







中间件的使用
限制同一IP访问次数
1.获取远程客户端的IP地址
request.META[‘REMOTE_ADDR’]
2.得到客户端访问的请求路由信息
request.path_info
创建一个中间件
class VisitLimit(MiddlewareMixin):
visit_times = {}
def process_request(self, request):# 应该在执行路由之前就要调用,确保其IP的访问次数未超标
ip_address = request.META['REMOTE_ADDR']# 湖区I{
path_url = request.path_info# 获取访问的URL
if not re.match('^/text', path_url):# 判断URL是否为/text开头,若不是,就返回None,继续执行请求
return
times = self.visit_times.get(ip_address, 0)# 计算访问次数,在字典中存储其访问次数
print('ip' + str(ip_address) + '已经访问了' + str(times))
if times > 5:# 当请求次数大于5时,就禁止访问了,直接返回一个HttpResponse对象,无法继续正常的请求
return HttpResponse("当前{}已经访问了".format(ip_address) + str(self.visit_times[ip_address]) + '次,已经禁止访问了')
self.visit_times[ip_address] = times + 1# 访问了一次就进行加1
csrf恶意攻击
CSRF(Cross-site request forgery),中文名称:跨站请求伪造,也被称为:one click attack/session riding,缩写为:CSRF/XSRF。
CSRF攻击:攻击者盗用了你的身份,以你的名义发送恶意请求。CSRF能够做的事情包括:以你名义发送邮件,发消息,盗取你的账号,甚至于购买商品,虚拟货币转账…造成的问题包括:个人隐私泄露以及财产安全。
如何避免
1.在settings中将中间件中的django.middleware.csrf.CsrfViewMiddleware打开
2.然后再页面的源代码中的form表单中添加{% csrf_token %},即可
将中间件打开,向路由发送post请求就会报403错误
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试</title>
</head>
<body>
<form action="/text_csrf" method="POST">
{% csrf_token %}
<input type="text" name="username">
<input type="submit" value="提交">
</form>
</body>
</html>
加上{% csrf_token %}后就可以访问了,其要加载form表单中
使用了csrf检查就会在生成cookies时生成一个

这样就应对了不同网页只能或密码2的恶意请求
如果想一些url访问时不要被csrf检查,也可以在不更改网页源代码的基础上,在视图函数中进行包的使用
from django.views.decorators.csrf import csrf_exempt
@csrf_exempt # 加上过滤器即可,使用前要导入相应的包
def my_views(request):
return render(request,'my_views.html')
分页
web在有很多数据时,一张页面无法显示全部的数据,将数据分到不同的页面当中去。这样有减少了数据提取量,降低了服务器的压力,且易于阅读。
Django提供了Paginator类可以方便实现分页的功能
Paginator类位于django.core.paginator模块中
Paginator对象
负责分页数据整体的管理
对象的构造方法
paginator = Paginator(object_list,per_page)
object_list:需要分页数据的对象列表
per_page:每一页显示的数据的个数
返回值:Paginator对象
Paginator属性
count:需要分页的对象的总数
num_pages:分页后的页面总数
page_range:从1开始的range对象。用于记录当前页码数
per_page:每页数据的个数
Paginator方法
.page(number):
参数:number为页码信息
返回当前number页对应的页信息
如果当前number页码不存在,抛出InvalidPage异常
InvalidPage异常:-PageNotAnInterger:当向page中传入的数据不是一个整数值的时候就抛出
-EmptyPage:当向page提供的值,该页面没有任何对象时抛出
Page对象方法
has_ next(): 如果有下一页返回True
has_ previous(): 如果有.上一页返回True
has_ other_pages():如果有上一页或下一页返回True
next_ page_ number(): 返回下一页的页码,如果下一页不存在,拋出InvalidPage异常
previous_ page_ number():返回上一页的页码,如果. 上一页不存在抛出 InvalidPage异常
def text_page(request):
page_number = request.GET.get('page',1)
all_data = ['a','b','c','d','e']
paginator = Paginator(all_data,2)
c_page = paginator.page(int(page_number))
return render(request,'text_page.html',locals())
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>分页</title>
</head>
<body>
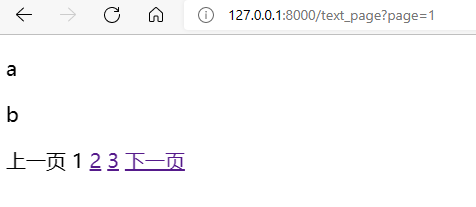
{% for p in c_page %}
<p>
{{ p }}
</p>
{% endfor %}
{% if c_page.has_previous %}
<a href="/text_page?page={{ c_page.previous_page_number }}">上一页</a>
{% else %}
上一页
{% endif %}
{% for p_num in paginator.page_range %}
{% if p_num == c_page.number %}
{{ p_num }}
{% else %}
<a href="/text_page?page={{ p_num }}">{{ p_num }}</a>
{% endif %}
{% endfor %}
{% if c_page.has_next %}
<a href="/text_page?page={{ c_page.next_page_number }}">下一页</a>
{% else %}
下一页
{% endif %}
</body>
</html>
CSV文件下载
在网页中可以下载csv文件
def make_csv(request):
response = HttpResponse(content_type='text/csv') # 初始化HttpResponse对象时可以传递参数,更改请求头,设置为text/csv
response['Content-Disposition'] = 'attachment;filename="book.csv"'# 设置请求头中的Content-Disposition为attachment;filename为指定的文件名
all_book = Book.objects.all()# 获取数据库中的所有书籍
writer = csv.writer(response)# 可以直接将response创建为csv写入对象
writer.writerow(['id','title'])# 第一行写入标题
for b in all_book:
writer.writerow([b.id,b.title])# 接下来每一行写入对应书籍的信息
return response
配置路由后访问页面就会弹出一个另存为页面框,点击另存为就可以将文件进行下载
下载之后就是数据库中各条数据
将数据库导入到页面中,并提供下载的超链接
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>分页</title>
</head>
<body>
{% for p in c_page %}
<p>
{{ p.id }}.{{ p.title }}
</p>
{% endfor %}
{% if c_page.has_previous %}
<a href="text_page?page={{ c_page.previous_page_number }}">上一页</a>
{% else %}
上一页
{% endif %}
{% for p_num in paginator.page_range %}
{% if p_num == c_page.number %}
{{ p_num }}
{% else %}
<a href="text_page?page={{ p_num }}">{{ p_num }}</a>
{% endif %}
{% endfor %}
{% if c_page.has_next %}
<a href="text_page?page={{ c_page.next_page_number }}">下一页</a>
{% else %}
下一页
{% endif %}
<p>
<a href="make_page_csv?page={{ page_number }}">下载csv</a>
</p>
</body>
</html>
def text_page(request):
page_number = request.GET.get('page', 1)
all_data = Book.objects.all()
paginator = Paginator(all_data, 2)
c_page = paginator.page(int(page_number))
return render(request, 'make_page_csv.html', locals())
def make_page_csv(request):
page_number = request.GET.get('page', 1)
all_data = Book.objects.all()
paginator = Paginator(all_data, 2)
c_page = paginator.page(int(page_number))
response = HttpResponse(content_type='text/csv')
response['Content-Disposition'] = 'attachment;filename="{}.csv"'.format(page_number)
write = csv.writer(response)
write.writerow(['id', 'title'])
for i in c_page:
write.writerow([i.id, i.title])
return response

内建用户系统
数据库中含有用户的表auth_user,存储的就是用户的信息
基本字段
模型类位置
from django.contrib.auth,models import User
username,password,email,first_name,last_name
is_superuser:是否为账号管理员
is_staff:是否可用访问admin管理界面
is_active:是否是活跃用户,默认为True,一般不删除用户,而是将
is_active设置为False
last_login:上一次登录时间 date_joined:用户创建时间
创建普通用户
from django.contrib.auth.models import User
user = User.objects.create_user(username='用户名',password='密码',email='邮箱'...)
创建超级用户
from django.contrib.auth.models import User
user = User.objects.create_superuser(username='用户名',password='密码',email='邮箱'...)
删除用户
from django.contrib.auth,models import User
try:
user = User.objects.get(username='用户名')
user.is_active = False
user.save()
except:
print('ERROR')
修改密码
from django.contrib.auth.models import User
try:
user = User.objects.get(username='用户名')
user.set_password('...')# 密码会转成hash值
user.save()
except:
print("ERROR")
校验密码
from django.contrib.auth import authenticate
user = authenticate(username=username,password=password)
# 用户名密码校验正确返回user对象,否则返回None
保持登录状态
from django.contrib.auth import login
def login_view(request):
user = authenticate(username=username,password=password)#确保用户名和密码的正确
login(request,user)
from django.contrib.auth.decorators improt login_required
@login_required
def index_view(request):
#该视图庇护为用户登录状态下才可以访问
#当前登录用户可通过request.user获取
login_user = request.user
...
登录状态的取消
from django.contrib.auth import logout
def logout_view(request):
logout(request)
基本字段不够用?创建自定义字段
继承内建的抽象user模型类
步骤:
1.添加新应用
2.定义模型类,继承AbstractUser
3.settings.py中知名AUTH——USER_MODEL = ‘应用名.类名’
此操作要在第一次migrate之前进行
如下应用
from django.db import models
from django.contrib.auth.models import AbstractUser
# Create your models here.
class User(AbstractUser):# 以前是继承models.Model
phone = models.CharField('电话',max_length=30)
在settings文件中添加AUTH_USER_MODEL = 'BOOK.User'变量
这样在创建变量的时候就可以自己定义的字段了
文件上传
前端[HTML]
以POST方式提交,表单form中文件上传是必须带有ebctype='mulripart/form-data’是才会包含文件内容数据
表单中用<input type="file" name='xxx'>标签上传文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>上传文件</title>
</head>
<body>
<form action="text_upload" enctype="multipart/form-data" method="post">
请输入要上传的文件的名称<input type="text" name="title">
<input type="file" name="jpg">
<input type="submit" value="上传">
</form>
</body>
</html>
后端
在视图函数中用request.FILES取文件框中的内容
file = request.FILES[‘xxx’]
说明:
1.FILES的key对应页面中fuke框的neame值
2.file是绑定文件流对象
3.file.name 文件名
4.file.file 文件的字节流数据
配置文件的访问路径和存储路径
在setting中在MEDIA相关配置;Django把用户上传的文件统称为media资源
MEDIA_URL = '/media/'# 表示什么样的请求是加载上传文件的请求
MEDIA_ROOT = os.path.join(BASE_DIR,'media')# 上传文件的保存路径
然后再项目的子文件夹中创建一个名叫media的文件夹
MEDIA_URL
MEDIA_ROOT 两者需要手动绑定
步骤:
...
from django.conf import settings
from django.conf.urls.static import static
...
urlpatterns += static(settings.MEDIA_URL,document_root=settings.MEDIA_ROOT)
将文件上传到本地
重写写一个模型
class Content(models.Model):
title = models.CharField('文章标题', max_length=30)
picture = models.FileField(upload_to='picture') # 将文件生成到Midea文件夹下的picture子文件夹中
def text_upload(request):
if request.method == "GET":
return render(request, 'text_upload.html')
elif request.method == "POST":
title = request.POST['title']
file = request.FILES['jpg']
Content.objects.create(title=title,picture=file)
return HttpResponse('上传文件成功')
在网页中上传文件之后,就会在midea文件夹中存在一个picture的子文件夹,里面存放的就是我们刚刚上传的文件

就可以根据之前在setting中设置的网址来访问保存的图片















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









