







你是否曾经遇到过这样的情况:打开一个重要文件,却发现满屏都是乱码?或者收到一封邮件,内容却变成了一堆看不懂的符号?作为一个多年与各种文本打交道的开发者,我深知字符乱码带来的困扰。今天,我就来和大家分享一些实用的方法,帮助你轻松应对各种乱码问题。
首先,让我们来了解一下乱码产生的原因。乱码通常是由于文件编码与系统或软件的默认编码不匹配造成的。比如,一个使用UTF-8编码的文件在只支持GBK编码的系统中打开,就会出现乱码。了解这一点对于解决问题至关重要。
下面,我将介绍几种解决乱码的方法,从简单到复杂,总有一种适合你的需求。
方案一:文本乱码转码助手
这是我专门开发的一款工具,特别适合不懂技术的小白用户。它有以下优势:
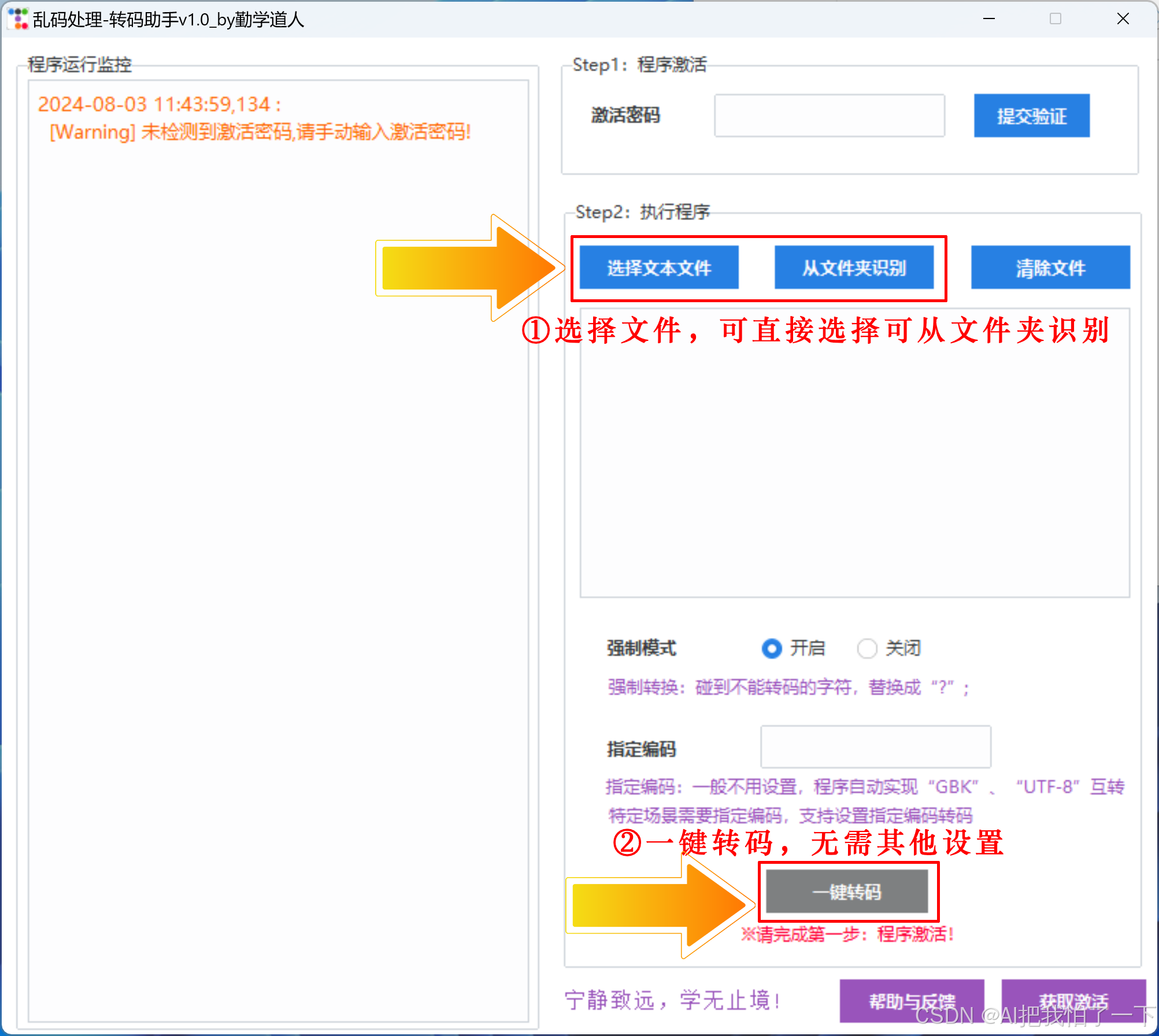
优势:
- 可视化界面,操作简单直观
- 一键自动实现GBK、UTF-8互转,无需任何设置
- 支持指定编码方式后一键转码
- 强制模式可跳过不支持转码的字符,确保转码完成
- 支持批量转码,提高效率
- 多线程高性能处理,多文件并行转码
这个工具支持转码的文件类型非常广泛,包括但不限于:
- 纯文本文件(.txt, .csv)
- 各种编程语言源代码文件(.py, .js, .java, .c, .cpp, .h, .html, .css等)
- 配置文件(.json, .yaml, .xml, .ini, .properties)
- 脚本文件(.sh, .bat, .cmd)
- 标记语言文件(.md, .tex)
- 日志文件(.log)
使用步骤非常简单:
- 打开工具
- 选择需要转码的文件
- 点击"一键转码"按钮
- 等待转码完成
想要玩一下这个工具,点点赞、点点关注找我要一下哦
视频演示:视频最后有领取方法
txt乱码解决处理文本文件转码编码csv器gbk互转utf-8自动批量工具html,js,css,md,json,log,py,xml,bat,cmd,sh
方案二:使用记事本或其他文本编辑器手动更改编码
这是一种简单直接的方法,适合处理少量文件。
优势:
- 无需安装额外软件
- 操作简单,适合临时使用
劣势:
- 只能一次处理一个文件
- 需要手动尝试不同的编码
具体步骤:
- 用记事本打开乱码文件
- 点击"文件" > "另存为"
- 在"保存类型"下拉菜单中选择"所有文件"
- 在"编码"下拉菜单中选择不同的编码(如UTF-8、ANSI等)
- 保存文件并重新打开,查看是否还有乱码
方案三:使用Python脚本批量转码
对于有一定编程基础的用户,使用Python脚本可以实现更灵活的批量转码。
优势:
- 可以批量处理大量文件
- 可以根据需求自定义处理逻辑
- 跨平台支持
劣势:
- 需要一定的编程知识
- 需要安装Python环境
以下是一个简单的Python脚本示例:
import os
import chardet
def convert_encoding(file_path, target_encoding='utf-8'):
with open(file_path, 'rb') as file:
raw_data = file.read()
result = chardet.detect(raw_data)
source_encoding = result['encoding']
if source_encoding != target_encoding:
content = raw_data.decode(source_encoding, errors='ignore')
with open(file_path, 'w', encoding=target_encoding) as file:
file.write(content)
print(f"Converted {file_path} from {source_encoding} to {target_encoding}")
else:
print(f"{file_path} is already in {target_encoding}")
def batch_convert(directory, target_encoding='utf-8'):
for root, dirs, files in os.walk(directory):
for file in files:
if file.endswith(('.txt', '.csv', '.py', '.js', '.java', '.html', '.css')):
file_path = os.path.join(root, file)
convert_encoding(file_path, target_encoding)
# 使用示例
batch_convert('/path/to/your/directory')
使用这个脚本,你只需要指定要处理的目录,它就会自动检测每个文件的编码,并将其转换为指定的目标编码(默认为UTF-8)。
在处理乱码问题时,我们还需要注意一些细节:
-
编码检测:有时候,自动检测编码可能会出错。在这种情况下,你可能需要手动指定源编码。
-
数据丢失:在某些情况下,特别是从更复杂的编码转换到更简单的编码时,可能会出现数据丢失。例如,从UTF-8转换到ASCII时,所有非ASCII字符都会丢失。
-
兼容性:某些软件或系统可能只支持特定的编码。在这种情况下,你可能需要在多个编码之间进行权衡,选择一个兼容性最好的编码。
-
备份:在进行任何编码转换之前,务必对原始文件进行备份,以防意外发生。
-
文件类型:不同类型的文件可能需要不同的处理方式。例如,二进制文件通常不应该进行编码转换。
除了以上方法,还有一些其他的技巧可以帮助你应对乱码问题:
-
使用专业的编码检测工具:像ICU(International Components for Unicode)这样的库提供了更高级的编码检测功能。
-
在线转码工具:对于不方便在本地安装软件的情况,可以使用在线转码工具。但要注意保护隐私,不要上传敏感文件。
-
使用编程语言的内置功能:很多编程语言都提供了处理不同编码的内置函数,如Python的codecs模块、Java的Charset类等。
-
制定编码规范:在团队协作中,制定统一的编码规范可以大大减少乱码问题的发生。
-
使用版本控制系统:像Git这样的版本控制系统通常会自动处理文件编码,可以减少因编码不一致导致的问题。
在日常工作中,我发现很多人对编码问题感到困惑。其实,只要掌握了正确的方法,处理乱码问题并不难。希望通过这篇文章,我能帮助大家更好地理解和解决乱码问题。
记住,预防胜于治疗。在创建新文件时,尽量使用通用的编码方式(如UTF-8),可以有效减少乱码的出现。同时,培养良好的文件管理习惯,如在文件名或元数据中注明使用的编码,也能帮助你更轻松地处理可能出现的编码问题。
最后,我想听听你们的经验。你是否曾经遇到过让你头疼的乱码问题?你是如何解决的?欢迎在评论区分享你的故事和技巧,让我们一起学习,共同进步!
想要玩一下这个工具,点点赞、点点关注找我要一下哦

















 4486
4486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









