






生产者消费者模型是一个经典的多线程并发协作模型。
生产者:产生数据的模块
消费者:处理数据的模块
缓冲区:数据缓冲区
系统中有一组生产者进程和一组消费者进程,生产者每次生产一个产品放入缓冲区,消费者每次取出一个产品使用掉。生产者和消费者共享一个初始为空大小固定的缓冲区。因此:
只有缓冲区未满时,生产者才能将产品放入缓冲区,否则必须等待;
只有缓冲区不空时,消费者才能从缓冲区取出产品,否则必须等待。
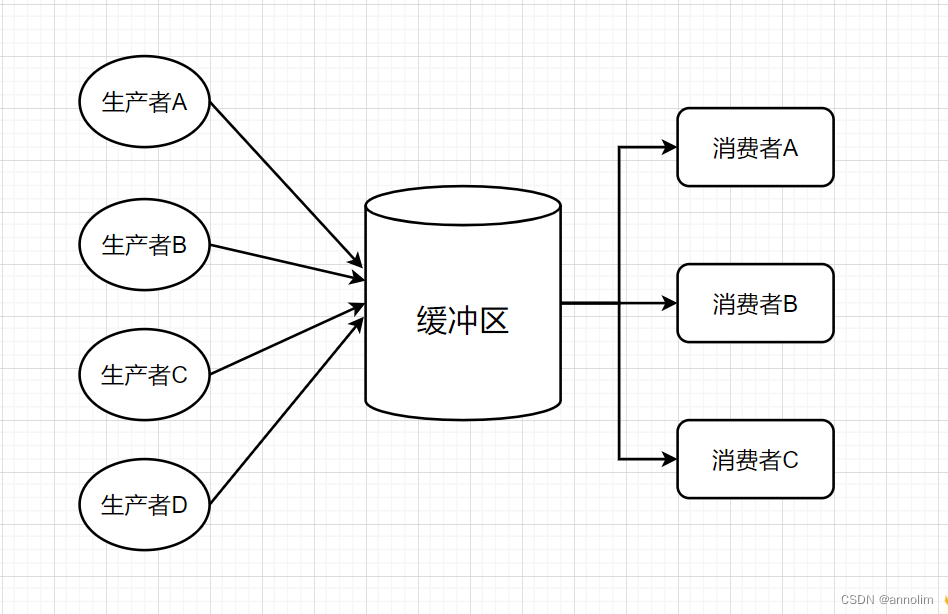
生产者消费者模型能够降低生产者和消费者之间的依赖关系,通过增加一个缓存区的方式,将生产者和消费者变成两个独立的并发主体,互不干扰的运行。
生产者模块产生的数据可以直接存放到缓冲区内等待消费者模块调用,将数据块放入缓冲区后可以继续生产而不需要等待消费者处理;
消费者模块可以不用寻找具体的生产者而是直接到缓冲区去调用数据去使用;
同时不论是生产者还是消费者同一时间对缓冲区的访问只有一个,即各进程必须互斥地访问,从而避免数据同时进行读写发生的错误。
通过使用生产者消费者模型,能够提高系统的并发性和资源利用率,同时避免了数据竞争和死锁等并发编程中常见的问题。从生产者消费者衍生的吸烟者问题、读者写者问题、哲学家进餐问题都是用于处理解决多线程或多进程之间的数据共享和同步问题。















 254
254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









