






在之前的代码中,我们中能看到这两行代码

这两行代码的作用是创建Spring容器最终得到对象bean,但是每次测试都要重新写,我们希望程序能够自动创建容器。
junit当然无法知道我们是否使用了Spring框架,更不用说帮创建我们容器了。
Spring提供了一个运行器,可以读取配置文件(或注解)来创建容器,我们只需要告诉它配置文件的位置就可以了。
这样一来,我们通过Spring整合Junit就可以使程序创建容器了
整合Junit5
JUnit 5是Java编程语言的单元测试框架,它是JUnit框架的最新版本。JUnit是一个广泛使用的测试框架,用于编写和运行自动化的单元测试,以确保代码的质量和可靠性。
引入依赖
<!-- spring对junit的支持相关依赖 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>6.0.9</version>
</dependency>
<!-- junit5 -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<version>5.9.3</version>
</dependency>快速使用
这是我们原本创建bean的步骤
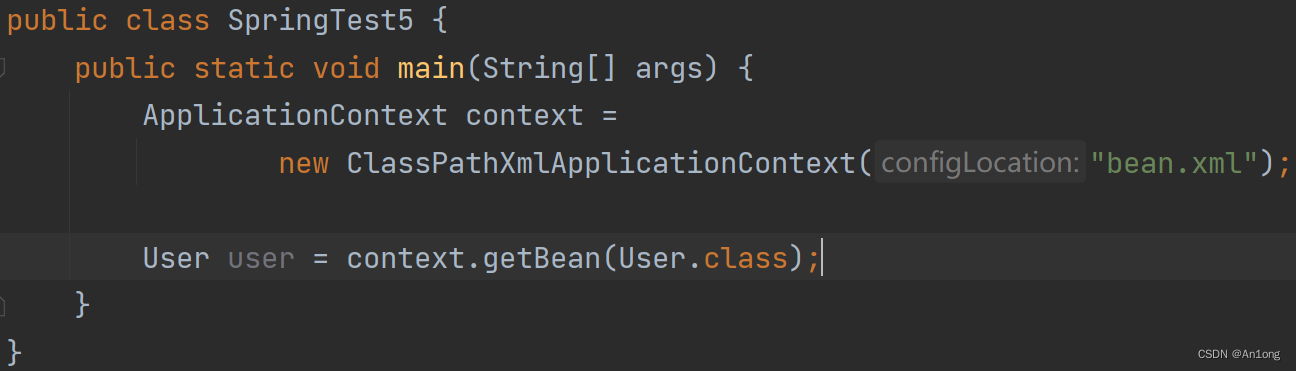
现在引入junit之后
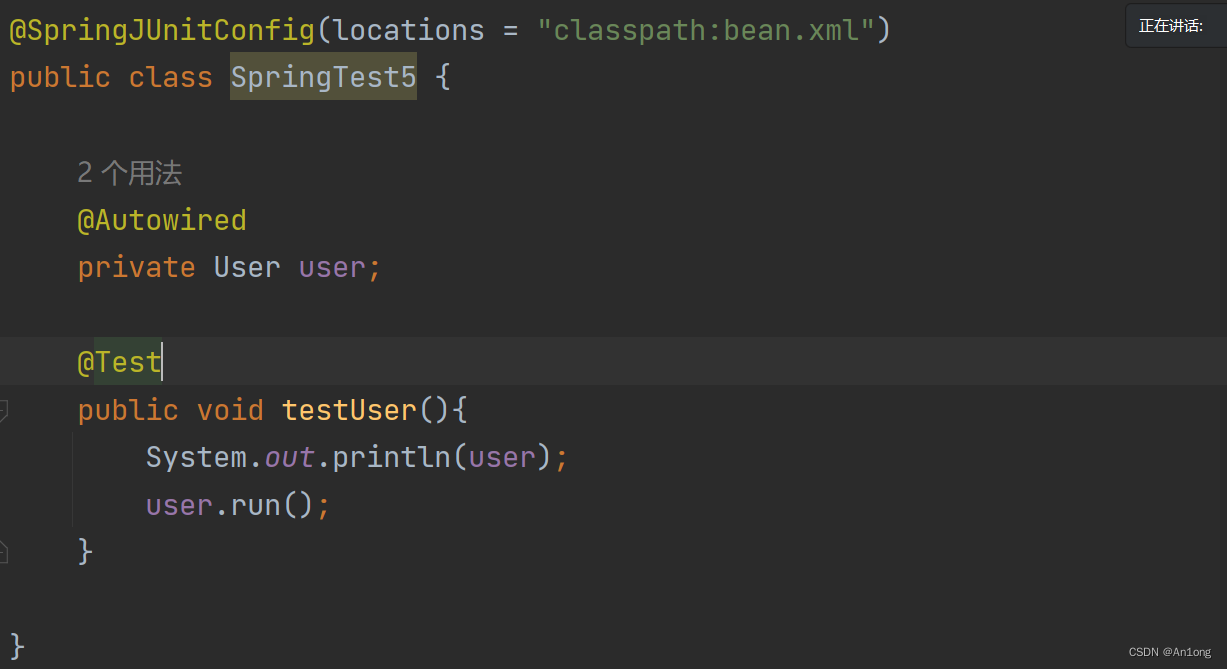
如果你使用全注解开发,spring配置是一个Java类而非xml文件,则使用

整合Junit4
JUnit 4是Java编程语言的一种单元测试框架,它是JUnit框架的一个较旧版本,但是比JUnit 5更为常见和广泛使用,所以还是有必要看一下
引入依赖
<!-- Junit4 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency> 快速使用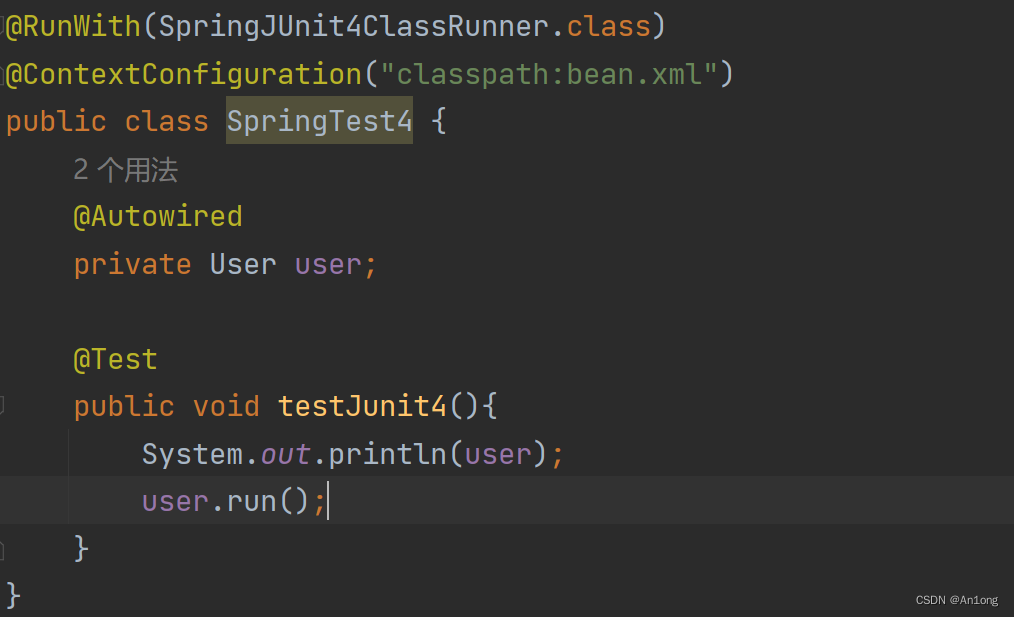
添加log4j2日志配置
Log4j是一个用于Java应用程序的广泛使用的日志记录工具。它提供了灵活的配置选项和强大的功能,使开发人员能够在应用程序中记录各种级别的日志信息。
Log4j2是Java应用程序的高性能日志记录框架,它是Log4j框架的最新版本。与Log4j 1.x相比,Log4j2提供了更高的性能、更丰富的特性和更灵活的配置选项。
使用Log4j,开发人员可以在代码中通过配置文件或编程方式指定日志记录的级别、输出目标(例如控制台、文件、数据库等)和日志格式。这使得开发人员能够更好地管理应用程序的日志信息,并根据需要进行调试、监视和故障排查。
Log4j有多个组件,其中最核心的是Logger、Appender和Layout。Logger负责记录日志消息,Appender定义了日志消息输出的目标,而Layout定义了日志消息的格式。
引入依赖
<!--log4j2日志依赖-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.20.0</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j2-impl</artifactId>
<version>2.20.0</version>
</dependency>配置文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- 引入外部数据库配置文件,如果没有就不用写-->
<properties resource="jdbc.properties"/>
<!-- 设置Mybatis的全局配置,如日志,下划线转驼峰等 -->
<settings>
<!-- 将_自动映射为驼峰 -->
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
<!-- 为类和包名起别名-->
<typeAliases>
<package name="com.wal.entity"/>
</typeAliases>
<!-- 默认使用的环境id,也就是说我们其实可以配置多套environment环境-->
<environments default="dev">
<!-- 每个environment元素定义的环境ID-->
<environment id="dev">
<!--
transactionManager 事务管理器
type的值有JDBC和MANAGED
JDBC – 这个配置直接使用了 JDBC 的提交和回滚设施,它依赖从数据源获得的连接来管理事务作用域。
-->
<transactionManager type="JDBC"/>
<!--
dataSourceDataSource 数据源 dbcp c3p0 druid
type="[UNPOOLED|POOLED|JNDI]"
POOLED意思有连接池的连接
UNPOOLED意思没有连接池的连接
-->
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<package name="com.wal.mapper"/>
<!-- <mapper resource="com.wal.mapper/userMapper.xml"/>-->
</mappers>
</configuration>
这样在控制台上就会打印日志了

Mybatis整合分页插件
分页插件pageHepler
引入依赖
<!-- 分页插件 -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.3.2</version>
</dependency>配置文件
<!-- 设置插件 -->
<plugins>
<plugin interceptor="com.github.pagehelper.PageInterceptor"/>
</plugins>测试分页
我们在sql语句中分页使用关键字limit( index , pageSize)
index:当前页的起始索引
pageSize:每页显示的条数
pageNum:当前页的页码
index = (pageNum - 1) * pageSize

查询所有员工信息
1、在查询功能之前开启分页

他会将所有的员工一次性打出来,我们此时想实现分页
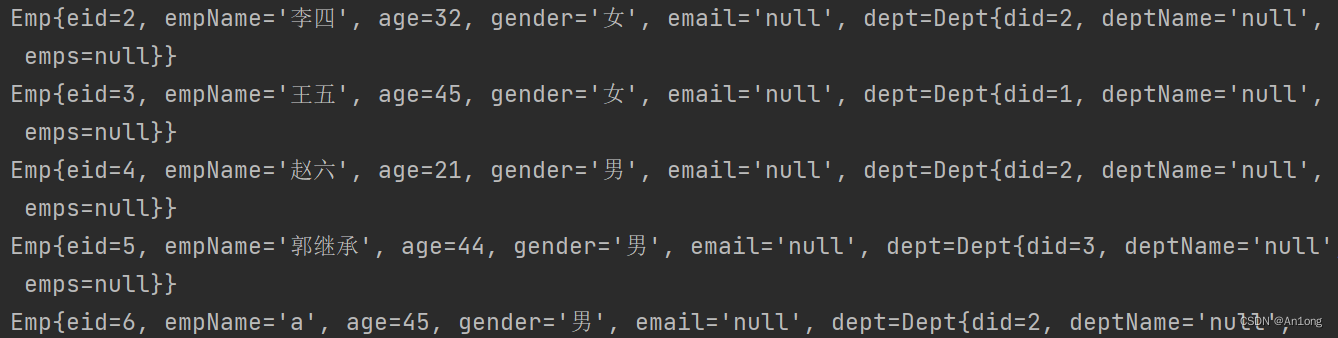
直接调用PageHelper的startPage方法
@Test
public void testGetAllEmp(){
SqlSession sqlSession = SqlSessionUtil.getSqlSession();
EmpMapper mapper = sqlSession.getMapper(EmpMapper.class);
//展示第一页,每条显示4页
PageHelper.startPage(1,4);
List<Emp> empList = mapper.getAllEmp();
empList.forEach(System.out::println);
}发现自动生成了sql的limit语句
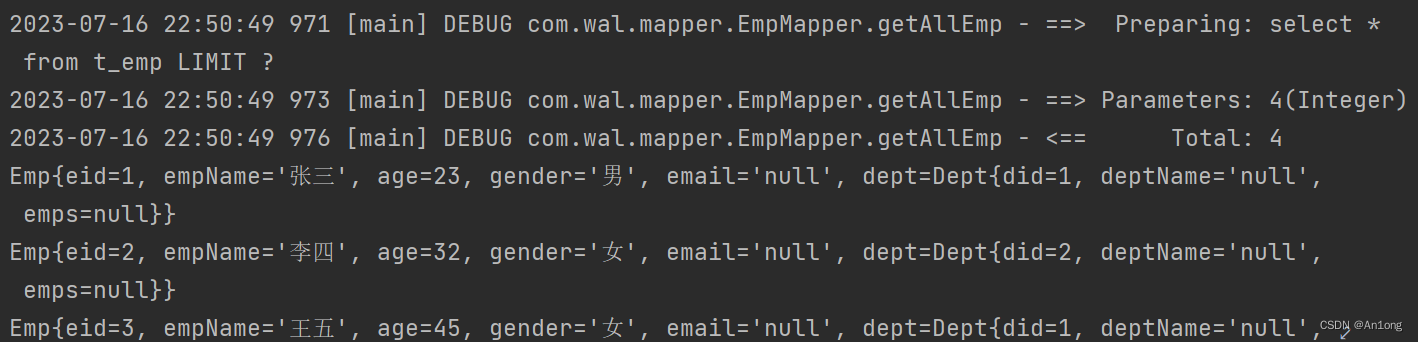
2、在查询功能之后获取分页相关信息
@Test
public void testGetAllEmp(){
SqlSession sqlSession = SqlSessionUtil.getSqlSession();
EmpMapper mapper = sqlSession.getMapper(EmpMapper.class);
List<Emp> empList = mapper.getAllEmp();
PageInfo<Emp> pageInfo = new PageInfo<>(empList,3);
System.out.println(pageInfo);
}















 1195
1195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











