






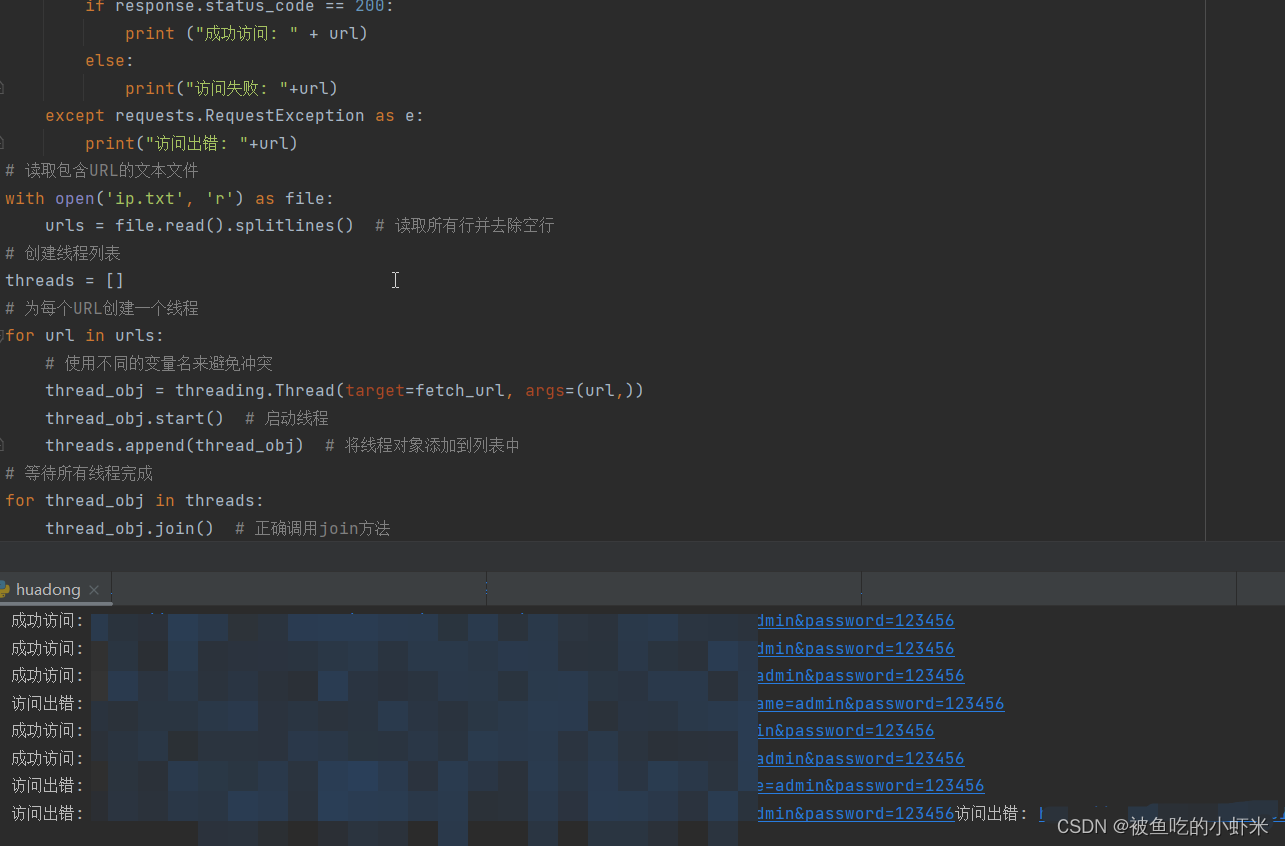
#coding=utf-8
import urllib2
import threading
import requests
# 定义一个函数,用于在线程中执行
def fetch_url(url):
try:
url = url + '/****?username=admin&password=123456'
response = requests.get(url,timeout=3)
if response.status_code == 200:
print ("成功访问: " + url)
else:
print("访问失败: "+url)
except requests.RequestException as e:
print("访问出错: "+url)
# 读取包含URL的文本文件
with open('ip.txt', 'r') as file:
urls = file.read().splitlines() # 读取所有行并去除空行
# 创建线程列表
threads = []
# 为每个URL创建一个线程
for url in urls:
# 使用不同的变量名来避免冲突
thread_obj = threading.Thread(target=fetch_url, args=(url,))
thread_obj.start() # 启动线程
threads.append(thread_obj) # 将线程对象添加到列表中
# 等待所有线程完成
for thread_obj in threads:
thread_obj.join() # 正确调用join方法
print("所有URL访问完毕")
简单写一个多线程的get 脚本,如果需要post的,这个之间改一点东西就行。















 911
911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









