




 本文通过PyTorch实现了一个基于LSTM的AI诗歌生成模型,详细介绍了数据预处理、模型构建、训练过程以及生成效果。模型以唐诗为训练集,使用字符级别的语言模型,通过1层词嵌入层和2层LSTM预测下一个字符,利用交叉熵损失函数进行优化。生成的诗歌初步展现了古诗韵味。
本文通过PyTorch实现了一个基于LSTM的AI诗歌生成模型,详细介绍了数据预处理、模型构建、训练过程以及生成效果。模型以唐诗为训练集,使用字符级别的语言模型,通过1层词嵌入层和2层LSTM预测下一个字符,利用交叉熵损失函数进行优化。生成的诗歌初步展现了古诗韵味。
本模型采用的是字符级别的诗歌生成(pytorch)
环境:
python3.X
pytorch GPU或CPU版本都行,
另外天有点冷,建议用GPU训练,电脑绝对比暖手宝好用
目录
项目文件结构:
data:存放预处理好的数据
model:存放训练好的模型
config.py:配置文件
dataHandler.py:数据预处理及生成词典
model.py:模型文件
train.py:训练模型
generation.py:生成诗歌
poetry.txt:全唐诗,四万多首,中华民族艺术瑰宝。
数据已经打包:
链接:https://pan.baidu.com/s/1UAJFf3kKERm_XR0qRNneig
提取码:e3y5
1、数据集处理
以四万首唐诗的文本作为训练集
它长这样:
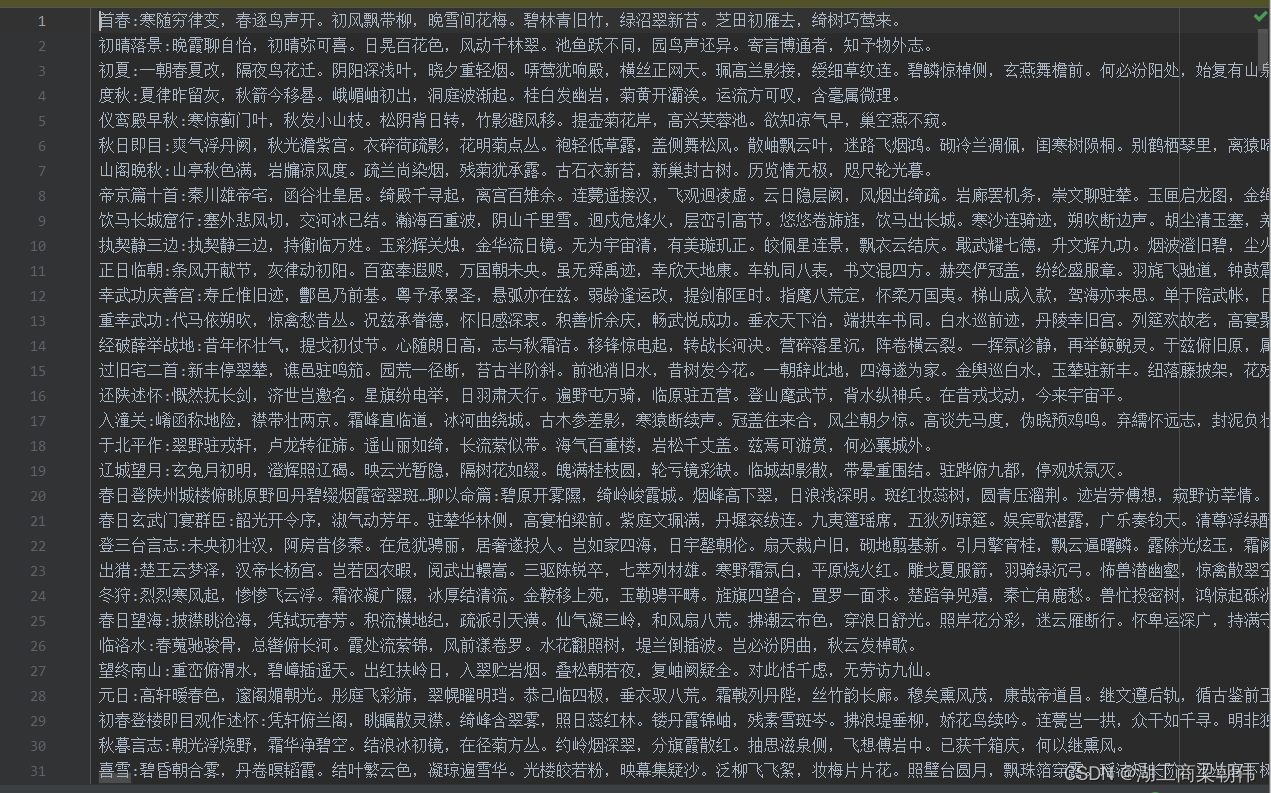
文本中每行是一首诗,且使用冒号分割,前面是标题,后面是正文,且诗的长度不一。
对数据的处理流程大致:
- 读取文本,按行切分,构成古诗列表。
- 将全角、半角的冒号统一替换成半角的。
- 按冒号切分诗的标题和内容,只保留诗的内容。
- 最后根据诗的内容构建词典,并将处理好的数据保
处理后的诗歌大概长这样
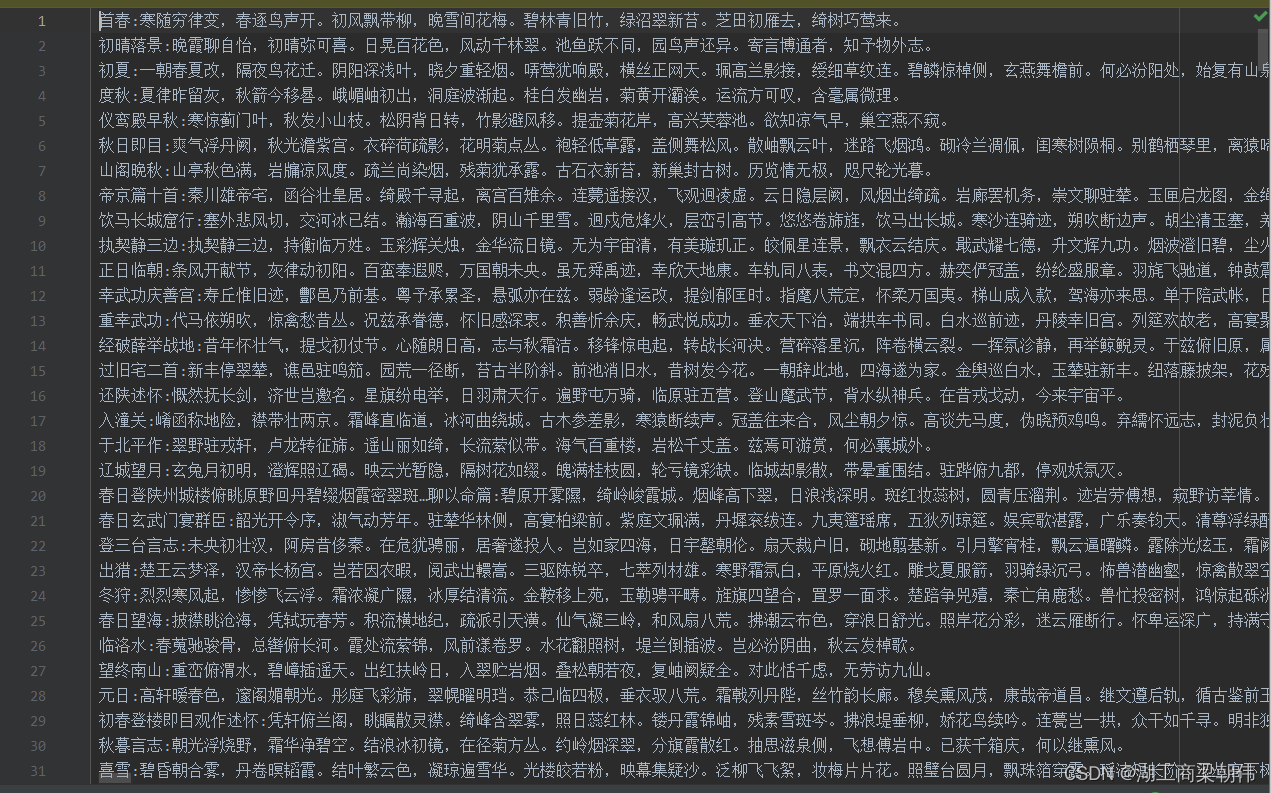
代码如下:
# dataHandler.py
import numpy as np
from config import Config
def pad_sequences(sequences,
maxlen=None,
dtype='int32',
padding='pre',
truncating='pre',
value=0.):
"""
# 填充
code from keras
Pads each sequence to the same length (length of the longest sequence).
If maxlen is provided, any sequence longer
than maxlen is truncated to maxlen.
Truncation happens off either the beginning (default) or
the end of the sequence.
Supports post-padding and pre-padding (default).
Arguments:
sequences: list of lists where each element is a sequence
maxlen: int, maximum length
dtype: type to cast the resulting sequence.
padding: 'pre' or 'post', pad either before or after each sequence.
truncating: 'pre' or 'post', remove values from sequences larger than
maxlen either in the beginning or in the end of the sequence
value: float, value to pad the sequences to the desired value.
Returns:
x: numpy array with dimensions (number_of_sequences, maxlen)
Raises:
ValueError: in case of invalid values for `truncating` or `padding`,
or in case of invalid shape for a `sequences` entry.
"""
if not hasattr(sequences, '__len__'):
raise ValueError('`sequences` must be iterable.')
lengths = []
for x in sequences:
if not hasattr(x, '__len__'):
raise ValueError('`sequences` must be a list of iterables. '
'Found non-iterable: ' + str(x))
lengths.append(len(x))
num_samples = len(sequences)
if maxlen is None:
maxlen = np.max(lengths)
# take the sample shape from the first non empty sequence
# checking for consistency in the main loop below.
sample_shape = tuple()
for s in sequences:
if len(s) > 0: # pylint: disable=g-explicit-length-test
sample_shape = np.asarray(s).shape[1:]
break
x = (np.ones((num_samples, maxlen) + sample_shape) * value).astype(dtype)
for idx, s in enumerate(sequences):
if not len(s): # pylint: disable=g-explicit-length-test
continue # empty list/array was found
if truncating == 'pre':
trunc = s[-maxlen:] # pylint: disable=invalid-unary-operand-type
elif truncating == 'post':
trunc = s[:maxlen]
else:
raise ValueError('Truncating type "%s" not understood' % truncating)
# check `trunc` has expected shape
trunc = np.asarray(trunc, dtype=dtype)
if trunc.shape[1:] != sample_shape:
raise ValueError(
'Shape of sample %s of sequence at position %s is different from '
'expected shape %s'
% (trunc.shape[1:], idx, sample_shape))
if padding == 'post':
x[idx, :len(trunc)] = trunc
elif padding == 'pre':
x[idx, -len(trunc):] = trunc
else:
raise ValueError('Padding type "%s" not understood' % padding)
return x
def load_poetry(poetry_file, max_gen_len):
# 加载数据集
with open(poetry_file, 'r', encoding='utf-8') as f:
lines = f.readlines()
# 将冒号统一成相同格式
lines = [line.replace(':', ':') for line in lines]
# 数据集列表
poetry = []
# 逐行处理读取到的数据
for line in lines:
# 有且只能有一个冒号用来分割标题
if line.count(':') != 1:
continue
#  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2016
2016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









