







本篇文章主要介绍了三种查找算法:顺序查找,折半查找和分块查找。
首先编写seqlist.cpp程序。
#include<stdio.h>
#include<malloc.h>
#define MAX 100//顺序表的最大长度
typedef int keytype;//定义关键字类型为int
typedef char infotype;
typedef struct
{
keytype key;//关键字项
infotype data;//其他数据项,类型为infotype
}rectype;//声明查找顺序表元素类型
void createlist(rectype r[],keytype keys[],int n)//建立顺序表
{
for (int i=0;i<n;i++)//r[0……n-1]存放排序记录
r[i].key=keys[i];
}
void displist(rectype r[],int n)//输出顺序表
{ for(int i=0;i<n;i++)
printf("%d",r[i].key);
printf("\n");
}
方法一:顺序查找
解决问题:在顺序表(3,6,2,10,1,8,5,7,4,9)中查找关键字5。
#include"seqlist.cpp"
int seqsearch(rectype r[],int n,keytype k)//顺序查找算法
{
int i=0;
while(i<n&&r[i].key!=k)//从表头向后查找
{
printf("%d",r[i].key);
i++;
}
if(i>=n)return 0;
else
{
printf("%d",r[i].key);
return i+1;
}
}
int main(){
rectype r[MAX];
int n=10,i;
keytype k=5;
int a[]={3,6,2,10,1,8,5,7,4,9};
createlist(r,a,n);
printf("查找%d所比较的关键字:\n",k);
if((i=seqsearch(r,n,k))!=0)
printf("\n元素%d的位置是%d\n",k,i);
else
printf("\n元素%d不在表中\n",k);
return 1;
}运行结果: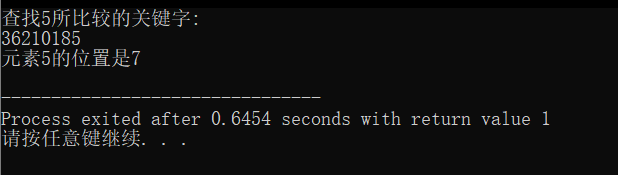
算法分析:
1.假设表元素为n,成功时平均查找长度为
=
=
,不超过时平均查找长度为n。
2.算法较为简单,效率低,当n大时不适用。
方法二:折半查找
(也称二分查找,要求线性表有序)
解决问题:在顺序表(1,2,3,4,5,6,7,8,9,10)中查找关键字9
#include"seqlist.cpp"
int binsearch(rectype r[],int n,keytype k)//折半查找
{
int low=0,high=n-1,mid,count=0;
while(low<=high)
{
mid=(low+high)/2;
printf("第%d次比较:在[%d,%d]中比较元素r[%d]:%d\n",++count,low,high,mid,r[mid].key);
if(r[mid].key==k)//查找成功返回
return mid+1;
if(r[mid].key>k)//继续在r[low...mid-1]中查找
high=mid-1;
else
low=mid+1;//继续在r[mid+1...high]中查找
}
return 0;
}
int main(){
rectype r[MAX];
int n=10,i;
keytype k=9;
int a[]={1,2,3,4,5,6,7,8,9,10};
createlist(r,a,n);
printf("查找%d所比较的关键字:\n",k);
if((i=binsearch(r,n,k))!=0)
printf("元素%d的位置是%d\n",k,i);
else
printf("\n元素%d不在表中\n",k);
return 1;
}运行结果:

算法分析:
1.平均查找长度由折半查找判定树得为。
2.效率高,但要求表按关键字有序,适用于顺序表,不太适用于链式存储结构。
方法三:分块查找
(每一块中关键字不一定有序,前一块中最大关键字必须小于后一块中最小关键字,抽取各块中最大关键字和起始位置构成索引表,在递增有序索引表中折半查找,在块中顺序查找)
解决问题:在顺序表(14,8,6,9,10,22,34,18,19,31,40,38,54,66,46,71,78,68,80,85,100,94,88,96,87 )中查找关键字(举例:80和46)
#include"seqlist.cpp"
typedef struct
{
keytype key;//keytype为关键字的类型
int link;//指向对应块的起始下标
}idxtype;//索引表元素的类型
int idxsearch(idxtype a[],int b,rectype r[],int n,keytype k)//分块查找
{
int s=(n+b-1)/b;//s为每块的元素个数,应为n/b取上界 ,b为块数
int count1=0,count2=0;
int low=0,high=b-1,mid,i;
printf("(1)在索引表中折半查找\n");
while(low<=high)//在索引表中折半查找,找到的块位置为high+1
{
mid=(low+high)/2;
printf("第%d次比较:在[%d,%d]中比较元素a[%d]:%d\n",count1+1,low,high,mid,a[mid].key);
if(a[mid].key>=k)high=mid-1;
else low=mid+1;
count1++; //count1累计在索引表中的比较次数
}
printf("比较%d次,在第%d块中查找元素%d\n",count1,low,k);//应在索引表的high+1块中,再在主数据表中进行数据查找
i=a[high+1].link;//找到对应的块
printf("(2)在对应块中顺序查找:\n");
while(i<=a[high+1].link+s-1)
{
printf("%4d",r[i].key);
count2++;//累计在顺序表对应块中的比较次数
if(r[i].key==k)break;
i++;
}
printf("比较%d次,在顺序表中查找元素%d\n",count2,k);
if(i<=a[high+1].link+s-1)
return i+1;//查找成功,返回该元素的逻辑序号
else
return 0;//查找失败,返回0
}
int main(){
rectype r[MAX];
idxtype a[MAX];
int n=25,i;
int b[]={14,8,6,9,10,22,34,18,19,31,40,38,54,66,46,71,78,68,80,85,100,94,88,96,87};
createlist(r,b,n);
printf("关键字序列:\n");
for(i=0;i<n;i++)
{
printf("%4d",r[i].key);
if(((i+1)%5)==0)printf(" ");
if(((i+1)%10)==0)printf("\n");
}
a[0].key=14;a[0].link=0;//a[].key为每块中数值最大的元素,索引表有序
a[1].key=34;a[1].link=4;
a[2].key=66;a[2].link=10;
a[3].key=85;a[3].link=15;
a[4].key=100;a[4].link=20;
printf("\n");
keytype k=80;
printf("查找%d的比较过程如下:\n",k);
if((i=idxsearch(a,5,r,25,k))!=-1)//
printf("元素%d的位置是%d\n",k,i);
else
printf("元素%d不在表中\n",k);
return 1;
} 运行结果:


算法分析:
1.以折半查找来确定块,成功时平均查找长度为,其中b=
,即
向上取整,取不小于
的最小整数。
2.效率高,但要求表按关键字有序,适用于顺序表,不太适用于链式存储结构。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









