







🎈volatile关键字
如果一个字段被声明成volatile,Java线程内存模型确保所有线程看到这个变量的值是一致的。
在X86处理器下通过工具获取JIT编译器生成的汇编指令来查看对volatile进行写操作时,CPU会做什么事情
instance = new Singleton(); // instance是volatile变量
转成汇编如下:
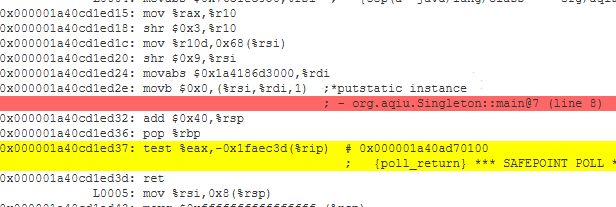
没有使用volatile时的汇编
使用volatile时的汇编
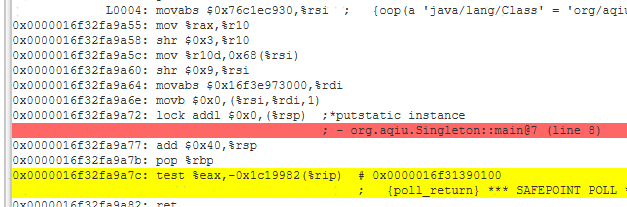
可以看到有volatile变量修饰的共享变量进行写操作的时候会多出下面这行汇编代码
lock addl $0×0,(%rsp);
// 后面的addl $0×0,(%rsp)是给这个内存地址上的值加0,这是一个没有意义的操作。
// 主要是要使用这个lock前缀
这个里面lock前缀的指令在多核处理器下会引发两件事情:
- 将当前处理器缓存行的数据写回到主内存。
- 这个写回内存的操作会使在其他CPU里缓存了该内存地址的数据无效。
具体处理流程如下,对声明volatile的变量进行写操作后,JVM就会向处理器发送一条lock前缀的指令,将这个变量所在缓存行的数据写回到系统内存。但是,就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题。所以,在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议,每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存里。
🎃内存屏障
是一种硬件指令或者软件机制,用于控制指令执行的顺序,确保在多线程或多处理器环境中,内存操作的顺序性和可见性。
现代处理器通常会为了优化性能而采用 乱序执行 和 指令重排。在多核处理器中,这种行为可能导致不同线程间的内存访问顺序不一致,进而导致错误的结果。内存屏障通过强制指令的执行顺序,确保操作按预期顺序执行。
内存屏障分类:
- 全局屏障(Full Barrier):确保屏障之前的读写操作完成后,才会执行屏障之后的读写操作。在x86架构对应的指令为
MFENCE。 - 加载屏障(Load Barrier):确保屏障之前的读操作完成后,才会执行屏障之后的读操作。在x86架构对应的指令为
LFENCE。 - 存储屏障(Store Barrier):确保屏障之前的写操作完成后,才会执行屏障之后的写操作。在x86架构对应的指令为
SFENCE。
🎁缓存行和缓存行填充
缓存行:是处理器缓存的基本存储单位,是处理器缓存和内存进行数据交换的最小单位。缓存行的大小根据处理器架构而定,一般为64字节。
缓存行填充:缓存行填充是为了避免缓存行中出现多个线程或多个数据结构之间的缓存行竞争问题,从而提高并发性能的一种优化技术。
- 为什么需要缓存行填充?
在多核或多线程系统中,可能出现两个线程修改同一个缓存行中的不同部分,每次缓存行中的数据被修改时,处理器会将整个缓存行从核心的缓存中刷新到主内存,同时加载到其他核心的缓存中。从而增加了总线带宽的消耗和缓存失效的开销,严重时会影响程序性能。
缓存伪共享是指多个核心在多核处理器中访问不同的变量,但这些变量由于被分配到同一个缓存行中,导致频繁的缓存失效和数据同步,进而影响程序性能。虽然这些变量实际不共享数据,但由于位于同一缓存行,处理器会频繁更新整个缓存行,造成不必要的性能开销。
- 如何使用缓存行填充?
缓存行填充通过在数据结构的成员变量之间添加额外的填充字节,使得每个线程访问的数据不会落在同一个缓存行中。这样,线程访问的内存位置就可以避免缓存行的重叠,从而减少缓存一致性相关的性能损失。
👓缓存一致性协议
是由硬件(通常是处理器和总线系统)来保证的,协议确保多个处理器的缓存之间的数据始终保持一致。最广泛使用的缓存一致性协议是MESI协议。
MESI 协议:
MESI(Modified, Exclusive, Shared, Invalid)定义了缓存中数据的四种状态:
- Modified (M):缓存中保存的数据已经被修改,并且该数据是唯一的副本。此时,缓存中的数据与主内存中的数据不一致。
- Exclusive (E):缓存中保存的数据是唯一的副本,并且该数据与主内存中的数据一致。此时该缓存副本没有被其他处理器缓存。
- Shared (S):缓存中保存的数据是共享的副本,多个处理器可以有相同的数据副本,且该数据与主内存中的数据一致。
- Invalid (I):缓存中保存的数据无效,即该数据不再可靠,需要从主内存或其他缓存中重新加载。
MESI 协议工作流程:
- 从
I到E(缓存行独占状态):- 当处理器从主内存加载数据并且其他缓存中没有该数据副本时,缓存行进入 E 状态。
- 从
E到M(缓存行修改状态):- 当处理器修改缓存行中的数据时,缓存行从 E 状态转为 M 状态。
- 从
E到S(缓存行共享状态):- 如果其他处理器也请求该数据进行读取,那么当前处理器的缓存行会从 E 状态转变为 S 状态,表示该缓存行被多个处理器共享。
- 从
S到M(缓存行修改状态):- 如果处理器修改共享缓存行中的数据,它会通过总线广播一个消息通知其他处理器和缓存,使它们知道该数据已经被修改,其他处理器如果缓存了相同的地址,就会将其缓存标记为 I 状态,而该处理器的缓存行会转为 M 状态。
- 从
S或M到I(缓存行失效状态):- 如果处理器检测到其他处理器对缓存行进行了修改(例如,其他处理器发出了写入总线),该处理器的缓存会将该缓存行的状态变为 I,即缓存行失效。
- 从
M到I(缓存行失效状态):- 如果其他处理器发出了修改缓存行的写请求(例如,写入请求),当前处理器的缓存中的该行数据会失效,并转变为 I 状态。
如果一个处理器读取的缓存行状态是 I 状态,该处理器将被要求从主内存或者其他缓存中获取更新的数据。
🛒volatile使用时优化点
并发包里新增一个队列集合类LinkedTransferQueue,它在使用volatile变量时,用一种追加字节的方式来优化队列出队和入队的性能。LinkedTransferQueue的代码如下
/** 队列中的头部节点 */
private transient final PaddedAtomicReference<QNode> head;
/** 队列中的尾部节点 */
private transient final PaddedAtomicReference<QNode> tail;
static final class PaddedAtomicReference <T> extends AtomicReference T> {
// 使用很多4个字节的引用追加到64个字节
Object p0, p1, p2, p3, p4, p5, p6, p7, p8, p9, pa, pb, pc, pd, pe;
PaddedAtomicReference(T r) {
super(r);
}
}
public class AtomicReference <V> implements java.io.Serializable {
private volatile V value;
// 省略其他代码
}
因为对于英特尔酷睿i7、酷睿、Atom和NetBurst,以及Core Solo和Pentium M处理器的L1、L2或L3缓存的高速缓存行是64个字节宽,不支持部分填充缓存行,这意味着,如果队列的头节点和尾节点都不足64字节的话,处理器会将它们都读到同一个高速缓存行中,在多处理器下每个处理器都会缓存同样的头、尾节点,当一个处理器试图修改头节点时,会将整个缓存行锁定,那么在缓存一致性机制的作用下,会导致其他处理器不能访问自己高速缓存中的尾节点,而队列的入队和出队操作则需要不停修改头节点和尾节点,所以在多处理器的情况下将会严重影响到队列的入队和出队效率。Doug lea使用追加到64字节的方式来填满高速缓冲区的缓存行,避免头节点和尾节点加载到同一个缓存行,使头、尾节点在修改时不会互相锁定。
那么是不是在使用volatile变量时都应该追加到64字节呢?
不是的。在以下两种场景不应该使用这种方式。
- 缓存行非64字节宽的处理器。如P6系列和奔腾处理器,它们的L1和L2高速缓存行是32个字节宽。
- 共享变量不会被频繁地写。因为使用追加字节的方式需要处理器读取更多的字节到高速缓冲区,这本身就会带来一定的性能消耗,如果共享变量不被频繁写的话,锁的几率也非常小,就没必要通过追加字节的方式来避免相互锁定
🦺懒汉模式中为什么要加volatile
1.可见性原因:如果不加,两个线程进来,都从主内存读取到INSATNCE为null存到本地内存,然后都在本地内存创建了一个实例。
2.有序性原因:
假设实例化过程为如下,那么在重排下,可能执行顺序有1-2-3变为1-3-2。
1 memory = allocate() //分配内存
2 ctorInstanc(memory) //初始化对象
3 instance = memory //设置instance指向刚分配的地址
在多线程模式下,线程A获取到锁之后,进行第二个判断,然后实例化,由于重排可能先做了第1、3行,把instance指向一个地址,此时另外一个线程B进来,做第一个非空判断时,认为此时已经创建好了实例,但是返回的是一个未初始化的对象。

















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









