





 研究者使用大语言模型修复代码漏洞,比较了模型性能、上下文影响及现实挑战。模型在合成场景中表现良好,但在真实世界修复中面临困难,提示工程和模型设置对结果至关重要。
研究者使用大语言模型修复代码漏洞,比较了模型性能、上下文影响及现实挑战。模型在合成场景中表现良好,但在真实世界修复中面临困难,提示工程和模型设置对结果至关重要。
Examining Zero-Shot Vulnerability Repair with Large Language Models
2023 IEEE Symposium on Security and Privacy (SP)
Cryptography and Security (cs.CR); Artificial Intelligence (cs.AI)
摘要
研究代码大模型在漏洞修复的应用,设计提示信息使LLM生成不安全代码的修复版本,对五种现有黑盒大模型、一个开源模型以及本地训练模型,针对合成、人工生成和现实世界的安全漏洞场景进行了大规模研究。
介绍
现有的代码修复有静态分析、模糊测试等,也有基于CNN机器翻译的修复软件缺陷模型,本文将探索以下四个问题:
- 现成的LLM能否生成安全且功能强大的代码来修复安全漏洞?
- 改变提示注释中的上下文数量是否会影响LLM修复的能力?
- 在现实世界中使用LLM修复漏洞时面临的挑战是什么?
- LLM在修复代码的可靠性如何?
本文贡献如下:
- 比较了不同上下文提示和模型设置,使LLM生成功能性和安全的代码
- 第一个对零样本安全修复的LLM进行了评估,表明现有模型能够在没有任何额外在简单场景中的训练来生成安全修复代码
- 然而,在真实世界的场景评估LLM时,它们可能很难生成合理的修复,为鼓励未来在真实世界代码的修复工作,他们开源了数据集和评估框架
模型设置:
-
温度:模型选择不太可能的令牌的倾向
-
top_p:仅考虑累积概率p以下的token
-
length:生成多少tokens
-
停止字
模型
现有LLM:OpenAI的Codex模型、AI21的Jurasci-1模型,这些“现成的”模型是在大量开源软件代码上训练的,且都是黑盒的,它们的架构、权重、输入输出层等信息对用户是不透明的,都是通过互联网的API访问。
本地模型:polycoder和gpt2-csrc,参数分别为27亿和7.74亿
从提示到提示工程
到目前为止,提示工程还处于萌芽阶段,先前工作表明,Github的Copilot输出中的安全代码缺陷对提示很敏感,如何设置提示以获得最佳效果,特别是当训练数据特征不确切时,是一个待解决的问题。
由于模型的输入长度限制,当源文件足够小,可以输入整个代码作为提示,但文件比较大,需要明智的选择部分代码组装成提示,如果想获得特定的推荐,还需要修改提示,例如在用户需要帮助的地方父进添加注释。
考虑LLM文档、用户指南中的建议,提示应该以注释、数据或者代码开头,并包含对“程序员…执行任务”可能有帮助的信息,这些元素可能表现出不同风格,例如观察到github项目中存在BUG或者FIXED的注释,将它们作为提示的潜在元素,作为bug修复过程的一部分,注释掉的代码经常出现在提交当中。
R1/R2
- 现成的LLM能否生成安全且功能强大的代码来修复安全漏洞?
- 改变提示注释中的上下文数量是否会影响LLM修复的能力?
Overview
为了衡量LLM能多大程度修复漏洞,生成大量错误程序合集,并尝试适用不同参数的Codex LLM修复这些程序。
第一阶段是寻找参数是的LLM修复代码性能良好,第二阶段调查提示,不同提示是否会影响LLM生成代码的质量。
框架如下,使用现成安全工具判断代码是否有bug,如果有,则定位bug的位置,并且将源代码和bug报告合成为提示,大模型接受提示后产生修复代码,使用外部工具和回归测试评估LLM的建议是否修复了原始程序。
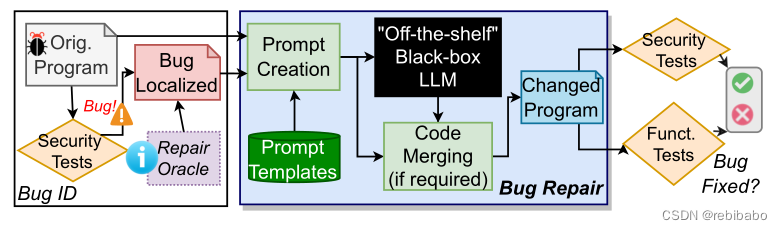
漏洞程序生成
检查模型参数对生成代码的影响,将1)搜索bug的类型,2)提示文本 保持一致,需要许多相同bug的样例,借鉴了先前的工作(证明LLM生成易受攻击代码的倾向),使用OpenAI的Codex生成易受攻击的代码。CWE选择了越界写入(MITRE的前25名中排第一)和CWE-89:SQL注入(排第六),这些是高影响的bug,且不需要任何额外的上下文。
为了生成大量独特但相似的漏洞程序,指定1)短程序前面一部分与这些CWE相关,2)用目标LLM生成漏洞程序,3)通过单元测试和CodeQL运行这些程序评估这些程序的功能和安全正确性,4)将一组功能独特但易受攻击的程序作为修复错误的数据集。
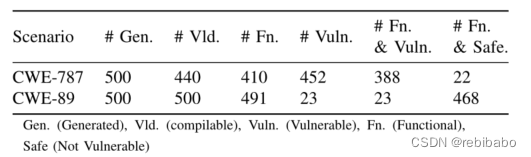
漏洞程序修复
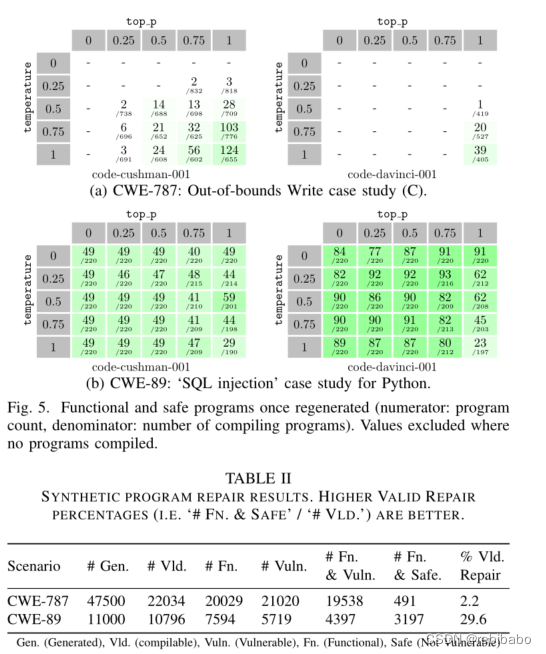
上面具有功能性和漏洞的程序,利用CodeQL静态分析工具识别漏洞代码,漏洞报告和代码作为提示,每一个漏洞程序都是使用相同的提示,确定模型最佳的top_p和温度。
例如CWE-787的原始代码为左侧(a)图,将两个double类型的数相乘然后以字符串形式返回,右边是提示,有注释掉的Codex生成的漏洞代码,还要漏洞报告BUG、MESSAGE,最后加上FIXED VERSION为待修复的版本,使用这个提示查询LLM,在温度和top_p上进行扫描,根据不同温度和top_p得到所有的查询。

结果如下,上图5为不同top_p、温度、CWE的修复情况,分子为修复数,分母为编译通过数,表II的Vld为修复率,两个漏洞修复率分别为2.2%、29.6%,注意到CWE-787的性能随着top_p增大而增大,随着温度升高而提升,但是CWE-89却反过来了,结论是没有一个温度、top_p能最好地覆盖所有场景
提示工程和人工生成漏洞程序
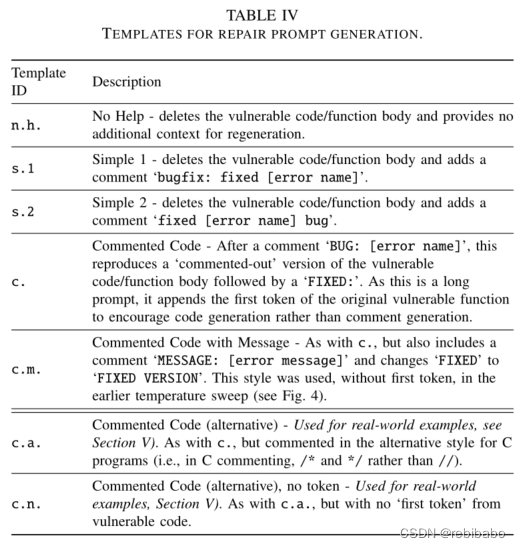
尝试增加提示多样性(增加或减少注释中的上下文的量),并且扩充到更多场景,人工编写MITRE前25的安全漏洞程序,并扩展了更多的LLM模型。
下表为提示的模板
下面展示了一部分漏洞的结果
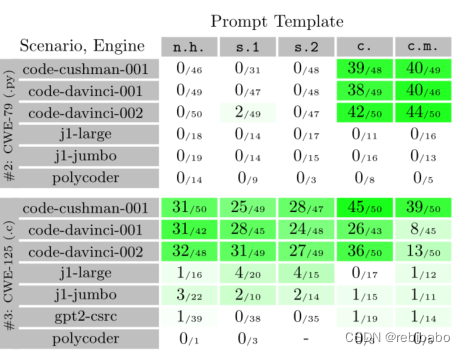
不同提示、场景和LLM之间的性能差异很大,每个单独模板的性能可以指导未来的工作,以制作健壮的通用单一提示(RQ2),例如低上下文模板和高上下文模板会对修复率有影响,是否提供注释掉的原始BUG代码会对功能性有影响,如果不提供可能没有办法获得正确的输出。作者指出,提供的额外技术细节有助于LLM生成代码,以通过更困难场景的安全和功能测试,更有力的提示应该包括更多的细节,而不是更少。
R3
在现实世界中使用LLM修复漏洞时面临的挑战是什么?
允许我们为更大、更现实的软件项目描述LLM性能,但我们不能再在源文件中为LLM提供“完整”上下文,真正的程序往往比这些模型所能接受的要多得多,必须引入一个预生成缩减步骤,以使提示符合令牌限制。
选取数据集考虑的依据:1)是否能找到触发漏洞行,2)开发人员提供的补丁是否本地化为了单个文件(现有语言模型通常不同考虑多个文件的上下文),3)该项目是否有一个全面的测试套件
生成漏洞项目的过程:1)识别修复漏洞的补丁,2)找到上级提交,即有漏洞的版本,3)找到触发漏洞行,4)确定如果对项目进行回归测试,确保修复不会破坏其他功能。
使用开发人员提供高的补丁定位漏洞,促使LLM在缺陷位置生成修复程序,识别漏洞和修复漏洞正交,如果LLM能够很好修复漏洞,这两个工作可以作为自动化、完整的漏洞修复的一部分。
代码缩减和建议合并:扩展了前面的框架,在模型能够输入和输出的代码量的限制下,对提示进行缩减,首先减少提供给大语言模型的代码量同时保留足够的上下文,但至于包括什么,目前几乎没有建议,根据语言模型的用户指南,应该包括文件的defines列表,并跳到漏洞的开头;然后修剪提示的长度,先用每个模型的tokenizer评估提示长度,如果太长,就从提示顶部逐渐修剪,直到符合限制。
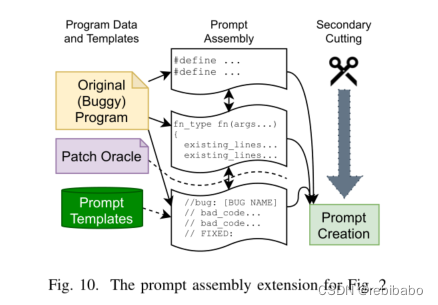
在LLM生成修复代码过后,需要将修复代码移植到项目,设计了修复代码和原始代码至少要重叠30个字符,为了鼓励这一点,增强了注释,使其至少包含2行安全代码和错误代码到注释中,如果没有找到30个重叠字符,则逐渐减少所需字符的数量,最少重叠5个字符。
下面是修复的结果,LLM能够修复8/12个选定项目,这里的成功修复的定义是:通过了每个项目的功能测试套件,并且在给出最初有问题的输入时,不再因漏洞而崩溃。
弊端:如果需要新代码,LLM对上下文的理解有限,如果补丁很长,对LLM也很麻烦,而且对于一些复杂的语义级别的修复,也更难以修复。
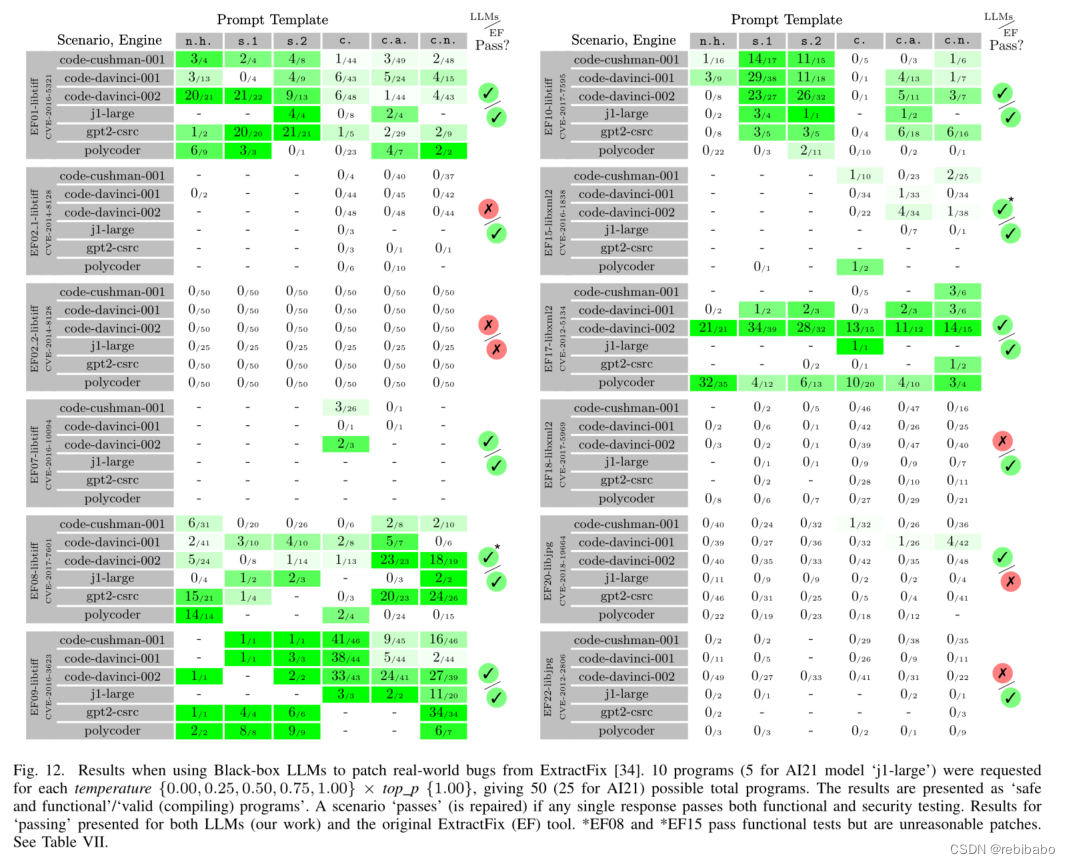
RQ4
LLM在修复代码的可靠性如何?
在两个CWE的117个简单合成程序中,LLM生成了58500个可能的补丁,其中3688个修复了它们的程序,手工制作了7个易受攻击的程序来实现7个CWE,LLM生成了10000个可能的补丁,其中2796个修复了他们的程序,使用了12个具有历史CVE的真实世界项目,并让LLM生成19600个可能的补丁,其中982个补丁“修复”了他们的程序。
,其中3688个修复了它们的程序,手工制作了7个易受攻击的程序来实现7个CWE,LLM生成了10000个可能的补丁,其中2796个修复了他们的程序,使用了12个具有历史CVE的真实世界项目,并让LLM生成19600个可能的补丁,其中982个补丁“修复”了他们的程序。
总结到:详细的提示在引导模型生成修补程序方面更有效,LLM在只需要生成简短的本地修复程序时效果最好,在需要复杂背景的情况下,他们的表现更差。LLM在合成以及人工生成的场景可靠性很好,但是对于真实世界场景,LLM还不够可靠。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









