







我们的故障中心借鉴了 K8s 的架构。

混沌工程平台 1.0 系统有一个问题:假设通过 Agent 在 K8s 里成功注入了一个延迟故障。但 K8s 本身有弹性调度能力,如果很不幸在演练过程中这个服务 crash 了,K8s 会自动在另外一个机器上把这个 Pod 启起来。这种情况下,你以为故障演练是成功的,但其实没有成功,而是重新起了新的服务。故障中心可以在容器发生漂移的时候继续注入故障。
所以我们是一套声明式的 API,声明的不是要注入什么故障,而是描述服务器的一种状态,例如 A 跟 B 之间的网络是断开的,那么在任何状态下故障中心要保证 A 和 B 是断开状态。
其次,整个系统借鉴 K8s 的架构,有丰富的 controller 支持底层不同的故障注入能力。在对业务的快速需求的支持过程中,我们在 controller 里能很快接入 Chaos Mesh、Chaos Blade 等开源项目。我们自己也原生做了一些 controller,比如 service mesh controller,agent controller,服务发现的 controller 等。
爆炸半径控制
前面提到故障中心是通过声明式 API 注入故障,我们就需要定义故障注入 model。

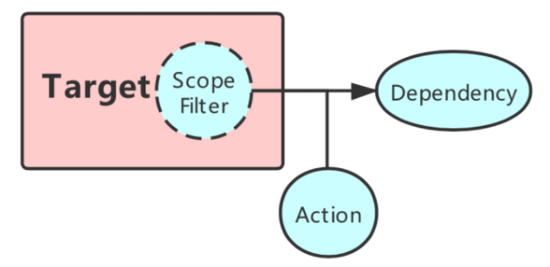
如上图所示:
-
Target:表示要注入故障的目标服务。
-
Scope Filter:对于爆炸半径控制,很重要的一点是我们希望能够让业务去帮助声明希望演练的 scope,我们称为 Scope Filter。通过 Scope Filter 能定义故障注入的目标,可以是一个机房,一个集群,一个可用区,甚至精确到实例级别乃至流量级别。
-
Dependency:它是所有可能影响服务本身的异常来源,包括中间件,某下游服务,也包括所依赖的 CPU、磁盘、网络等。
-
Action: 故障事件,即发生了何种故障,比如下游服务返回拒绝、发生丢包;又比如磁盘写异常、CPU 被抢占等。
所以在故障中心声明故障时,需要描述上述内容,表明业务希望系统中是怎样的故障状态。
稳态系统
稳态系统会涉及一些算法的工作,这里主要介绍三个算法的场景:
-
时序序列的动态分析:我们叫稳态算法,可以尝试分析服务是否稳定。其中使用了阈值检测、3 Sigma 原则、稀疏规则等算法。
-
AB 对比稳态分析:借鉴了 Netflix 在用的 曼-惠特尼 U 检验 ,大家可以看一些相关 paper 和文章介绍。
-
检测机制:使用指标波动一致性检测算法,用来分析强弱依赖。
通过以上这些算法(还有其他算法),稳态系统能够去很好地刻画系统稳定性。
自动化演练
我们将自动化演练定义为完全不需要人工干预,由系统进行故障注入,在注入过程、演变过程中分析服务的稳定性,随时止损或拿到结果。
我们现在进行自动化演练有这样一些前提:
-
能够明确演练的实际场景的目标;
-
通过稳态系统,对稳态假设具备自动化判断能力;
-
能够通过声明式 API、Scope Filter 控制混沌演练的影响范围,实验过程生产损失极小。
自动化演练目前主要的应用场景是强弱依赖分析,包括:
-
强弱依赖现状与业务标注是否一致;
-
弱依赖超时是否会拖垮整体链路。
总结
现在我们再来回顾一下,为什么我们认为混沌工程平台 2.0 版本是一个混沌工程系统。还是对比前文提到的五个原则:
-
建立一个围绕稳定状态的假说:通过稳态系统已经开启了稳态假说的演进。
-
多样化真实世界的事件:现在故障分层上更加合理,补充了大量中间件故障和底层故障。
-
在生产环境中运行试验:这一点在 1.0 时期就实现了,2.0 中进行了扩展,可支持生产环境、预发环境、本地测试环境的各种故障演习。
-
持续自动化运行试验:提供 csv、sdk、api 等能力,让业务线在自己希望的服务发布流程中持续跟功能做整合。我们也提供了 API 能力,帮助业务线在需要的环境做故障注入。
-
最小化爆炸半径:提供声明式 API 的能力,其中一个原因就是为了控制爆炸半径。
支撑底层系统演练的基础设施混沌平台
前面提到了离线服务很大程度上依赖底层状态的一致性,所以如果能把基础架构中存储、计算做好,就能够很好地支撑业务。我们用一个新的基础设施混沌平台来做一些内部的实验性尝试。
对于基础架构的混沌工程,我们要打破一下混沌工程的一些标准原则。
-
首先针对基础架构的混沌工程不太适合在生产环境演练,因为它依赖于底层的故障注入,影响面非常大,爆炸半径不好控制。
-
在自动化演练上,业务方需要更加灵活的能力,进一步跟他们的 CI/CD 打通,也需要更加复杂的编排需求。
-
对于稳态模型,除了稳定性之外,我们更关注一致性。
要支持离线环境的混沌工程,该基础设施混沌平台给了我们一个安全的环境,让我们能够在里面展开手脚做更多的故障注入,比如 CPU、Memory、File system 等系统资源故障;拒绝、丢包等网络故障;以及包括时钟跳变、进程被杀、代码级异常、文件系统级方法 error hook 在内的其他故障。
对于自动化演练的自动化编排,我们希望通过这个平台给用户更加灵活的编排能力,例如:
-
串并行任务执行
-
随时暂停 & 断点恢复
-
基础设施主从节点识别
我们也提供了一些插件能力,让一些组件团队能够更灵活地注入故障。有的业务团队可能在自己的系统里已经埋点了一些 hook,他们希望这个系统能够更直接地帮助注入故障,同时也希望复用我们的编排体系和平台体系。我们通过 hook 的方式,业务团队只需实现对应的 hook,就能够注入特定的故障,然后继续使用我们的整套编排体系和平台。

基础设施混沌平台架构图
从混沌工程到系统高可用建设
我们最开始做 Chaos Engineering 的时候,对团队的使命定位是在字节跳动落地混沌工程。但是当我们做出一些能力找业务线使用的时候,会发现业务线对此并没有什么需求。后来我们努力思考之后调整了团队的使命:通过混沌工程或者其他一些手段帮助业务推进高可用建设。调整之后我们就从过去研究 Chaos Engineering 的业界发展,变成了要去贴着业务理解业务的高可用。我们如何帮助业务进行高可用建设呢?
什么是高可用
我们用下面这个公式来进行理解高可用。

-
MTTR(Mean Time To Repair):平均修复时间
-
MTBF(Mean Time Between Failure):平均失效间隔时间
-
N:事故发生次数
-
S:影响范围
这个公式的值明显小于 1,算出来应该是所谓的三个九、五个九。要让 A 的值足够大,需要:
-
MTTR*N*S 的值足够小。所以需要降低 MTTR,降低事故发生次数,缩小故障范围。
-
MTBF 的值变大。即尽可能拉开两次故障之间的间隔。
如何降低 MTTR、N、S 呢?
降低故障影响范围(S)
小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Java工程师,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注Java)

从何学起的朋友,同时减轻大家的负担。**
[外链图片转存中…(img-ULDETHdg-1710925229807)]
[外链图片转存中…(img-FyNtcvJO-1710925229807)]
[外链图片转存中…(img-DFzY8l7q-1710925229808)]
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注Java)
[外链图片转存中…(img-qg5agUnN-1710925229808)]















 1333
1333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









