







一、介绍
- 窗口函数,也叫OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析处理。
- 窗口函数由开窗函数和分析函数构成,窗口函数就是既要显示聚集前的数据,又要显示聚集后的数据,简单讲,就是你查询的结果上,多出一列值(可以是聚合值或者排序号),所以分析函数可以分为两类:聚合分析函数和排序分析函数
基本语法:
<窗口分析函数> over (partition by <用于分组的字段> order by<用于排序的列名>) 1. 概要
开窗函数就是over()函数,就是限定一个窗口,来显示分析函数的结果
2.开窗函数一般有两种(固定形式,不可更改)
-- 第一种
over(partiton by ... order by ...)
-- 第二种
over(distribute by ... order by ...)
3.区别
- partiton by是一个一个reduce处理数据的,所以使用全局排序order by distribute
- distribute by是多个reduce处理数据的,所以使用局部排序sort by
二、函数
1.排序分析函数
- RANK() OVER();
- ROW_NUMBER() OVER();
- DENSE_RANK() OVER();
- NTILE(n) OVER();
代码如下
创建表
0: jdbc:hive2://192.168.171.151:10000> create table student
. . . . . . . . . . . . . . . . . . > (name string,score int)
. . . . . . . . . . . . . . . . . . > row format delimited fields
. . . . . . . . . . . . . . . . . . > terminated by '\t';
No rows affected (0.877 seconds)创建数据
[root@hadoop l0415]# vim student.txt
张三 100
李四 90
王五 80
刘六 100
田七 70
导入数据
0: jdbc:hive2://192.168.171.151:10000> load data local inpath '/usr/word/l0415/student.txt'
. . . . . . . . . . . . . . . . . . > into table student;
No rows affected (1.533 seconds)
使用RANK() OVER()
特点:并列跳跃排序
0: jdbc:hive2://192.168.171.151:10000> from student
. . . . . . . . . . . . . . . . . . > select name,score,rank()
. . . . . . . . . . . . . . . . . . > over(order by score desc) ranking;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-------+--------+----------+--+
| name | score | ranking |
+-------+--------+----------+--+
| 刘六 | 100 | 1 |
| 张三 | 100 | 1 |
| 李四 | 90 | 3 |
| 王五 | 80 | 4 |
| 田七 | 70 | 5 |
+-------+--------+----------+--+
5 rows selected (33.441 seconds)
特点:并列连续排序
0: jdbc:hive2://192.168.17.151:10000> from student
. . . . . . . . . . . . . . . . . . > select name,score,dense_rank()
. . . . . . . . . . . . . . . . . . > over(order by score desc) ranking;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-------+--------+----------+--+
| name | score | ranking |
+-------+--------+----------+--+
| 刘六 | 100 | 1 |
| 张三 | 100 | 1 |
| 李四 | 90 | 2 |
| 王五 | 80 | 3 |
| 田七 | 70 | 4 |
+-------+--------+----------+--+
5 rows selected (33.399 seconds) 总结
通过上面两个函数,我们发现开窗函数能实现普通函数比较难实现或者无法实现的问题,因为聚合函数只能操作分组的字段,这也是聚合函数最大的特点,窗口函数能够操作所有的字段,不受分组的限制。
ROW_NUMBER() PERCENT_RANK() NTILE() 概述
- ROW_NUMBER()
特点:连续排序 - PERCENT_RANK()
特点:百分比排序
percent_rank() 含义就是
当前行-1 / 当前组总行数-1 - NTILE()
特点:将有序集分桶(bucket)
0: jdbc:hive2://192.168.17.151:10000> from student
. . . . . . . . . . . . . . . . . . > select name,score,
. . . . . . . . . . . . . . . . . . > ntile(3) over(order by score desc) ntres,
. . . . . . . . . . . . . . . . . . > percent_rank() over(order by score desc) prank,
. . . . . . . . . . . . . . . . . . > row_number() over(order by score desc) rownum;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-------+--------+--------+--------+---------+--+
| name | score | ntres | prank | rownum |
+-------+--------+--------+--------+---------+--+
| 刘六 | 100 | 1 | 0.0 | 1 |
| 张三 | 100 | 1 | 0.0 | 2 |
| 李四 | 90 | 2 | 0.5 | 3 |
| 王五 | 80 | 2 | 0.75 | 4 |
| 田七 | 70 | 3 | 1.0 | 5 |
+-------+--------+--------+--------+---------+--+
5 rows selected (32.374 seconds)
2.聚合分析函数
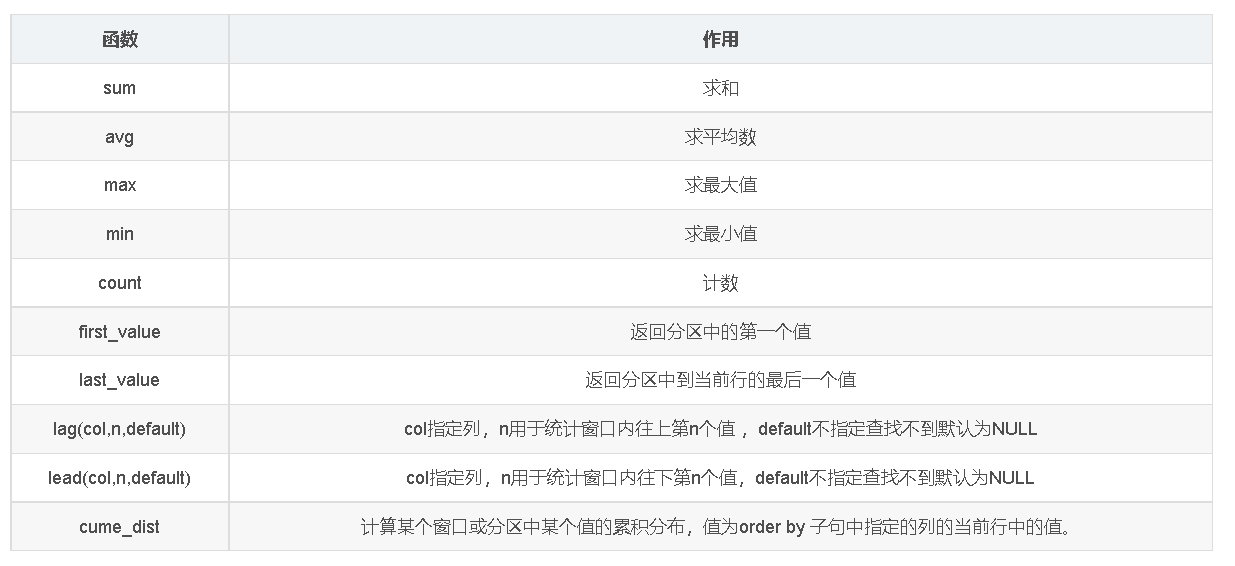
例如:
0: jdbc:hive2://192.168.17.151:10000> from student
. . . . . . . . . . . . . . . . . . > select name,score,
. . . . . . . . . . . . . . . . . . > sum(score) over() sumres,
. . . . . . . . . . . . . . . . . . > count(score) over() cres,
. . . . . . . . . . . . . . . . . . > min(score) over() minres,
. . . . . . . . . . . . . . . . . . > max(score) over() maxres,
. . . . . . . . . . . . . . . . . . > avg(score) over() avgres
. . . . . . . . . . . . . . . . . . > ;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-------+--------+---------+-------+---------+---------+---------+--+
| name | score | sumres | cres | minres | maxres | avgres |
+-------+--------+---------+-------+---------+---------+---------+--+
| 田七 | 70 | 440 | 5 | 70 | 100 | 88.0 |
| 刘六 | 100 | 440 | 5 | 70 | 100 | 88.0 |
| 王五 | 80 | 440 | 5 | 70 | 100 | 88.0 |
| 李四 | 90 | 440 | 5 | 70 | 100 | 88.0 |
| 张三 | 100 | 440 | 5 | 70 | 100 | 88.0 |
+-------+--------+---------+-------+---------+---------+---------+--+
5 rows selected (34.494 seconds)
- 下面的函数的使用是根据over()中的参数变化而变化的
first_value() 函数
- 用法是根据partiton by 的字段进行分区,如果忽略partition by,会根据order by排序后的结果返回第一条数据
- 示例 在每行数据后开窗显示总第一名和每个班的第一名
修改数据,并追加
0: jdbc:hive2://192.168.17.151:10000> drop table student;
No rows affected (0.211 seconds)
0: jdbc:hive2://192.168.17.151:10000>
0: jdbc:hive2://192.168.17.151:10000> create table student
. . . . . . . . . . . . . . . . . . > (name string,score int,class int)
. . . . . . . . . . . . . . . . . . > row format delimited fields
. . . . . . . . . . . . . . . . . . > terminated by '\t';
No rows affected (0.164 seconds)
0: jdbc:hive2://192.168.17.151:10000> load data local inpath '/usr/word/l0415/student.txt'
. . . . . . . . . . . . . . . . . . > into table student;
No rows affected (0.426 seconds)
0: jdbc:hive2://192.168.17.151:10000> select * from student;
+---------------+----------------+----------------+--+
| student.name | student.score | student.class |
+---------------+----------------+----------------+--+
| 张三 | 100 | 1 |
| 李四 | 90 | 2 |
| 王五 | 80 | 3 |
| 刘六 | 100 | 4 |
| 田七 | 70 | 5 |
| 张三五 | 78 | 1 |
| 李四五 | 98 | 2 |
| 王五五 | 85 | 3 |
| 李璐 | 73 | 4 |
| 田七五 | 90 | 5 |
+---------------+----------------+----------------+--+
10 rows selected (0.194 seconds)
[root@hadoop l0415]# cat student.txt
张三 100 1
李四 90 2
王五 80 3
刘六 100 4
田七 70 5
张三五 78 1
李四五 98 2
王五五 85 3
李璐 73 4
田七五 90 5last_value() 函数
- 作用是返回到当前行的最后一条数据
0: jdbc:hive2://192.168.17.151:10000> from student
. . . . . . . . . . . . . . . . . . > select name,score,class,
. . . . . . . . . . . . . . . . . . > last_value(score)
. . . . . . . . . . . . . . . . . . > over(partition by class order by score) lastvalue;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+-------+--------+--------+------------+--+
| name | score | class | lastvalue |
+-------+--------+--------+------------+--+
| 张三五 | 78 | 1 | 78 |
| 张三 | 100 | 1 | 100 |
| 李四 | 90 | 2 | 90 |
| 李四五 | 98 | 2 | 98 |
| 王五 | 80 | 3 | 80 |
| 王五五 | 85 | 3 | 85 |
| 李璐 | 73 | 4 | 73 |
| 刘六 | 100 | 4 | 100 |
| 田七 | 70 | 5 | 70 |
| 田七五 | 90 | 5 | 90 |
+-------+--------+--------+------------+--+
10 rows selected (35.058 seconds)
lag() 函数
- 用法是用于统计分组内的往上前n个值
- 示例1 排名并显示每个同学和上一位同学的分差
0: jdbc:hive2://192.168.17.151:10000> from student
. . . . . . . . . . . . . . . . . . > select *,
. . . . . . . . . . . . . . . . . . > score-lag(score,1,0) over(order by score desc) as gap
. . . . . . . . . . . . . . . . . . > ;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+---------------+----------------+----------------+------+--+
| student.name | student.score | student.class | gap |
+---------------+----------------+----------------+------+--+
| 刘六 | 100 | 4 | 100 |
| 张三 | 100 | 1 | 0 |
| 李四五 | 98 | 2 | -2 |
| 田七五 | 90 | 5 | -8 |
| 李四 | 90 | 2 | 0 |
| 王五五 | 85 | 3 | -5 |
| 王五 | 80 | 3 | -5 |
| 张三五 | 78 | 1 | -2 |
| 李璐 | 73 | 4 | -5 |
| 田七 | 70 | 5 | -3 |
+---------------+----------------+----------------+------+--+
10 rows selected (34.238 seconds)
cume_dist() 函数
- 用法是如果按升序排列,则统计:小于等于当前值的行数/总行数(number of rows ≤ current row)/(total number of rows)。如果是降序排列,则统计:大于等于当前值的行数/总行数。
示例1 统计小于等于当前分数的人数占比
0: jdbc:hive2://192.168.17.151:10000> from student
. . . . . . . . . . . . . . . . . . > select *,
. . . . . . . . . . . . . . . . . . > cume_dist() over(order by score) as cume_dist;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+---------------+----------------+----------------+------------+--+
| student.name | student.score | student.class | cume_dist |
+---------------+----------------+----------------+------------+--+
| 田七 | 70 | 5 | 0.1 |
| 李璐 | 73 | 4 | 0.2 |
| 张三五 | 78 | 1 | 0.3 |
| 王五 | 80 | 3 | 0.4 |
| 王五五 | 85 | 3 | 0.5 |
| 田七五 | 90 | 5 | 0.7 |
| 李四 | 90 | 2 | 0.7 |
| 李四五 | 98 | 2 | 0.8 |
| 刘六 | 100 | 4 | 1.0 |
| 张三 | 100 | 1 | 1.0 |
+---------------+----------------+----------------+------------+--+
10 rows selected (33.34 seconds)- 示例2 统计每个班小于等于当前分数的人数占比
0: jdbc:hive2://192.168.17.151:10000> from student
. . . . . . . . . . . . . . . . . . > select *,
. . . . . . . . . . . . . . . . . . > cume_dist() over(partition by class order by score) as cume_dist;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
+---------------+----------------+----------------+------------+--+
| student.name | student.score | student.class | cume_dist |
+---------------+----------------+----------------+------------+--+
| 张三五 | 78 | 1 | 0.5 |
| 张三 | 100 | 1 | 1.0 |
| 李四 | 90 | 2 | 0.5 |
| 李四五 | 98 | 2 | 1.0 |
| 王五 | 80 | 3 | 0.5 |
| 王五五 | 85 | 3 | 1.0 |
| 李璐 | 73 | 4 | 0.5 |
| 刘六 | 100 | 4 | 1.0 |
| 田七 | 70 | 5 | 0.5 |
| 田七五 | 90 | 5 | 1.0 |
+---------------+----------------+----------------+------------+--+
10 rows selected (34.501 seconds)
















 224
224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











