




由于内容较多,分篇进行解读,此为第一篇。
第二篇:【论文解读】Denoising Diffusion Probabilistic Models(DDPM)——Diffusion模型奠基之作(内含大量推导)【二】-CSDN博客
第三篇:【论文解读】Denoising Diffusion Probabilistic Models(DDPM)——Diffusion模型奠基之作(内含大量推导)【三】-CSDN博客
第四篇:【论文解读】Denoising Diffusion Probabilistic Models(DDPM)——Diffusion模型奠基之作(内含大量推导)【四】-CSDN博客
第五篇:【论文解读】Denoising Diffusion Probabilistic Models(DDPM)——Diffusion模型奠基之作(内含大量推导)【五】-CSDN博客
概览
扩散概率模型(diffusion probabilistic models),简称扩散模型(diffusion model),是一个马尔可夫链,包括前向过程和反向过程,前向过程是有具体的表达式可以计算的,后向过程是利用神经网络来学习的。前向过程,即扩散过程,就是不断地对图像添加高斯噪声,直到图像完全被高斯噪声淹没,如下图中的 q ( x t ∣ x t − 1 ) q(\mathbf{x}_t|\mathbf{x}_{t−1}) q(xt∣xt−1)。而反向过程,即去噪过程,就是逐渐去除噪声生成图片的过程,如下图中的 p θ ( x t − 1 ∣ x t ) p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t) pθ(xt−1∣xt)。
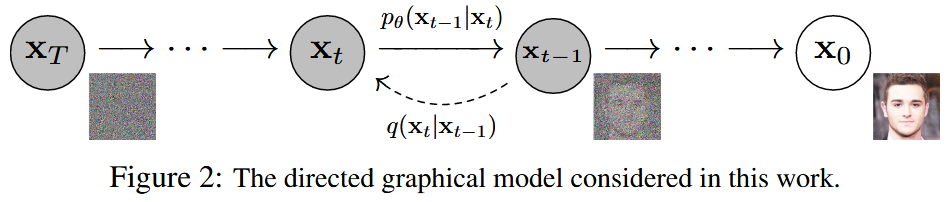
这里结合两篇论文来看,分别是:
-
Deep Unsupervised Learning using Nonequilibrium Thermodynamics:这篇论文受非平衡统计物理学启发,首先提出了扩散概率模型。
-
Denoising Diffusion Probabilistic Models:这篇文章是将 diffusion model 用于图像生成领域的关键论文。
一、背景
首先给出概念:扩散模型是一种潜变量模型(latent variable model),即这类模型假设我们观察到的数据( x 0 \mathbf{x}_0 x0)是由一些未观察到的、隐藏的变量(即潜变量 x 1 , … , x T \mathbf{x}_1, \dots, \mathbf{x}_T x1,…,xT)生成的。
下面介绍扩散模型相关背景,本部结合论文1、2一起来看。
(一)前向过程
假设 x 0 \mathbf{x}_0 x0 是原始的、未经处理的数据(例如,一张清晰的图片),下标 0 代表时间步 t = 0 t=0 t=0。 q ( x 0 ) q(\mathbf{x}_0) q(x0) 是初始数据的分布。通过重复应用一个马尔可夫扩散核 T π ( y ∣ y ′ ; β ) T_\pi(\mathbf{y}|\mathbf{y}'; \beta) Tπ(y∣y′;β),原始数据分布被逐渐转化为一个性质良好(解析上易于处理)的分布 π ( y ) \pi(\mathbf{y}) π(y),其中 β \beta β 是扩散速率。
- 这个 π ( y ) \pi(\mathbf{y}) π(y) 就是前向过程的目标分布。通常,这个目标分布是一个非常简单的、我们熟知的分布,比如标准正态分布(高斯噪声)。“性质良好”或“解析上易于处理”意味着我们可以很容易地从这个分布中采样,或者计算它的概率密度。
- T π ( y ∣ y ′ ; β ) T_\pi(\mathbf{y}|\mathbf{y}'; \beta) Tπ(y∣y′;β) 指的是一个转移概率函数,它定义了从一个状态 y ′ \mathbf{y}' y′ 转换到另一个状态 y \mathbf{y} y 的概率。这个转换过程具有马尔可夫性质,即下一个状态 y \mathbf{y} y 只依赖于当前状态 y ′ \mathbf{y}' y′,而与更早之前的状态无关。 T π ( y ∣ y ′ ; β ) T_\pi(\mathbf{y}|\mathbf{y}'; \beta) Tπ(y∣y′;β) 这个核函数描述了单步扩散,即给定当前状态 y ′ \mathbf{y}' y′,它会以一定的概率(由 β \beta β 控制)将其“扩散”成 y \mathbf{y} y。下标 π \pi π 表示这个核是设计用来最终趋向于 π ( y ) \pi(\mathbf{y}) π(y) 分布的。
可以写出如下公式:
π
(
y
)
=
∫
T
π
(
y
∣
y
′
;
β
)
π
(
y
′
)
d
y
′
q
(
x
t
∣
x
t
−
1
)
=
T
π
(
x
t
∣
x
t
−
1
;
β
t
)
\begin{align} &\pi(\mathbf{y}) = \int T_\pi(\mathbf{y}|\mathbf{y}'; \beta) \pi(\mathbf{y}') d\mathbf{y}' \\ &q(\mathbf{x}_{t}|\mathbf{x}_{t-1}) = T_\pi(\mathbf{x}_{t}|\mathbf{x}_{t-1}; \beta_t) \end{align}
π(y)=∫Tπ(y∣y′;β)π(y′)dy′q(xt∣xt−1)=Tπ(xt∣xt−1;βt)
因此,从初始数据开始,执行
T
T
T 次扩散的前向过程由下式给出:
q
(
x
0
:
T
)
=
q
(
x
0
)
q
(
x
1
∣
x
0
)
q
(
x
2
∣
x
0
x
1
)
…
q
(
x
T
∣
x
0
:
T
−
1
)
(
概率乘法公式
)
=
q
(
x
0
)
q
(
x
1
∣
x
0
)
q
(
x
2
∣
x
1
)
…
q
(
x
T
∣
x
T
−
1
)
(
马尔科夫性质
)
=
q
(
x
0
)
∏
t
=
1
T
q
(
x
t
∣
x
t
−
1
)
\begin{equation} \begin{aligned} q(\mathbf{x}_{0:T}) &= q(\mathbf{x}_{0}) q(\mathbf{x}_{1}|\mathbf{x}_{0}) q(\mathbf{x}_{2}|\mathbf{x}_{0}\mathbf{x}_{1}) \dots q(\mathbf{x}_{T}|\mathbf{x}_{0:T-1}) &(\text{概率乘法公式}) \\ & = q(\mathbf{x}_{0}) q(\mathbf{x}_{1}|\mathbf{x}_{0}) q(\mathbf{x}_{2}|\mathbf{x}_{1}) \dots q(\mathbf{x}_{T}|\mathbf{x}_{T-1}) &(\text{马尔科夫性质}) \\ &= q(\mathbf{x}_{0}) \prod_{t=1}^T q(\mathbf{x}_{t}|\mathbf{x}_{t-1}) \end{aligned} \end{equation}
q(x0:T)=q(x0)q(x1∣x0)q(x2∣x0x1)…q(xT∣x0:T−1)=q(x0)q(x1∣x0)q(x2∣x1)…q(xT∣xT−1)=q(x0)t=1∏Tq(xt∣xt−1)(概率乘法公式)(马尔科夫性质)
其中,
q
(
x
t
∣
x
t
−
1
)
q(\mathbf{x}_{t}|\mathbf{x}_{t-1})
q(xt∣xt−1)(即单步前向转移概率)要么对应于向具有单位协方差的高斯分布进行高斯扩散,要么对应于向一个独立的二项分布进行二项扩散。前者适用于连续数据,后者适用于离散数据。
多元高斯分布的一般形式:
设随机向量 X = [ X 1 , X 2 , … , X n ] T \mathbf{X} = [X_1, X_2, \dots, X_n]^T X=[X1,X2,…,Xn]T 服从 n n n 维高斯分布,记为 X ∼ N ( μ , Σ ) \mathbf{X} \sim \mathcal{N}(\boldsymbol{\mu}, \boldsymbol{\Sigma}) X∼N(μ,Σ),其中:
- μ \boldsymbol{\mu} μ 是均值向量(各变量的期望值);
- Σ \boldsymbol{\Sigma} Σ 是 n × n n \times n n×n 的协方差矩阵,对角线元素 Σ i i = Var ( X i ) \Sigma_{ii} = \text{Var}(X_i) Σii=Var(Xi) 为各变量的方差,非对角线元素 Σ i j = Cov ( X i , X j ) \Sigma_{ij} = \text{Cov}(X_i, X_j) Σij=Cov(Xi,Xj) 为变量间的协方差。
单位协方差的含义:若协方差矩阵 Σ = I \boldsymbol{\Sigma} = \mathbf{I} Σ=I(单位矩阵),则每个变量的方差为 1 ( Var ( X i ) = 1 \text{Var}(X_i) = 1 Var(Xi)=1),且任意两个变量之间的协方差为 0 ( Cov ( X i , X j ) = 0 \text{Cov}(X_i, X_j) = 0 Cov(Xi,Xj)=0, i ≠ j i \neq j i=j)。此时变量间相互独立且标准化,分布称为标准多元高斯分布。
根据条件概率分布:
q
(
x
0
:
T
)
=
q
(
x
0
)
q
(
x
1
:
T
∣
x
0
)
\begin{equation} q(\mathbf{x}_{0:T}) = q(\mathbf{x}_{0})q(\mathbf{x}_{1:T}|\mathbf{x}_{0}) \end{equation}
q(x0:T)=q(x0)q(x1:T∣x0)
扩散模型与其他潜变量模型的区别在于,其后验概率
q
(
x
1
:
T
∣
x
0
)
q(\mathbf{x}_{1:T}|\mathbf{x}_{0})
q(x1:T∣x0),即前向过程或扩散过程,被固定为一个马尔科夫链,根据方差调度
β
1
,
…
β
T
\beta_1, \dots \beta_T
β1,…βT,逐次向数据中添加高斯噪声。根据前面的公式,可知:
q
(
x
1
:
T
∣
x
0
)
=
∏
t
=
1
T
q
(
x
t
∣
x
t
−
1
)
\begin{equation} \boxed{ q(\mathbf{x}_{1:T}|\mathbf{x}_{0}) = \prod_{t=1}^T q(\mathbf{x}_{t}|\mathbf{x}_{t-1}) } \end{equation}
q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)
其单步转移概率是人为设计的,论文2中定义为:
q
(
x
t
∣
x
t
−
1
)
:
=
N
(
x
t
;
1
−
β
t
x
t
−
1
,
β
t
I
)
\begin{equation} \boxed{ q(\mathbf{x}_t|\mathbf{x}_{t-1}) := \mathcal{N}(\mathbf{x}_t; \sqrt{1-\beta_t}\mathbf{x}_{t-1}, \beta_t\mathbf{I}) } \end{equation}
q(xt∣xt−1):=N(xt;1−βtxt−1,βtI)
它是关于
x
t
\mathbf{x}_t
xt 的高斯分布,其均值为
1
−
β
t
x
t
−
1
\sqrt{1-\beta_t}\mathbf{x}_{t-1}
1−βtxt−1,方差为
β
t
I
\beta_t\mathbf{I}
βtI。
(二)反向过程
反向过程需要训练一个生成分布 (The generative distribution),即模型学习到的用于生成数据的概率分布,通常用
p
θ
p_\theta
pθ(其中
θ
\theta
θ 代表模型参数)来表示。其目标是学习一个从纯噪声
x
T
\mathbf{x}_{T}
xT 出发,逐步去噪,最终生成数据
x
0
\mathbf{x}_{0}
x0 的过程,它同样是一个马尔科夫链:
p
(
x
T
)
=
π
(
x
T
)
\begin{equation} p(\mathbf{x}_{T})= \pi(\mathbf{x}_{T}) \end{equation}
p(xT)=π(xT)
p
θ
(
x
0
:
T
)
=
p
(
x
T
)
∏
t
=
1
T
p
θ
(
x
t
−
1
∣
x
t
)
\begin{equation} \boxed{ p_\theta(\mathbf{x}_{0:T}) = p(\mathbf{x}_{T}) \prod_{t=1}^T p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_{t}) } \end{equation}
pθ(x0:T)=p(xT)t=1∏Tpθ(xt−1∣xt)
p ( x T ) p(\mathbf{x}_{T}) p(xT) 表示反向生成模型在时刻 T T T 的分布(注意这里 p ( x T ) p(\mathbf{x}_{T}) p(xT) 没有下标 θ \theta θ,因为它通常是 π ( x T ) \pi(\mathbf{x}_{T}) π(xT))。 π ( x T ) \pi(\mathbf{x}_{T}) π(xT) 是前向过程在 T T T 步后达到的目标(通常是简单的、已知的)噪声分布,比如标准正态分布 N ( 0 , I ) \mathcal{N}(\mathbf{0}, \mathbf{I}) N(0,I)。反向生成过程从前向过程最终到达的那个已知的噪声分布开始,这是连接前向过程和反向过程的桥梁。因此, p ( x T ) = N ( x T ; 0 , I ) p(\mathbf{x}_T) = \mathcal{N}(\mathbf{x}_T; \mathbf{0}, \mathbf{I}) p(xT)=N(xT;0,I)。 p θ ( x t − 1 ∣ x t ) p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_{t}) pθ(xt−1∣xt) 是反向过程的核心,表示给定时刻 t t t 的状态 x t \mathbf{x}_{t} xt,生成(或去噪得到)时刻 t − 1 t-1 t−1 的状态 x t − 1 \mathbf{x}_{t-1} xt−1 的条件概率,这些是模型需要学习的部分。
根据 Feller 等人的研究,对于高斯扩散和二项扩散,在连续扩散(即步长 β \beta β 很小的极限情况)下,扩散过程的逆过程与前向过程具有相同的函数形式。因此,由于 q ( x t ∣ x t − 1 ) q(\mathbf{x}_{t}|\mathbf{x}_{t-1}) q(xt∣xt−1) 是一个高斯(或二项)分布,并且如果 β t \beta_t βt 很小,那么 q ( x t − 1 ∣ x t ) q(\mathbf{x}_{t-1}|\mathbf{x}_{t}) q(xt−1∣xt) 也将是一个高斯(或二项)分布(注意,这里只是相同的分布,但并分布的参数也相同)。轨迹越长,扩散率 β \beta β 就可以设置得越小。这为我们选择反向过程中 p θ ( x t − 1 ∣ x t ) p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_{t}) pθ(xt−1∣xt) 的函数形式提供了理论基础。
在学习过程中,对于高斯扩散核,只需要估计其均值和协方差;对于二项核,只需要估计其比特翻转概率。因此,如果反向转移 p θ ( x t − 1 ∣ x t ) p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_{t}) pθ(xt−1∣xt) 被建模为高斯分布,那么模型需要学习预测这个高斯分布的均值和协方差。 f μ ( x t , t ) f_\mu(\mathbf{x}_{t}, t) fμ(xt,t) 和 f Σ ( x t , t ) f_\Sigma(\mathbf{x}_{t}, t) fΣ(xt,t) 是为高斯情况定义反向马尔可夫转移的均值和协方差的函数,而 f b ( x t , t ) f_b(\mathbf{x}_{t}, t) fb(xt,t) 是为二项分布提供比特翻转概率的函数。这里引入了具体的函数 f μ , f Σ , f b f_\mu, f_\Sigma, f_b fμ,fΣ,fb 来参数化反向过程的转移概率,通常是神经网络。它们都以当前状态 x t \mathbf{x}_{t} xt 和当前时间步 t t t 作为输入。 f μ ( x t , t ) f_\mu(\mathbf{x}_{t}, t) fμ(xt,t): 预测高斯转移的均值 μ ( x t , t ) \mu(\mathbf{x}_{t}, t) μ(xt,t)。 f Σ ( x t , t ) f_\Sigma(\mathbf{x}_{t}, t) fΣ(xt,t): 预测高斯转移的协方差 Σ ( x t , t ) \Sigma(\mathbf{x}_{t}, t) Σ(xt,t)。 f b ( x t , t ) f_b(\mathbf{x}_{t}, t) fb(xt,t): 预测二项分布的比特翻转概率。因此,运行此算法的计算成本是这些函数的成本乘以时间步数。在论文1的所有结果中,都使用多层感知机(MLP)来定义这些函数。
在论文2中,给出反向过程的单步转移概率分布为:
p
θ
(
x
t
−
1
∣
x
t
)
:
=
N
(
x
t
−
1
;
μ
θ
(
x
t
,
t
)
,
Σ
θ
(
x
t
,
t
)
)
\begin{equation} \boxed{ p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_t) := \mathcal{N}(\mathbf{x}_{t-1}; \mu_{\theta}(\mathbf{x}_t, t), \Sigma_{\theta}(\mathbf{x}_t, t)) } \end{equation}
pθ(xt−1∣xt):=N(xt−1;μθ(xt,t),Σθ(xt,t))
即转移概率分布函数为关于
x
t
−
1
\mathbf{x}_{t-1}
xt−1 的高斯分布,其均值
μ
θ
(
x
t
,
t
)
\mu_{\theta}(\mathbf{x}_t, t)
μθ(xt,t) 和协方差
Σ
θ
(
x
t
,
t
)
)
\Sigma_{\theta}(\mathbf{x}_t, t))
Σθ(xt,t)) 是关于
x
t
,
t
\mathbf{x}_t, t
xt,t 的函数,它们是由模型学习得到的。
(三)模型概率
生成模型赋予观测数据
x
0
\mathbf{x}_0
x0的预测概率为(要计算边缘概率密度,就是对联合概率密度的其他所有随机变量求积分):
p
θ
(
x
0
)
=
∫
p
θ
(
x
0
:
T
)
d
x
1
:
T
\begin{equation} p_\theta(\mathbf{x}_{0}) = \int p_\theta(\mathbf{x}_{0:T}) d\mathbf{x}_{1:T} \end{equation}
pθ(x0)=∫pθ(x0:T)dx1:T
其中,
p
θ
(
x
0
:
T
)
p_\theta(\mathbf{x}_{0:T})
pθ(x0:T) 表示整个反向(生成)轨迹
(
x
0
,
x
1
,
…
,
x
T
)
(\mathbf{x}_{0}, \mathbf{x}_{1}, \dots, \mathbf{x}_{T})
(x0,x1,…,xT) 的联合概率。它描述了从噪声
x
T
\mathbf{x}_{T}
xT 一路生成到数据
x
0
\mathbf{x}_{0}
x0 的完整路径的概率。
∫
d
x
1
:
T
\int d\mathbf{x}_{1:T}
∫dx1:T 表示对所有可能的中间潜变量(即轨迹
x
1
,
…
,
x
T
\mathbf{x}_{1}, \dots, \mathbf{x}_{T}
x1,…,xT)进行积分。即,要得到模型赋予特定数据
x
0
\mathbf{x}_{0}
x0 的概率,我们需要考虑所有可能生成该
x
0
\mathbf{x}_{0}
x0 的潜变量路径
(
x
1
,
…
,
x
T
)
(\mathbf{x}_{1}, \dots, \mathbf{x}_{T})
(x1,…,xT),并将这些路径的联合概率
p
θ
(
x
0
:
T
)
p_\theta(\mathbf{x}_{0:T})
pθ(x0:T) 积分起来。
直接计算这个积分通常是不可行的,但是借鉴退火重要性采样(annealed importance sampling)和 Jarzynski 等式的思想,可以转而评估前向和反向轨迹的相对概率,并在前向轨迹上取平均:
p
θ
(
x
0
)
=
∫
p
θ
(
x
0
:
T
)
q
(
x
1
:
T
∣
x
0
)
q
(
x
1
:
T
∣
x
0
)
d
x
1
:
T
=
∫
q
(
x
1
:
T
∣
x
0
)
p
θ
(
x
0
:
T
)
q
(
x
1
:
T
∣
x
0
)
d
x
1
:
T
=
∫
q
(
x
1
:
T
∣
x
0
)
⋅
p
(
x
T
)
∏
t
=
1
T
p
θ
(
x
t
−
1
∣
x
t
)
q
(
x
t
∣
x
t
−
1
)
d
x
1
:
T
\begin{align} p_\theta(\mathbf{x}_{0}) &= \int p_\theta(\mathbf{x}_{0:T}) \frac{q(\mathbf{x}_{1:T}|\mathbf{x}_{0})}{q(\mathbf{x}_{1:T}|\mathbf{x}_{0})} d\mathbf{x}_{1:T} \\ &= \int q(\mathbf{x}_{1:T}|\mathbf{x}_{0}) \frac{p_\theta(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T}|\mathbf{x}_{0})} d\mathbf{x}_{1:T} \\ &= \int q(\mathbf{x}_{1:T}|\mathbf{x}_{0}) \cdot p(\mathbf{x}_{T}) \prod_{t=1}^T \frac{p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_{t})}{q(\mathbf{x}_{t}|\mathbf{x}_{t-1})} d\mathbf{x}_{1:T} \end{align}
pθ(x0)=∫pθ(x0:T)q(x1:T∣x0)q(x1:T∣x0)dx1:T=∫q(x1:T∣x0)q(x1:T∣x0)pθ(x0:T)dx1:T=∫q(x1:T∣x0)⋅p(xT)t=1∏Tq(xt∣xt−1)pθ(xt−1∣xt)dx1:T
这里的核心思想是重要性采样 (importance sampling)。我们不直接从难以采样的
p
θ
(
x
0
:
T
)
p_\theta(\mathbf{x}_{0:T})
pθ(x0:T) 中采样,而是从一个更容易采样的提议分布 (proposal distribution) 中采样,并用一个权重来修正。在这里,前向过程
q
q
q 扮演了提议分布的角色。上式首先在被积函数中乘以并除以同一个量
q
(
x
1
:
T
∣
x
0
)
q(\mathbf{x}_{1:T}|\mathbf{x}_{0})
q(x1:T∣x0)。这个量是给定真实数据
x
0
\mathbf{x}_{0}
x0 时,前向(加噪)过程产生特定潜变量轨迹
(
x
1
,
…
,
x
T
)
(\mathbf{x}_{1}, \dots, \mathbf{x}_{T})
(x1,…,xT) 的概率。现在,在公式
(
12
)
(12)
(12)中,积分可以被看作是关于分布
q
(
x
1
:
T
∣
x
0
)
q(\mathbf{x}_{1:T}|\mathbf{x}_{0})
q(x1:T∣x0) 求期望。即:
p
θ
(
x
0
)
=
E
x
1
:
T
∼
q
(
x
1
:
T
∣
x
0
)
[
p
θ
(
x
0
:
T
)
q
(
x
1
:
T
∣
x
0
)
]
=
E
x
1
:
T
∼
q
(
x
1
:
T
∣
x
0
)
[
p
(
x
T
)
∏
t
=
1
T
p
θ
(
x
t
−
1
∣
x
t
)
q
(
x
t
∣
x
t
−
1
)
]
p_\theta(\mathbf{x}_{0}) = \mathbb{E}_{\mathbf{x}_{1:T} \sim q(\mathbf{x}_{1:T}|\mathbf{x}_{0})} \left[ \frac{p_\theta(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T}|\mathbf{x}_{0})} \right] = \mathbb{E}_{\mathbf{x}_{1:T} \sim q(\mathbf{x}_{1:T}|\mathbf{x}_{0})} \left[ p(\mathbf{x}_{T}) \prod_{t=1}^T \frac{p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_{t})}{q(\mathbf{x}_{t}|\mathbf{x}_{t-1})} \right]
pθ(x0)=Ex1:T∼q(x1:T∣x0)[q(x1:T∣x0)pθ(x0:T)]=Ex1:T∼q(x1:T∣x0)[p(xT)t=1∏Tq(xt∣xt−1)pθ(xt−1∣xt)]
其中
p
θ
(
x
0
:
T
)
q
(
x
1
:
T
∣
x
0
)
\frac{p_\theta(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T}|\mathbf{x}_{0})}
q(x1:T∣x0)pθ(x0:T) 即为重要性权重 (importance weight)。上式可以通过从前向过程
q
(
x
1
:
T
∣
x
0
)
q(\mathbf{x}_{1:T}|\mathbf{x}_{0})
q(x1:T∣x0) 中抽取的样本进行平均来快速评估。这是蒙特卡洛估计 (Monte Carlo estimation) 的标准做法。由于直接计算这个期望(即积分)是困难的,我们可以通过以下步骤来近似它:
- 从已知的、固定的前向过程 q ( x 1 : T ∣ x 0 ) q(\mathbf{x}_{1:T}|\mathbf{x}_{0}) q(x1:T∣x0) 中抽取多条轨迹,即潜变量序列 ( x 1 , … , x T ) (\mathbf{x}_{1}, \dots, \mathbf{x}_{T}) (x1,…,xT) 。给定一个 x 0 \mathbf{x}_{0} x0,这是可以做到的,因为前向过程是预先定义好的。
- 对于每一条抽取的轨迹,计算重要性权重项: W = p ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) q ( x t ∣ x t − 1 ) W = p(\mathbf{x}_{T}) \prod_{t=1}^T \frac{p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_{t})}{q(\mathbf{x}_{t}|\mathbf{x}_{t-1})} W=p(xT)∏t=1Tq(xt∣xt−1)pθ(xt−1∣xt)。
- 将所有抽取样本计算得到的权重 W W W 进行平均。这个平均值就是对 p θ ( x 0 ) p_\theta(\mathbf{x}_{0}) pθ(x0) 的一个估计。训练的过程就是通过优化神经网络,使这个估计更准确。
其中:
- 对于 p ( x T ) p(\mathbf{x}_{T}) p(xT):直接使用预设的简单分布(如标准高斯)来计算其在 x T \mathbf{x}_{T} xT 点的概率密度。
- 对于 p θ ( x t − 1 ∣ x t ) p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_{t}) pθ(xt−1∣xt):将当前状态 x t \mathbf{x}_{t} xt 和时间步 t t t 输入到已训练(或正在训练)的神经网络中,得到定义该条件概率分布的参数(如高斯分布的均值和方差),然后计算 p θ ( x t − 1 ∣ x t ) p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_{t}) pθ(xt−1∣xt) 的值。
(四)训练目标
训练的目标是最大化模型的对数似然。这是大多数生成模型的标准训练原则,即最大似然估计 (Maximum Likelihood Estimation, MLE)。我们希望调整模型的参数,使得模型赋予真实观测数据
x
0
\mathbf{x}_0
x0 的概率
p
θ
(
x
0
)
p_\theta(\mathbf{x}_{0})
pθ(x0) 尽可能大,也就是其对数
log
p
θ
(
x
0
)
\log p_\theta(\mathbf{x}_{0})
logpθ(x0) 尽可能大。
L
′
=
∫
q
(
x
0
)
log
p
θ
(
x
0
)
d
x
0
=
∫
q
(
x
0
)
⋅
log
[
∫
q
(
x
1
:
T
∣
x
0
)
⋅
p
(
x
T
)
∏
t
=
1
T
p
θ
(
x
t
−
1
∣
x
t
)
q
(
x
t
∣
x
t
−
1
)
d
x
1
:
T
]
d
x
0
\begin{align} L' &= \int q(\mathbf{x}_{0}) \log p_\theta(\mathbf{x}_{0}) d\mathbf{x}_{0} \\ &= \int q(\mathbf{x}_{0}) \cdot \log \left[ \int q(\mathbf{x}_{1:T}|\mathbf{x}_{0}) \cdot p(\mathbf{x}_{T}) \prod_{t=1}^T \frac{p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_{t})}{q(\mathbf{x}_{t}|\mathbf{x}_{t-1})} d\mathbf{x}_{1:T} \right] d\mathbf{x}_{0} \end{align}
L′=∫q(x0)logpθ(x0)dx0=∫q(x0)⋅log[∫q(x1:T∣x0)⋅p(xT)t=1∏Tq(xt∣xt−1)pθ(xt−1∣xt)dx1:T]dx0
L
′
L'
L′ 代表了希望最大化的目标函数,即在真实数据分布
q
(
x
0
)
q(\mathbf{x}_{0})
q(x0) 下,模型对数似然
log
p
θ
(
x
0
)
\log p_\theta(\mathbf{x}_{0})
logpθ(x0) 的期望值。它可以通过琴生不等式(Jensen’s inequality) 得到一个下界。琴生不等式:对于上凸函数
f
(
x
)
f(x)
f(x),比如
log
(
x
)
\log (x)
log(x),有
E
[
f
(
X
)
]
≤
f
(
E
[
X
]
)
\mathbb{E}[f(X)] \leq f(\mathbb{E}[X])
E[f(X)]≤f(E[X])。在上述公式中,
log
\log
log 函数作用于一个期望(积分)之外。我们可以将
log
\log
log 函数移到期望(积分)内部,从而得到一个下界:
log
E
x
1
:
T
∼
q
(
x
1
:
T
∣
x
0
)
[
W
]
≥
E
x
1
:
T
∼
q
(
x
1
:
T
∣
x
0
)
[
log
W
]
\log \mathbb{E}_{\mathbf{x}_{1:T} \sim q(\mathbf{x}_{1:T}|\mathbf{x}_{0})}[W] \geq \mathbb{E}_{\mathbf{x}_{1:T} \sim q(\mathbf{x}_{1:T}|\mathbf{x}_{0})}[\log W]
logEx1:T∼q(x1:T∣x0)[W]≥Ex1:T∼q(x1:T∣x0)[logW] 其中
W
=
p
(
x
T
)
∏
t
=
1
T
p
θ
(
x
t
−
1
∣
x
t
)
q
(
x
t
∣
x
t
−
1
)
W = p(\mathbf{x}_{T}) \prod_{t=1}^T \frac{p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_{t})}{q(\mathbf{x}_{t}|\mathbf{x}_{t-1})}
W=p(xT)∏t=1Tq(xt∣xt−1)pθ(xt−1∣xt) 是重要性权重。因此得到:
L
′
≥
∫
q
(
x
0
)
⋅
[
∫
q
(
x
1
:
T
∣
x
0
)
⋅
log
(
p
(
x
T
)
∏
t
=
1
T
p
θ
(
x
t
−
1
∣
x
t
)
q
(
x
t
∣
x
t
−
1
)
)
d
x
1
:
T
]
d
x
0
=
∫
[
∫
q
(
x
0
)
⋅
q
(
x
1
:
T
∣
x
0
)
⋅
log
(
p
(
x
T
)
∏
t
=
1
T
p
θ
(
x
t
−
1
∣
x
t
)
q
(
x
t
∣
x
t
−
1
)
)
d
x
1
:
T
]
d
x
0
=
∫
q
(
x
0
:
T
)
⋅
log
[
p
(
x
T
)
∏
t
=
1
T
p
θ
(
x
t
−
1
∣
x
t
)
q
(
x
t
∣
x
t
−
1
)
]
d
x
0
:
T
=
E
x
0
:
T
∼
q
(
x
0
:
T
)
[
log
W
]
\begin{align} L' &\geq \int q(\mathbf{x}_{0}) \cdot \left[ \int q(\mathbf{x}_{1:T}|\mathbf{x}_{0}) \cdot \log \left( p(\mathbf{x}_{T}) \prod_{t=1}^T \frac{p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_{t})}{q(\mathbf{x}_{t}|\mathbf{x}_{t-1})} \right) d\mathbf{x}_{1:T} \right] d\mathbf{x}_{0} \\ & = \int \left[ \int q(\mathbf{x}_{0}) \cdot q(\mathbf{x}_{1:T}|\mathbf{x}_{0}) \cdot \log \left( p(\mathbf{x}_{T}) \prod_{t=1}^T \frac{p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_{t})}{q(\mathbf{x}_{t}|\mathbf{x}_{t-1})} \right) d\mathbf{x}_{1:T} \right] d\mathbf{x}_{0} \\ &= \int q(\mathbf{x}_{0:T}) \cdot \log \left[ p(\mathbf{x}_{T}) \prod_{t=1}^T \frac{p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_{t})}{q(\mathbf{x}_{t}|\mathbf{x}_{t-1})} \right] d\mathbf{x}_{0:T} \\ &= \mathbb{E}_{\mathbf{x}_{0:T} \sim q(\mathbf{x}_{0:T})}[\log W] \end{align}
L′≥∫q(x0)⋅[∫q(x1:T∣x0)⋅log(p(xT)t=1∏Tq(xt∣xt−1)pθ(xt−1∣xt))dx1:T]dx0=∫[∫q(x0)⋅q(x1:T∣x0)⋅log(p(xT)t=1∏Tq(xt∣xt−1)pθ(xt−1∣xt))dx1:T]dx0=∫q(x0:T)⋅log[p(xT)t=1∏Tq(xt∣xt−1)pθ(xt−1∣xt)]dx0:T=Ex0:T∼q(x0:T)[logW]
即下界是就是
E
x
0
:
T
∼
q
(
x
0
:
T
)
[
log
W
]
\mathbb{E}_{\mathbf{x}_{0:T} \sim q(\mathbf{x}_{0:T})}[\log W]
Ex0:T∼q(x0:T)[logW],以上推导是论文1中的形式。
论文2中则写成了负对数似然和期望的形式,优化目标是最小化
L
=
−
L
′
L = -L'
L=−L′。由于直接优化对数似然通常很困难,所以我们转而优化它的一个界限——具体来说是证据下界 (Evidence Lower Bound, ELBO)。最大化ELBO等价于最小化负的ELBO。具体来说,首先将论文1中的
L
′
L'
L′ 添加负号,并写为期望的形式:
L
=
−
L
′
=
−
∫
q
(
x
0
)
log
p
θ
(
x
0
)
d
x
0
=
E
x
0
∼
q
(
x
0
)
[
−
log
p
θ
(
x
0
)
]
\begin{equation} L = -L' = -\int q(\mathbf{x}_{0}) \log p_\theta(\mathbf{x}_{0}) d\mathbf{x}_{0} = \mathbb{E}_{\mathbf{x}_0 \sim q(\mathbf{x}_0)}[-\log p_{\theta}(\mathbf{x}_0)] \end{equation}
L=−L′=−∫q(x0)logpθ(x0)dx0=Ex0∼q(x0)[−logpθ(x0)]
上面我们已经证明过,在论文1需要最大化
L
′
L'
L′ 的情况下,有:
L
′
≥
E
x
0
:
T
∼
q
(
x
0
:
T
)
[
log
W
]
\begin{equation} L' \geq \mathbb{E}_{\mathbf{x}_{0:T} \sim q(\mathbf{x}_{0:T})}[\log W] \end{equation}
L′≥Ex0:T∼q(x0:T)[logW]
因此,有:
L
=
E
x
0
∼
q
(
x
0
)
[
−
log
p
θ
(
x
0
)
]
≤
E
x
0
:
T
∼
q
(
x
0
:
T
)
[
−
log
W
]
=
E
x
0
:
T
∼
q
(
x
0
:
T
)
[
−
log
(
p
(
x
T
)
∏
t
=
1
T
p
θ
(
x
t
−
1
∣
x
t
)
q
(
x
t
∣
x
t
−
1
)
)
]
=
E
x
0
:
T
∼
q
(
x
0
:
T
)
[
−
log
p
(
x
T
)
−
∑
t
≥
1
log
p
θ
(
x
t
−
1
∣
x
t
)
q
(
x
t
∣
x
t
−
1
)
]
\begin{equation} \begin{aligned} L = \mathbb{E}_{\mathbf{x}_0 \sim q(\mathbf{x}_0)}[-\log p_{\theta}(\mathbf{x}_0)] &\leq \mathbb{E}_{\mathbf{x}_{0:T} \sim q(\mathbf{x}_{0:T})}[-\log W] \\ &= \mathbb{E}_{\mathbf{x}_{0:T} \sim q(\mathbf{x}_{0:T})}\left[-\log \left(p(\mathbf{x}_{T}) \prod_{t=1}^T \frac{p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_{t})}{q(\mathbf{x}_{t}|\mathbf{x}_{t-1})}\right)\right] \\ &= \mathbb{E}_{\mathbf{x}_{0:T} \sim q(\mathbf{x}_{0:T})} \left[-\log p(\mathbf{x}_T) - \sum_{t \geq 1} \log \frac{p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_t)}{q(\mathbf{x}_t|\mathbf{x}_{t-1})}\right] \end{aligned} \end{equation}
L=Ex0∼q(x0)[−logpθ(x0)]≤Ex0:T∼q(x0:T)[−logW]=Ex0:T∼q(x0:T)[−log(p(xT)t=1∏Tq(xt∣xt−1)pθ(xt−1∣xt))]=Ex0:T∼q(x0:T)[−logp(xT)−t≥1∑logq(xt∣xt−1)pθ(xt−1∣xt)]
以上就是论文2中的公式
(
3
)
(3)
(3)。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









