






又有好玩的东西了,阿里开源的ACE++,感觉可以引流未来新趋势,来看看吧。
0****1
ACE++介绍
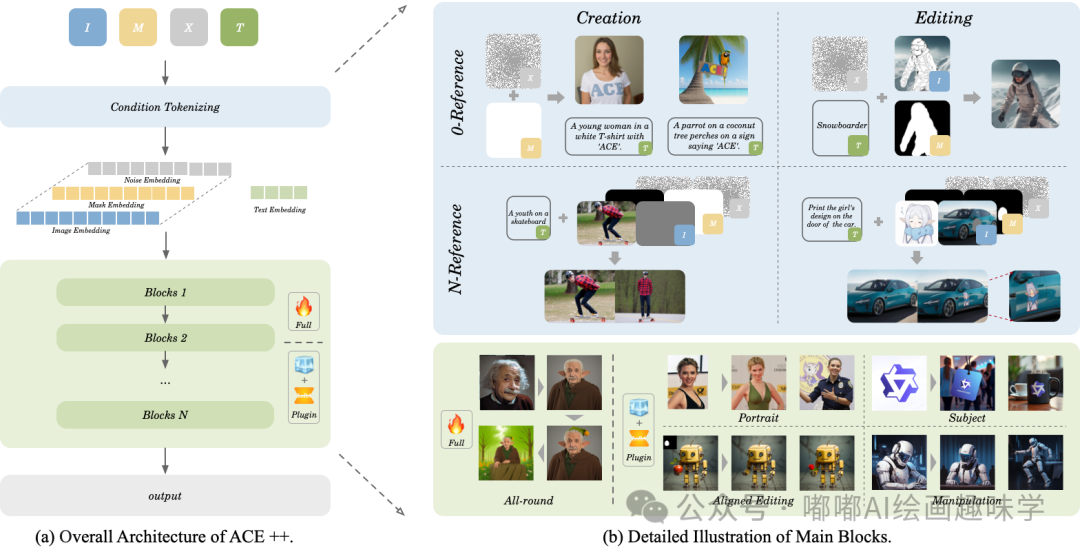
今天分享一个很令人兴奋的新工具,ACE++,这是阿里新开源的基于指令的图像创建和编辑通过上下文感知的内容填充。结合了FLUX.1-Fill-dev技术,仅需一张输入图像即可生成与角色一致的新图像,无需进行任何训练。
功能上体验下来有点类似以前那个in-Content lora,又有点像Redux,但是这个主要通过提示词来控制,符合未来发展方向。
简单来说,ACE++就像一个能听懂文字指令的"AI画师",你告诉它要画什么或者怎么修改图片,它就能按照你的要求生成或编辑图像。这个技术是基于目前最先进的"扩散模型"(可以理解为一种逐步添加细节的绘画方式)开发的。
它最大的特点就是"全能"——不管是凭空生成新图片,还是给老照片修图(比如去掉路人、换个背景、换个脸),甚至处理多步骤的复杂编辑任务,都能通过统一的指令系统完成。这得益于他们改进了一个叫"长上下文条件单元"(LCU)的核心模块,让AI能同时处理更多类型的信息。
开发团队用了两步训练法来提升效率:
1.基础学习阶段:先用现成的绘画模型(比如专门修复图片的FLUX.1-Fill-dev)打基础,就像让AI先临摹大师作品掌握基本功。
2.专项提升阶段:然后让AI学习各种具体的图片处理技巧,比如图层编辑、参考图生成等,就像让画家学习不同画派的技法。
实际效果上,ACE++生成的图片不仅质量更高,而且对文字指令的理解更精准。比如你说"给照片里的天空加上彩虹",它不会随便加个彩虹,而是会考虑光线、角度等细节,让合成效果更自然。这比之前很多需要手动标注区域的修图工具智能得多。
项目主页:
https://ali-vilab.github.io/ACE_plus_page/
Github:
https://github.com/ali-vilab/ACE_plus
在线体验:
https://www.modelscope.cn/studios/iic/ACE-Plus/summary
02
官方卖家秀



03
相关安装
ACE++ 是基于 Black Forest labs 的 FLUX.1-dev 系列的后期训练模型,是个lora,结合Flux Fill模型使用就可,无需安装插件。
模型下载地址:
https://huggingface.co/ali-vilab/ACE_Plus/tree/main/portrait
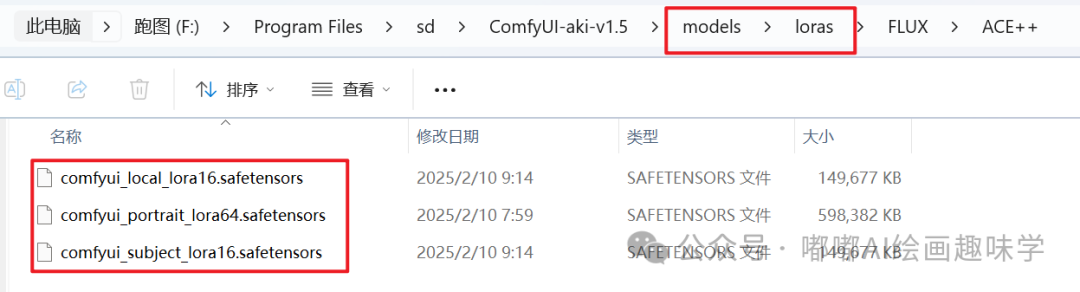
存放路径:/ComfyUI/models/loras/
模型有三类:
local_editing:comfyui_local_lora16.safetensors
portrait:comfyui_portrait_lora64.safetensors
subject:comfyui_subject_lora16.safetensors
用途简单说下:
portrait:参考肖像,直接生成另外的图
subject:本地参考编辑,可以参考一张图,融入第二张图里面
local_editing:可以用于单图做修改,添加或者消除物体
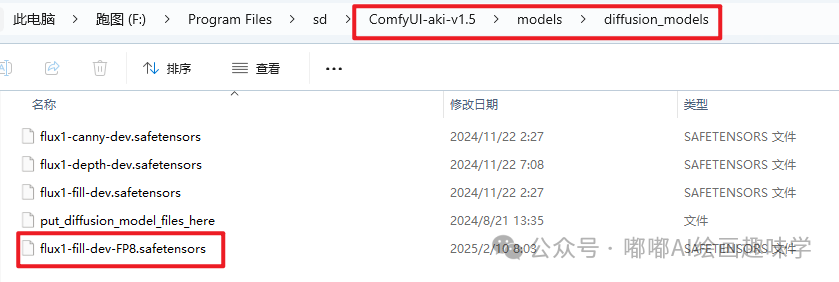
Flux-Fill用以前满配的也行,如果配置不够,推荐下载下面这个FP8模型:
https://civitai.com/models/969431/flux-fill-fp8
存放路径:
/ComfyUI/models/diffusion_models
04
使用说明
我们分三大块来测试这个ACE++
分别是:
• 主体(人像、物品)一致性
• 主体+局部遮罩一致性
• 本地图像编辑
先说个总结,测试了一早上,发现成功率有待提高,有的效果很好,有的不行,需要多次抽卡,期待未来迭代,是个大方向,下面分享三个工作流分别对应上面说的这三种。
4.1 主体(人像、物品)一致性
工作流很简单,接入Fill模型+对应lora即可,然后用图片拼凑的方式,右边生成一个全新的图
如果是人像,lora就选择
comfyui_portrait_lora64.safetensors
如果是物品,lora就选择
comfyui_subject_lora16.safetensors
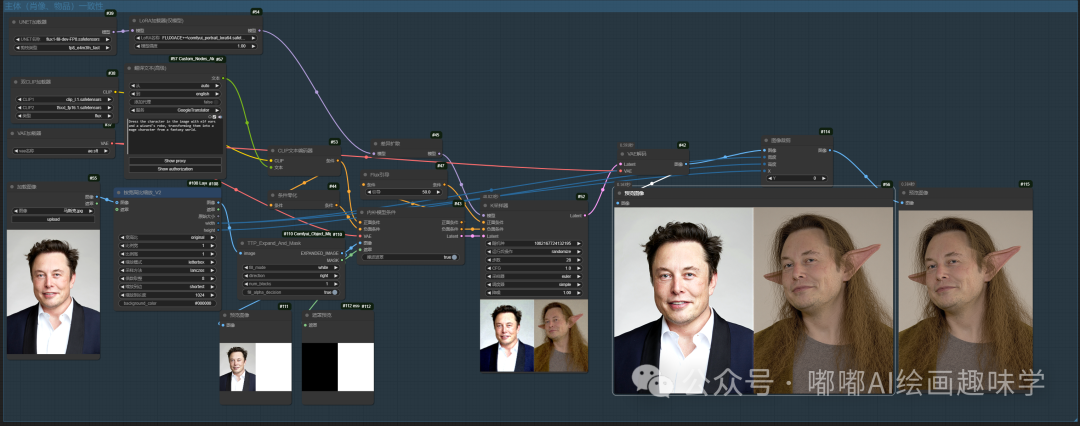
下面看两个案例,都是直接拼接后直接生成右边的图的。
下面我们看几个案例,你就知道这个工作流真的香,大道至简。
Dress the character in the image with elf ears and a wizard's robe, transforming them into a mage character from a fantasy world.

Replace the character's clothing with a Chinese traditional clothing, with an ancient teahouse in the background.

试试物体的,比如下面这件衣服,我要改下研究
衣服黑色改成蓝色,保持结构不变

再试试,这件衣服穿到身上,我抽了5次,才抽出合适的
这件黑色T恤穿在一个亚洲男性身上,背景在客厅

感觉还行,不过还是需要抽卡,我抽了挺多次的。
然后试试看,局部重绘的换脸
4.2 主体+局部遮罩一致性
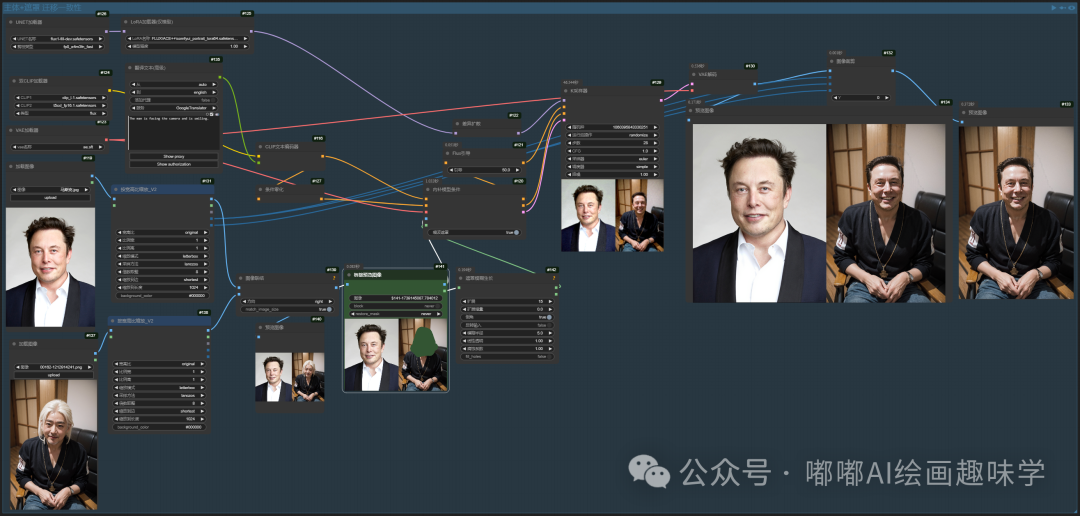
这个流和上面的唯一区别就是,合并后,涂抹要修改的区域,绿色节点桥接预览图像节点,这里先跑个图,然后右键涂抹就好。
男子正对着镜头,面带微笑,头上戴着黑色棒球帽
你发现细节了吗,这个ACE++强大的地方,不当当可以迁移面部啊,还会根据你的提示词去修改,不如这里的帽子。

马里奥在月球表面

试试服装迁移效果
这件T恤穿在男人身上,服装颜色保持一致

刚才我没写服装颜色保持一致,颜色就自动化了,生成下面这种粉色的,感觉也不错,所以这种方案提示词很重要,要说清楚,模糊不清的AI就随机发挥了。
Dress the character in the image with elf ears and a wizard's robe, transforming them into a mage character from a fantasy world.

4.3 本地图像编辑
这个是最基础的,直接单图遮罩涂抹下就可以修改了,消除物体功能不错。
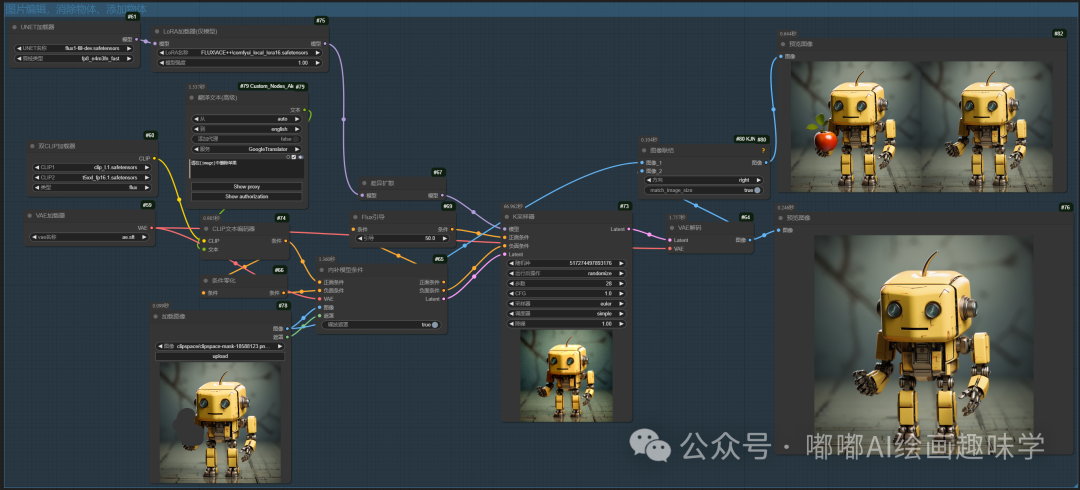
请在{image}中删除苹果

苹果这个案例测试成功
也有翻车的,按官网说的给薯条上色,我涂了遮罩,结果效果不行,和官网的不一样。
Please colorize the selected area mask in {image} without changing anything else.

05
总结
这就是今天测试的ACE++,整体感觉还不错,代表了未来发展的方向,以后就是这种,根据提示词,一句话就可以对普通做修改和迁移,很有意思的,目前的话抽卡率有待提升,目前就3个lora,期待后面完善起来。
技术的迭代是飞快的,要关注最新的消息才不会掉队。
关注我,每天分享最新的ComfyUI技术前沿。
今天介绍的基础工作流和模型我都打包好了。
工作流获取

关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









