,它的数据标注格式简洁明了,主要用来指示图像中目标物体的位置和类别。在上述例子中,涉及到两个文件:一个是边界框坐标文件,另一个是类别标签文件。下面我将分别解释这两个文件的内容和格式。
边界框坐标文件
在YOLO格式中,每个目标物体的边界框坐标信息通常按照以下格式存储在一个文本文件中,每行代表一个目标物体的信息,具体到上述例子:
153.841080 130.382935 327.412231 355.140106
这四个数字分别代表:
- 第一个和第二个数字是边界框的中心点坐标相对于图像宽度和高度的归一化值。即
x_center, y_center。在这个例子中,中心点坐标为(153.841080, 130.382935),这些值通常范围在0到1之间,表示相对于图像宽度和高度的比例位置。 - 第三个和第四个数字是边界框的宽度和高度相对于图像尺寸的归一化值。即
width, height。这里边界框的宽度为327.412231 - 153.841080,高度为355.140106 - 130.382935的比例,同样也是归一化的。
类别标签文件
这个文件每一行对应一张图像及其对应的类别标签,格式为:
image_filename.jpg category_id
例如:
test_0001.jpg 5
这意味着文件名为 test_0001.jpg 的图像被标记为类别ID为5的情感表情。类别ID是整数,对应于特定的情感分类,如高兴、悲伤、愤怒等。在实际应用中,通常会有一个类别ID与实际情感名称的映射表,以解释每个ID所代表的情感。
结合上述两个文件,可以理解为在图像test_0001.jpg中有一个目标物体,其边界框信息由boundingbox/test_0001_boundingbox.txt文件提供,且该目标物体表达的情感类别为ID为5的情感(具体情感需参照类别ID映射表)。这种格式使得YOLO算法能够直接读取并理解图像中的目标及其类别信息,进而进行目标检测和分类。
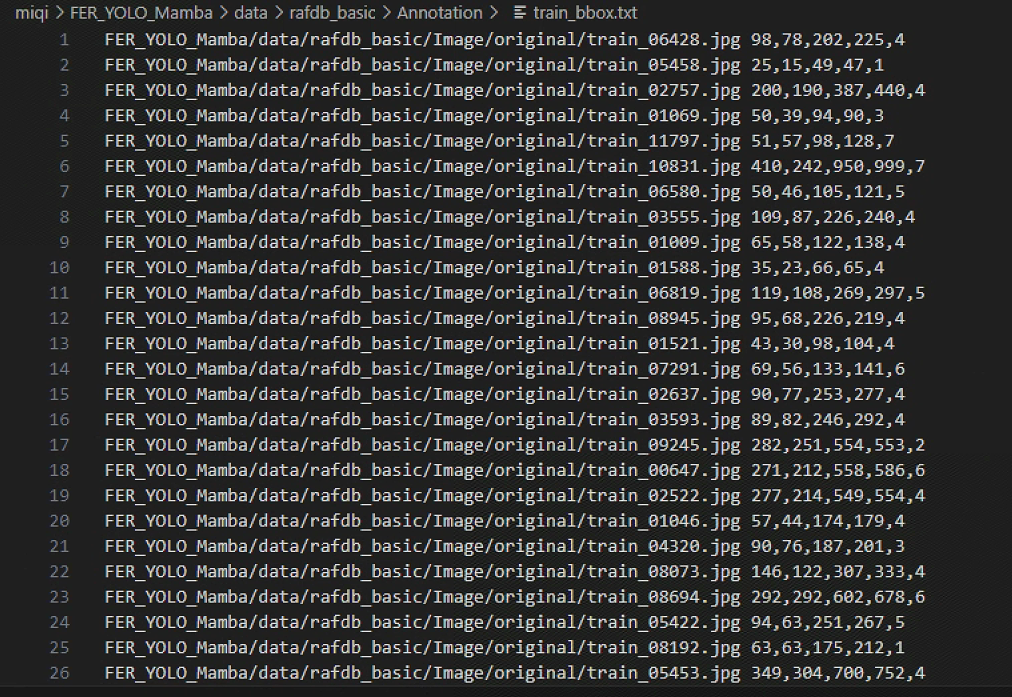
数据集格式转换代码
import os
def load_class_labels(label_file_path):
"""
加载类别标签文件,返回一个字典,键为图像ID,值为类别ID。
"""
labels_dict = {}
with open(label_file_path, 'r') as label_file:
for line in label_file:
img_id, class_id = line.strip().split()
labels_dict[os.path.splitext(img_id)[0]] = int(class_id) # 去除文件扩展名,确保与img_id匹配
return labels_dict
def separate_and_merge_yolo_txts(input_folder, label_file_path, train_output, test_output):
"""
将带有'train_'和'test_'前缀的YOLO格式标签文件分别合并到训练集和测试集的输出文件中,并整合类别标签。
:param input_folder: 包含所有单个txt标签文件的目录
:param label_file_path: 类别标签文件路径
:param train_output: 训练集合并后的输出文件路径
:param test_output: 测试集合并后的输出文件路径
"""
class_labels = load_class_labels(label_file_path)
train_file = open(train_output, 'w')
test_file = open(test_output, 'w')
for txt_file in os.listdir(input_folder):
if txt_file.endswith('.txt'):
img_id = os.path.splitext(os.path.splitext(txt_file)[0])[0].replace("_boundingbox", "")
prefix = img_id.split('_')[0]
txt_path = os.path.join(input_folder, txt_file)
with open(txt_path, 'r') as infile:
# 读取并转换坐标为整数
float_strings = infile.read().split()
int_values = list(map(int, map(float, float_strings)))
str_value = ' '.join(map(str, int_values))
# 获取并添加类别ID
class_id = class_labels.get(img_id)
if class_id is None:
print(f"Warning: No class label found for {img_id}. Skipping.")
continue
# 在写入训练或测试文件的部分修改为逗号分隔坐标
if prefix == 'train':
train_file.write(f"FER_YOLO_Mamba/data/rafdb_basic/Image/original/{img_id}.jpg {int_values[0]},{int_values[1]},{int_values[2]},{int_values[3]},{class_id}\n")
elif prefix == 'test':
test_file.write(f"FER_YOLO_Mamba/data/rafdb_basic/Image/original/{img_id}.jpg {int_values[0]},{int_values[1]},{int_values[2]},{int_values[3]},{class_id}\n")
train_file.close()
test_file.close()
# 使用示例
input_folder = 'FER_YOLO_Mamba/data/rafdb_basic/Annotation/boundingbox'
label_file_path = 'FER_YOLO_Mamba/data/rafdb_basic/EmoLabel/list_patition_label.txt'
train_annotation = 'FER_YOLO_Mamba/data/rafdb_basic/Annotation/train_bbox.txt'
test_annotation = 'FER_YOLO_Mamba/data/rafdb_basic/Annotation/test_bbox.txt'
separate_and_merge_yolo_txts(input_folder, label_file_path, train_annotation, test_annotation)
转换格式的效果展示
配置文件修改过程
第一处报错
报错:
RuntimeError: Given groups=1, weight of size [128, 128, 3, 3], expected input[32, 256, 20, 20] to have 128 channels, but got 256 channels instead
这个运行时错误信息说明了在执行模型时遇到了输入维度与模型层权重维度不匹配的问题。具体解释如下:
-
Given groups=1: 指的是卷积层的分组卷积设置,默认情况下为1,意味着不采用分组卷积,这是一个正常的设置,不是问题所在。 -
weight of size [128, 128, 3, 3]: 表明你的卷积层权重矩阵的尺寸是这样的:输出通道数128,输入通道数128,卷积核的高和宽均为3。这说明这是一个128通道到128通道的卷积操作,卷积核大小为3x3。 -
expected input[32, 256, 20, 20]: 模型期望的输入数据形状是批大小为32,通道数为128,高度为20,宽度也为20。但这里的描述有误,根据错误信息,实际应该是通道数为256,而非128。 -
to have 128 channels, but got 256 channels instead: 这句话直接指出问题所在,模型期望输入数据具有128个通道,但实际上接收到的数据有256个通道。
因此,错误的根本原因是模型中的某个卷积层被设计为接受128通道的输入,而实际传入的数据却是256通道的。要解决这个问题,你可以采取以下措施之一:
-
修改模型定义:如果你的模型设计意图确实是处理256通道的输入,你需要调整该卷积层的输入通道数(即第一个数字)从128改为256,确保其与输入数据匹配。
-
检查数据预处理:确认数据预处理管道没有错误地改变了数据的通道数。虽然通常这不是直接原因,但确保数据在送入模型前处理得当也是重要的。
-
调整输入数据:如果可能,检查并修改数据加载或批处理逻辑,确保数据在送入该层之前正确地调整到预期的通道数。
于是我们需要在模型定义或数据处理阶段做出相应的调整来解决通道数不匹配的问题。修改的FER_YOLO_Mamba/nets/yolo.py代码如下:
修改的代码
class YOLOPAFPN(nn.Module):
def __init__(self, depth = 1.0, width = 1.0, in_features = ("dark3", "dark4", "dark5"), in_channels = [256, 512, 1024], depthwise = False, act = "silu"):
super().__init__()
Conv = DWConv if depthwise else BaseConv
self.backbone = CSPDarknet(depth, width, depthwise = depthwise, act = act)
self.in_features = in_features
self.upsample = nn.Upsample(scale_factor=2, mode="nearest")
norm_layer=nn.LayerNorm
self.lateral_conv0 = BaseConv(int(in_channels[2] * width), int(in_channels[1] * width), 1, 1, act=act)
self.C3_p4 = nn.ModuleList([ConvSSM1(
hidden_dim=int(512),
drop_path=0.,
norm_layer=norm_layer,
attn_drop_rate=0.,
d_state=16,
)])
self.reduce_conv1 = BaseConv(512,256, 1, 1, act=act)
self.C3_p3 = nn.ModuleList([ConvSSM1(
hidden_dim=int(256),
drop_path=0.,
norm_layer=norm_layer,
attn_drop_rate=0.,
d_state=16,
)])
self.bu_conv2 = Conv(256,256, 3, 2, act=act)
self.reduce_conv111 = Conv(256,256, 3, 2, act=act)
self.C3_n3 = nn.ModuleList([ConvSSM1(
hidden_dim=int(256),
drop_path=0.,
norm_layer=norm_layer,
attn_drop_rate=0.,
d_state=16,
)])
self.bu_conv1 = Conv(256,256, 3, 2, act=act)
self.C3_n4 = nn.ModuleList([ConvSSM1(
hidden_dim=int(512),
drop_path=0.,
norm_layer=norm_layer,
attn_drop_rate=0.,
d_state=16,
)])
第二处报错
报错:
RuntimeError: Given normalized_shape=[128], expected input with shape [*, 128], but got input of size[32, 40, 40, 192]
这个错误信息表明你在使用一个归一化层(很可能是LayerNorm或类似的层)时遇到了问题。错误信息的具体含义是:
normalized_shape=[128]:归一化层被配置为处理具有128特征维度的输入。expected input with shape [*, 128]:这意味着归一化层期望输入数据的最后一个维度(特征维度)是128。got input of size [32, 40, 40, 192]:但实际输入数据的形状是批次大小32,高度40,宽度40,特征维度192,与预期不符。
解决这个问题的方法是确保你的归一化层配置与实际输入数据的维度相匹配。具体操作如下:
-
修改归一化层的配置:如果你的模型设计意图是处理特征维度为128的输入,但实际上输入特征维度是192,那么你需要修改归一化层的
normalized_shape参数,将其从128改为192。 -
检查模型结构:如果192才是正确的特征维度,回顾你的模型设计,确保所有依赖于这一特定特征维度的后续层也相应地调整其输入维度设置。
-
数据处理检查:确认数据预处理过程中没有意外地改变了特征维度。尽管这种可能性较小,但确保数据管道中没有错误地增加或减少了特征数量也很重要。
示例代码调整(假设使用的是PyTorch的LayerNorm):
# 假设原始代码为
# norm_layer = nn.LayerNorm(normalized_shape=[128])
# 应调整为
norm_layer = nn.LayerNorm(normalized_shape=[192])
确保在做出调整后,整个模型的其他部分能够适应这个更改,尤其是那些紧接着归一化层之后的层。
修改FER_YOLO_Mamba/nets/yolo.py代码片段如下:
修改的代码
class PatchMerging2D(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, norm_layer=nn.LayerNorm(normalized_shape=[192])):
super().__init__()
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
第三处报错
报错:
RuntimeError: cuDNN error: CUDNN_STATUS_NOT_INITIALIZE
修改FER_YOLO_Mamba/train.py文件中的批大小
修改的代码
if __name__ == "__main__":
Freeze_batch_size = 2
Unfreeze_batch_size = 1
第四处报错
报错:
TypeError: layer_norm(): argument 'input' (position 1) must be Tensor, not int
修改代码
class ConvSSM1(nn.Module):
def __init__(...):
super().__init__()
self.ln_1 = norm_layer(torch.empty(1, hidden_dim//2))
第五处报错
报错:
RuntimeError: GET was unable to find an engine to execute this computation
待解决…
修改过程中的疑问
数据集输入数据的形状是默认的吗?
实际输入数据的形状并不是默认的,而是由你的数据预处理阶段和模型设计共同决定的。在深度学习实践中,你通常需要手动定义或通过预处理步骤来调整输入数据的形状,使其符合模型的输入要求。下面是关于如何修改批次大小、高度、宽度和特征维度的一些建议:
-
批次大小(Batch Size):
批次大小是每次迭代时送入模型进行训练或推断的数据样本数。在PyTorch等框架中,你可以在数据加载器(DataLoader)中设置批次大小。例如:dataloader = DataLoader(dataset, batch_size=32, shuffle=True)这里
batch_size=32指定了每个批次包含32个样本。 -
高度(Height)和宽度(Width):
图像数据的高度和宽度通常在数据预处理阶段调整,比如使用torchvision.transforms.Resize()来改变图像尺寸:transform = transforms.Compose([ transforms.Resize((height, width)), # 例如:(224, 224) transforms.ToTensor(), ... ]) dataset = datasets.ImageFolder(root='your_data_path', transform=transform)这里的
(height, width)就是设定的图像高度和宽度。 -
特征维度(Channels):
特征维度通常由模型的输入层或数据的自然属性决定。如果你在处理图像数据,RGB图像默认有3个通道,灰度图则只有1个通道。若需要调整特征维度以匹配模型,可能需要修改模型的第一层(如卷积层、全连接层或归一化层)的输入通道数。例如,对于一个卷积层:conv_layer = nn.Conv2d(in_channels=original_channels, out_channels=new_channels, kernel_size=3)其中
in_channels需要根据实际数据的特征维度进行设置。
如果模型在运行时抛出错误,指出特征维度不匹配,你需要检查数据的预处理步骤是否正确调整了尺寸,同时也要检查模型定义中是否有不匹配的层定义。修改时务必确保所有修改保持一致,使得数据流向模型时维度能够一一对应。
为什么我没有修改源码的数据预处理步骤,只是换了个数据集会报错?
当你更换数据集后遇到这个错误,RuntimeError: Given normalized_shape=[128], expected input with shape [*, 128], but got input of size[32, 40, 40, 192],这意味着新数据集的特征维度与模型中某一层(可能是Layer Normalization层)的预期不匹配。具体来说,你的模型期望在某一维度上处理128个特征,但新数据集提供了192个特征维度。
这通常发生在以下几种情况:
-
数据集特性不同:新数据集的样本可能在特征上与原数据集不同,比如新的图像数据每张图有更多的通道,或者是经过不同的预处理步骤生成了更多特征。
-
预处理未调整:即使没有手动修改代码,如果新数据集的预处理流程与原数据集不同,也可能导致输入到模型的特征维度发生变化。例如,可能原数据集在预处理时进行了降维,而新数据集没有。
-
模型与数据集不匹配:你的模型可能为特定的数据格式设计,更换数据集后,尤其是当数据集的维度(如通道数)与模型设计不一致时,就会引发错误。
解决方法:
-
调整归一化层设置:检查并调整模型中的归一化层(如LayerNorm),确保
normalized_shape与新数据集的特征维度匹配。如果新数据是192通道,那么应将归一化层的设置更改为normalized_shape=[192]。 -
审查数据预处理:仔细检查新数据集的预处理步骤,确认没有无意中增加了特征维度,或者确保添加了必要的调整步骤以匹配模型的输入要求。
-
修改模型输入层:如果数据集的更改合理且期望长期使用,可能需要重新考虑模型架构,调整输入层以兼容新数据的特征维度。
-
数据适配:考虑是否可以通过修改数据集的处理方式,比如减少通道数或使用特征选择技术,使数据适应原有模型,但这需谨慎考虑,确保不影响任务性能。
简而言之,更换数据集后出现这种错误,主要是因为数据的维度与模型期望不一致,需要通过调整模型或数据处理流程来解决。
为什么同一个数据集的input of size一会是[1, 256],一会又是[32, 40, 40, 192]?
数据集的输入尺寸(input size)之所以在不同情况下显示为 [1, 256] 和 [32, 40, 40, 192],主要是因为它们代表了数据在处理过程中的不同形态和用途,具体解释如下:
-
[1, 256]:这种形状通常表示的是一个一维向量或序列数据,其中
1代表批量大小(batch size)为1,即一次处理一个样本,256表示这个样本有256个特征或时间步长。这种情况常见于单样本输入、特征提取、简单序列分析或调试模型时,其中我们可能只处理单个别的数据以简化计算或测试模型。 -
[32, 40, 40, 192]:这个形状则代表了更高维度的数据结构,通常与图像处理相关。具体来说,
32代表批量大小,即一次性处理32个样本;40, 40, 192分别代表了图像的高和宽,以及通道数(如果是彩色图像,通道数通常是3,灰度图像是1)。在这个例子中,数据似乎是经过某种处理后准备用于卷积神经网络(CNN)的输入,其中40, 40和40是图像的高和宽,192代表通道数,可能是因为进行了某种特征映射操作或者数据增强后通道数增加。
总结来说,尺寸的不同反映了数据处理阶段和目的差异。前者可能是简单的特征分析或模型初步测试,后者则进入了深度学习模型训练的常规流程,特别是在处理图像数据时。数据预处理步骤如增广、批量化、数据集划分、归一化等都会影响最终的输入尺寸。
数据集的normalized_shape无法统一怎么办?
当遇到数据集的normalized_shape无法统一的问题时,意味着在进行数据预处理或模型设计时,不同部分数据的归一化维度不一致,导致了冲突。解决这一问题可以采取以下步骤:
-
明确归一化目标:首先明确数据归一化的目标,是为了让模型训练更稳定、加速收敛,减少过拟合等。确保归一化方法符合模型和任务需求。
-
统一归一化策略:在整个模型中采用一致的归一化策略。例如,如果使用批量归一化(Batch Normalization),确保所有层或模型都使用;如果是层归一化(Layer Normalization),保持维度一致。
-
检查数据处理:检查数据预处理代码,确保所有输入数据的处理逻辑一致,特别是归一化部分。如果数据集来自不同源,处理逻辑需要统一化到相同维度。
-
动态调整:如果数据维度不固定,考虑使用动态归一化方法,例如
nn.BatchNorm可以自动适应数据的通道数。对于自定义层,确保归一化层能够接受变化的输入尺寸。 -
特征调整:对于不同特征,可能需要单独归一化,如图像和文本数据处理方法不同,确保各自归一化方法合适,再融合时考虑特征重要性匹配。
-
数据集对齐:如果可能,重新组织数据集,确保每个样本或批次有相同维度。对于不规则数据,考虑填充、裁剪裁剪切、插值等方法对齐。
-
异常检测:检查数据是否有异常值或错误标签,导致尺寸不一致。清理数据,确保数据质量。
-
定制化归一化层:如果必要,编写或调整归一化层代码,使其能适应不同维度或动态调整
normalized_shape。
通过以上步骤,可以逐步解决数据集归一化不一致问题,确保模型训练稳定高效进行。















 2746
2746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









